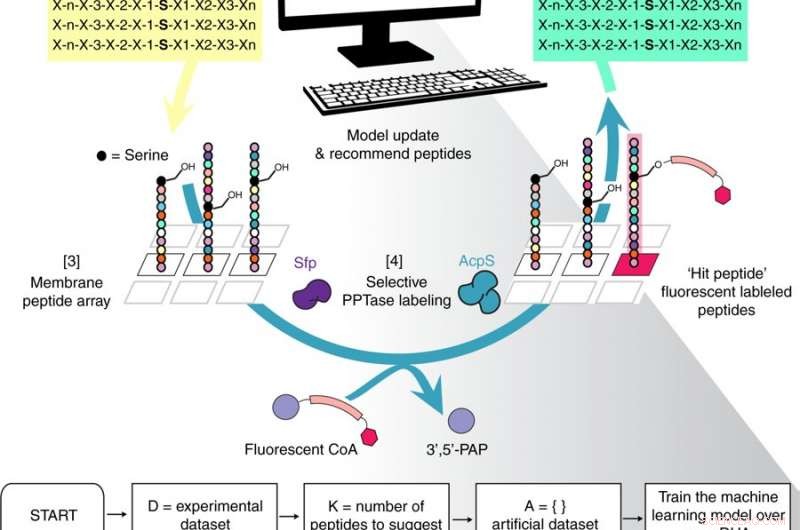
Descripción general del flujo de trabajo del método iterativo de optimización de péptidos con aprendizaje óptimo (POOL). Crédito: Comunicaciones de la naturaleza (2018). DOI:10.1038 / s41467-018-07717-6
Los científicos e ingenieros han estado interesados durante mucho tiempo en sintetizar péptidos, cadenas de aminoácidos responsables de realizar muchas funciones dentro de las células, tanto para imitar la naturaleza como para realizar nuevas actividades. Un péptido diseñado, por ejemplo, podría ser un fármaco funcional que actúe en determinadas zonas del cuerpo sin degradarse, una tarea difícil para muchos péptidos.
Pero los métodos para descubrir y sintetizar péptidos son costosos y requieren mucho tiempo, a menudo implica meses o años de conjeturas y fracasos.
Investigadores de la Universidad Northwestern, formando equipo con colaboradores de la Universidad de Cornell y la Universidad de California, San Diego, han desarrollado una nueva forma de encontrar secuencias óptimas de péptidos:utilizando un algoritmo de aprendizaje automático como colaborador.
El algoritmo analiza datos experimentales y ofrece sugerencias sobre la siguiente mejor secuencia para probar, creando un proceso de selección de ida y vuelta que reduce drásticamente el tiempo necesario para encontrar el péptido óptimo.
Los resultados, que podría proporcionar un nuevo marco para experimentos en ciencia de materiales y química, fueron publicados en Comunicaciones de la naturaleza el 7 de diciembre.
"Vemos esto como la próxima ola en cómo diseñamos moléculas y materiales, "dijo el profesor de Northwestern Nathan Gianneschi, un autor correspondiente en el artículo. "Podemos combinar lo que sabemos por intuición con el poder de un algoritmo y encontrar la solución con menos experimentos".
Gianneschi es profesor de Jacob y Rosaline Cohn en el departamento de química de la Facultad de Artes y Ciencias Weinberg de Northwestern y en los departamentos de ciencia e ingeniería de materiales y de ingeniería biomédica en Northwestern Engineering.
Para crear el método, Gianneschi, quien también es el director asociado del Instituto Internacional de Nanotecnología de Northwestern, se asoció con Peter Frazier, un profesor asociado en Cornell que trabaja en investigación de operaciones y aprendizaje automático, y Michael Burkart, un biólogo químico y experto en enzimología en UC San Diego, para encontrar una mejor manera de producir péptidos que puedan generar biomateriales, específicamente nanoestructuras y microestructuras que puedan modificar las proteínas de determinadas formas. El primer paso fue encontrar los péptidos adecuados que actuarían como sustratos enzimáticos para estas estructuras.
Los péptidos se construyen a partir de cadenas de aminoácidos que pueden tener hasta 20 aminoácidos de longitud, con 20 posibilidades diferentes para cada ácido. Dado que la secuencia determina la función del péptido, averiguar las secuencias óptimas requiere experimentos costosos que a menudo se realizan con conjeturas.
Los experimentalistas, Gianneschi y Burkart, trabajó con Frazier durante varios años para desarrollar un sistema que combinaba datos experimentales con un algoritmo de aprendizaje automático para encontrar las mejores estrategias para crear nuevos materiales.
Después de que Frazier diseñó el algoritmo y los dos trabajaron juntos para entrenarlo, los experimentadores desarrollaron una serie de 100 péptidos, llevó a cabo experimentos para averiguar cuáles funcionaron como se suponía que debían, luego introdujo esa información en el algoritmo. Luego, el algoritmo recomendó qué cambiar para la próxima ronda de desarrollo de péptidos, y también recomendó estrategias que pensaba que fracasarían.
"Ahora empezamos a tener selectividad, ", Dijo Gianneschi. Al completar este proceso varias veces, pudieron concentrarse en péptidos óptimos.
"En lugar de adivinar y mirar millones de péptidos, pudimos observar cientos de péptidos y converger muy rápidamente en secuencias que se comportaban de formas completamente nuevas, ", dijo. Cuando se compara con mutaciones aleatorias o conjeturas, el método del algoritmo fue estadísticamente mucho más exitoso.
Aunque este trabajo se centró en sustratos, este proceso podría usarse para descubrir péptidos para cualquier tipo de propósito, como la entrega de medicamentos, y tal vez incluso se utilice para descubrir secuencias de ADN, así como. Debido a que podría descubrirse cualquier tipo de secuencia óptima, los investigadores tampoco se limitan a las secuencias de aminoácidos que se encuentran en el código genético.
El siguiente paso será automatizar todo el proceso. Gianneschi también está interesado en utilizar el método para encontrar superficies óptimas para polímeros, específicamente polímeros utilizados en implantes médicos. Encontrar las superficies adecuadas que se adhieran al tejido o al músculo podría ayudar a prevenir el rechazo del tejido cicatricial o del implante.
"Básicamente, podrías descubrir secuencias que hacen cosas específicas, que es realmente el núcleo de lo que hacen los péptidos y ácidos nucleicos en la naturaleza, ", dijo." Esto podría revolucionar la forma en que fabricamos péptidos ".