Las predicciones de sonidos se lograron mediante un método mejorado desarrollado por un equipo internacional de investigadores. Crédito: IEEE / CAA Journal of Automatica Sinica
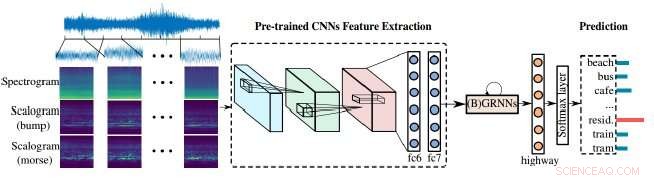
Los investigadores han demostrado un método mejorado para que las máquinas de análisis de audio procesen nuestro mundo ruidoso. Su enfoque depende de la combinación de escalogramas y espectrogramas, las representaciones visuales de audio, así como redes neuronales convolucionales (CNN), la herramienta de aprendizaje que utilizan las máquinas para analizar mejor las imágenes visuales. En este caso, las imágenes visuales se utilizan para analizar el audio para identificar y clasificar mejor el sonido.
El equipo publicó sus resultados en la revista. IEEE / CAA Journal of Automatica Sinica ( JAS ), una publicación conjunta del IEEE y la Asociación China de Automatización.
"Las máquinas han avanzado mucho en el análisis del habla y la música, pero el análisis de sonido general se ha quedado rezagado; por lo general, La mayoría de los 'eventos' sonoros aislados, como disparos de armas y similares, han sido atacados en el pasado, "dijo Björn Schuller, profesor y presidente de Inteligencia Integrada para el Cuidado de la Salud y el Bienestar en la Universidad de Augsburg en Alemania, quien dirigió la investigación. "El audio del mundo real suele ser una mezcla altamente combinada de diferentes fuentes de sonido, cada una de las cuales tiene diferentes estados y características".
Schuller señala el sonido de un automóvil como ejemplo. No es un evento de audio singular; partes bastante diferentes de las partes del automóvil, sus neumáticos interactuando con la carretera, la marca y la velocidad del automóvil proporcionan sus propias firmas únicas.
"Al mismo tiempo, puede haber música o habla en el coche, "dijo Schuller, quien también es profesor asociado de aprendizaje automático en el Imperial College de Londres, y profesor invitado en la Escuela de Ciencias y Tecnología de la Computación del Instituto de Tecnología de Harbin en China. "Una vez que las computadoras puedan comprender todas las partes de esta 'escena acústica', serán considerablemente mejores en descomponerlo en cada parte y atribuir cada parte como se describe ".
Los espectrogramas proporcionan una representación visual de escenas de audio, pero tienen una resolución de frecuencia de tiempo fija, ese es el momento en el que cambian las frecuencias. Escalogramas, por otra parte, ofrecen una representación visual más detallada de escenas acústicas que los espectrogramas, por ejemplo, Las escenas acústicas como la música o el habla u otros sonidos en el automóvil ahora se pueden representar mejor.
"Por lo general, ocurren varios sonidos en una escena, así que ... debe haber múltiples frecuencias y cambian con el tiempo, "dijo Zhao Ren, un autor en el artículo y un Ph.D. candidato de la Universidad de Augsburgo que trabaja con Schuller. "Afortunadamente, los escalogramas podrían resolver este problema exactamente ya que incorpora múltiples escalas ".
"Los escalogramas se pueden emplear para ayudar a los espectrogramas a extraer características para la clasificación de escenas acústicas, "Ren dijo, y tanto los espectrogramas como los escalogramas necesitan aprender a seguir mejorando.
"Más lejos, Las redes neuronales previamente entrenadas construyen un puente entre [la] imagen y el procesamiento de audio ".
Las redes neuronales previamente entrenadas que utilizaron los autores son las redes neuronales convolucionales (CNN). Las CNN se inspiran en cómo funcionan las neuronas en la corteza visual de los animales y las redes neuronales artificiales se pueden utilizar para procesar con éxito las imágenes visuales. Estas redes son cruciales en el aprendizaje automático, y en este caso, ayudando a mejorar los escalogramas.
Las CNN reciben algo de formación antes de aplicarlas a una escena, pero sobre todo aprenden de la exposición. Al aprender sonidos de una combinación de diferentes frecuencias y escalas, el algoritmo puede predecir mejor las fuentes y, finalmente, predecir el resultado de un ruido inusual, como un mal funcionamiento del motor de un coche.
"El objetivo final es escuchar / escuchar de manera integral ... a través del habla, música, y suena como lo haría un ser humano, "Schuller dijo, señalando que esto se combinaría con el trabajo ya avanzado en análisis del habla para proporcionar una comprensión más rica y profunda, "para luego poder obtener 'la imagen completa' en el audio".