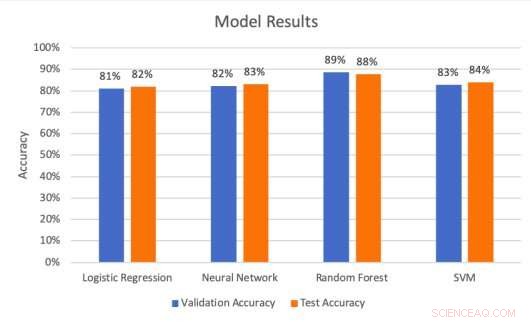
Resultados del modelo en los conjuntos de validación y prueba. Crédito:Middlebrook &Sheik.
Dos estudiantes e investigadores de la Universidad de San Francisco (USF) han intentado recientemente predecir los impactos de las vallas publicitarias utilizando modelos de aprendizaje automático. En su estudio, prepublicado en arXiv, entrenaron a cuatro modelos en datos relacionados con canciones extraídos usando la API web de Spotify, y luego evaluó su desempeño para predecir qué canciones se convertirían en éxitos.
"Soy un gran fanático de la música, y escucho música todo el día; durante mi viaje, en el trabajo, y con amigos, "Kai Middlebrook, uno de los investigadores que realizó el estudio, dijo a TechXplore. "La primavera pasada, Comencé un proyecto de investigación sobre clasificación automática de géneros musicales con el profesor David Guy Brizan en la Universidad de San Francisco (USF). El proyecto requirió una gran cantidad de datos musicales, y los populares servicios de transmisión de música tienen exactamente el tipo de datos que necesitaba ".
Mientras trabajaba en un proyecto relacionado con la clasificación automática de géneros musicales, Middlebrook se enteró de que Spotify permite a los desarrolladores acceder a sus datos musicales. Esto lo alentó a comenzar a experimentar con la API web de Spotify para recopilar datos para sus estudios. Una vez que completó la investigación relacionada con la clasificación de género, sin embargo, dejó la API a un lado durante algún tiempo.
"Unos meses después, mi amigo Kian, que también es científico de datos y ama la música, y tuve una discusión sobre música, "Dijo Middlebrook." En algún momento durante la conversación, Se planteó la idea generalizada de que "todas las canciones de éxito suenan igual". No creíamos necesariamente que fuera cierto, pero la idea nos hizo preguntarnos:¿y si las canciones de éxito comparten algunas similitudes? Parecía posible así que Kian y yo decidimos investigar más ".
Middlebrook y Sheik, que había colaborado previamente en el proyecto de clasificación de género, decidió llevar a cabo una investigación adicional utilizando datos extraídos de Spotify. Este nuevo proyecto también sería la tarea final de su curso de minería de datos en la USF.
"Estuvimos colaborando en varios otros proyectos para varios cursos, así que tenía sentido permanecer unidos "Kian Sheik, otro investigador involucrado en el estudio, dijo a TechXplore. "El éxito de Lil Nas X" Old Town Road "acababa de salir de la nada, y estaba en la cima del Billboard Hot 100. Kai y yo nos preguntamos si una computadora podría haber predicho su ascenso, o si fue solo un hit que salió del jardín izquierdo. Lo que comenzó como un simple proyecto final terminó con nosotros agotando todos los modelos de aprendizaje supervisado de última generación en un gran conjunto de datos para responder una pregunta simple:¿Será esta canción un éxito? "
En su estudio, Middlebrook y Sheik utilizaron la API web de Spotify para recopilar datos de 1,8 millones de canciones, que incluía características como el tempo de una canción, llave, valencia, etc. Luego también recopilaron aproximadamente 30 años de datos de la lista Billboard Hot 100.
"Nuestro objetivo era ver si las canciones de éxito compartían características similares, y de ser así, si esas funciones podrían usarse para predecir qué canciones serían éxitos en el futuro, "Dijo Middlebrook.
