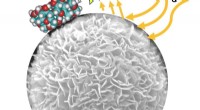
"El descubrimiento de fármacos es un proceso muy largo. En cada etapa, puede encontrar que su medicamento no es lo suficientemente bueno y necesita buscar otro candidato, "explica Xiao-Li Li de A * STAR. Su equipo ganó el 'mejor artículo' en la Conferencia Internacional de Bioinformática de 2016 por un enfoque novedoso para corregir un problema intrínseco con los métodos de aprendizaje automático.
Simulación por ordenador, o técnicas de descubrimiento de fármacos 'in silico', puede mejorar la precisión y reducir el alargamiento, camino enormemente caro para llevar un medicamento al mercado, con un promedio de más de 12 años y $ 1.8 mil millones.
Sin embargo, muchas simulaciones por computadora requieren primero "entrenamiento" en conjuntos de datos de medicamentos conocidos y sus objetivos. Estos datos pueden incluir información adicional sobre la estructura 3-D, composición química, y otras propiedades moleculares. Basándose en las tendencias de esta base de datos de datos conocidos, La simulación puede predecir las interacciones de moléculas desconocidas, lo que conduce a nuevos fármacos y nuevas proteínas diana.
Sin embargo, de todos los fármacos y dianas de la base de datos, solo ciertas combinaciones interactuarán. Los emparejamientos potenciales se ven superados con creces por los pares que no interactúan, a los que se hace referencia como "desequilibrio entre clases". Un mayor desequilibrio está presente en forma de subtipos de interacción diferentes y desiguales, apodado "desequilibrio dentro de la clase".
"Cualquier modelo computacional que esté diseñado para optimizar la precisión estará sesgado y tenderá a clasificar los pares desconocidos en clases mayoritarias o de no interacción, ", dice Li." Las clases mayoritarias están mejor representadas en los datos que las clases de interacción minoritaria; esto sesga estos modelos y produce errores. El desequilibrio de datos es un problema desafiante ".
El equipo de Li en el A * STAR Institute for Infocomm Research, trató de superar esto mediante el desarrollo de un algoritmo 'consciente del desequilibrio' que predijo con mayor precisión las interacciones fármaco-objetivo basado en una base de datos de 12, 600 interacciones conocidas y alrededor de 18 millones de pares que no interactúan. El algoritmo fue diseñado para reconocer mejor los grupos de interacción subrepresentados y mejorar los datos dentro de ellos.
Al mejorar la capacidad del modelo informático para centrarse en los datos más útiles (las interacciones), el equipo creó un sistema que superó las técnicas de modelado existentes, prediciendo nuevos, interacciones farmacológicas desconocidas con alta precisión.
El futuro del aprendizaje automático depende de la inteligencia artificial y el aprendizaje avanzado, como el "aprendizaje profundo". Sin embargo, como añade Li:"los datos son clave. Para mejorar aún más nuestra capacidad predictiva, lo primero que podemos hacer es recopilar datos más relevantes sobre fármacos y objetivos ".