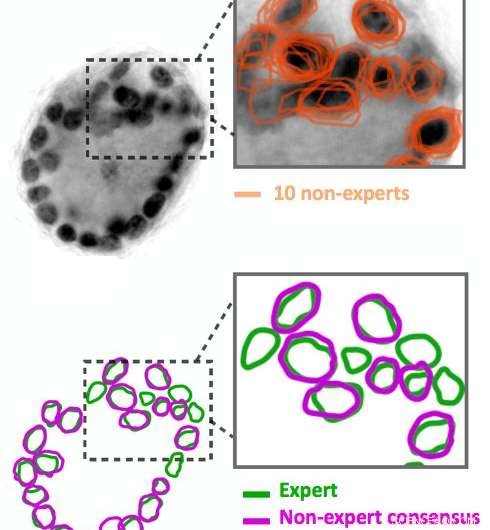
Las anotaciones de imágenes de no expertos son ruidosas. Diez no expertos delinearon los círculos negros oscuros en la imagen, que son núcleos celulares. Sus resultados (mostrados en naranja) no coinciden exactamente. Nuestros algoritmos pueden inferir un esquema de consenso (mostrado en violeta) a partir de los datos ruidosos. Compare este consenso con la anotación de expertos de la misma imagen (que se muestra en verde). Crédito:IBM
Hoy, mi equipo de IBM y mis colegas del laboratorio de UCSF Gartner informaron en Métodos de la naturaleza un enfoque innovador para generar conjuntos de datos de no expertos y usarlos para la capacitación en aprendizaje automático. Nuestro enfoque está diseñado para permitir que los sistemas de inteligencia artificial aprendan tan bien de los no expertos como de los datos de capacitación generados por expertos. Desarrollamos una plataforma, llamado Quanti.us, que permite a los no expertos analizar imágenes (una tarea común en la investigación biomédica) y crear un conjunto de datos anotado. La plataforma se complementa con un conjunto de algoritmos diseñados específicamente para interpretar correctamente este tipo de datos "ruidosos" e incompletos. Usados juntos, estas tecnologías pueden ampliar las aplicaciones del aprendizaje automático en la investigación biomédica.
No expertos y datos ruidosos
La disponibilidad limitada de conjuntos de datos anotados de alta calidad es un cuello de botella en el avance del aprendizaje automático. Mediante la creación de algoritmos que pueden ofrecer resultados precisos a partir de anotaciones de menor calidad, y un sistema para recopilar rápidamente dichos datos, podemos ayudar a aliviar el cuello de botella. Analizar imágenes en busca de características de interés es un gran ejemplo. La anotación de imágenes experta es precisa pero requiere mucho tiempo, y las técnicas de análisis automatizadas, como la segmentación basada en el contraste y la detección de bordes, funcionan bien en condiciones definidas, pero son sensibles a los cambios en la configuración experimental y pueden producir resultados poco fiables.
Ingrese al crowdsourcing. Usando Quanti.us, obtuvimos anotaciones de imágenes de fuentes colectivas entre 10 y 50 veces más rápido de lo que hubiera necesitado un solo experto para analizar las mismas imágenes. Pero, como era de esperar, Las anotaciones de los no expertos eran ruidosas:algunas identificaban correctamente una característica y otras no estaban en el objetivo. Desarrollamos algoritmos para procesar los datos ruidosos, inferir la ubicación correcta de una característica a partir de la agregación de impactos tanto dentro como fuera del objetivo. Cuando entrenamos una red de regresión convolucional profunda utilizando el conjunto de datos de fuentes múltiples, funcionó casi tan bien como una red capacitada en anotaciones de expertos, con respecto a la precisión y la memoria. Junto con el documento que describe nuestro enfoque y estrategia, publicamos el código fuente de nuestro algoritmo.
Aplicaciones en ingeniería celular
El análisis de imágenes es fundamental para muchos campos de la biología cuantitativa y la medicina. Hace unos años, nosotros y nuestros colaboradores anunciamos el Centro de Construcción Celular (CCC) financiado por NSF, un centro de ciencia y tecnología que es pionero en la nueva disciplina científica de la ingeniería celular. CCC facilita una estrecha colaboración entre expertos de diferentes disciplinas, como el aprendizaje automático, física, Ciencias de la Computación, biología celular y molecular, y genómica, para impulsar el progreso en la ingeniería celular. Nuestro objetivo es estudiar y crear células que se puedan utilizar como máquinas automatizadas, o sensores ad hoc, para aprender información nueva y vital sobre una variedad de entidades biológicas y su relación con el entorno en el que viven. Utilizamos el análisis de imágenes para identificar la posición y el tamaño de los componentes internos de la célula. Pero incluso con técnicas de imagen avanzadas, la inferencia exacta de las subestructuras celulares puede ser increíblemente ruidosa, dificultando el funcionamiento de los componentes de la celda. Nuestra técnica puede utilizar estos datos ruidosos para predecir correctamente dónde pueden estar las estructuras celulares relevantes, lo que permite una mejor identificación de los orgánulos implicados en la producción de sustancias químicas importantes o posibles dianas farmacológicas en una enfermedad.
Creemos que nuestros algoritmos son un primer paso importante hacia plataformas de IA más complejas. Estos sistemas pueden utilizar paradigmas adicionales de "humanos en el ciclo", Involucrando a un biólogo para corregir errores durante la fase de entrenamiento, por ejemplo, para mejorar aún más el rendimiento. También vemos una oportunidad para aplicar nuestro método más allá de la biología a otros campos donde los conjuntos de datos anotados de alta calidad pueden ser escasos.
Esta historia se vuelve a publicar por cortesía de IBM Research. Lea la historia original aquí.