Los investigadores entrenaron y evaluaron cuatro modelos diferentes:una regresión logística, una red neuronal, una máquina de vectores de soporte (SVM) y una arquitectura de bosque aleatorio (RF). Durante el entrenamiento, estos modelos analizaron una variedad de características de la canción, incluido el tempo, llave, valencia, energía, acústica, bailabilidad y sonoridad.
"Cuando se le da una canción, nuestros modelos lo etiquetarían con un uno o un cero, "Middlebrook explicó." Una canción etiquetada con un uno significa que el modelo predice que la canción fue un éxito. Una canción etiquetada con un cero significa que el modelo predice que la canción no fue un éxito ".
El modelo de regresión logística entrenado por los investigadores asume que los datos de las canciones se pueden separar linealmente en dos categorías:hits y no hits. El modelo asigna un peso a cada característica de la canción, y luego usa estos pesos para predecir si una canción cae en la categoría "exitosa" o "no exitosa".
Los modelos de regresión logística tienen dos ventajas importantes:interpretabilidad y velocidad. En otras palabras, este tipo de arquitectura facilita la interpretación de la relación entre variables explicativas (es decir, las características de la canción) y la variable de respuesta (es decir, golpeado o no golpeado), y también se puede entrenar con relativa rapidez.
El segundo modelo entrenado por los investigadores fue una arquitectura de RF. Este modelo funciona combinando una gran cantidad de bloques de construcción conocidos como árboles de decisión.
"Esencialmente, un árbol de decisiones puede considerarse como un modelo que utiliza una serie de preguntas de sí / no para separar los datos, ", Dijo Middlebrook." Son interpretables, pero propenso a sobreajustar los datos. El sobreajuste significa que un modelo memoriza los datos de entrenamiento ajustándolos demasiado. El problema con el sobreajuste es que es posible que el modelo no esté aprendiendo la relación real entre las características de la canción y la popularidad de la canción porque los datos a menudo contienen ruido irrelevante ".
Para evitar el problema del sobreajuste, el modelo de bosque aleatorio utilizado por Middlebrook y Sheik combina cientos de miles de árboles de decisión, cada uno de los cuales se entrena en un subconjunto diferente de los datos de entrenamiento y un subconjunto diferente de las características de la canción. Luego, el modelo hace una predicción (es decir, decide si una canción es un éxito o no) al promediar la predicción de cada árbol y combinar estos resultados.
"En nuestro caso de uso, la ventaja del modelo de bosque aleatorio es su flexibilidad, ", Dijo Middlebrook." Es más flexible que un modelo lineal (por ejemplo, regresión logística) ".
El tercer y cuarto modelos entrenados por los investigadores, a saber, las arquitecturas de redes neuronales y SVM, son no lineales y, por tanto, más difíciles de interpretar. El modelo SVM funciona tratando de encontrar el "hiperplano" que mejor separa los datos en las dos categorías (es decir, hits o no hits). La arquitectura de la red neuronal, por otra parte, utiliza una capa oculta con diez filtros para aprender de los datos de la canción.
Entre los cuatro modelos utilizados por Middlebrook y Sheik, el modelo de regresión logística es el más fácil de interpretar, mientras que el basado en redes neuronales es el más difícil. Los otros dos modelos se encuentran en algún punto intermedio.
"Generalmente, estos modelos predecirán en función de las limitaciones que desarrollen a través del entrenamiento, "Dijo Sheik." Cada modelo ha sido entrenado en el mismo conjunto de clasificadores sónicos. La salida de los modelos se prueba con la verdad histórica de la API de Billboard, si la pista dada ha aparecido alguna vez en la lista Billboard Hot 100. Usamos una flota de computadoras en USF para hacer el procesamiento numérico y, después de un par de semanas de computación pura, habíamos calculado los parámetros óptimos para cada modelo ".
Los investigadores llevaron a cabo una serie de evaluaciones para probar qué tan bien los cuatro modelos podían predecir los impactos de las vallas publicitarias. Descubrieron que la arquitectura SVM alcanzó la tasa de precisión más alta (99,53 por ciento), mientras que el modelo de bosque aleatorio alcanzó la mejor tasa de precisión (88 por ciento) y la tasa de recuperación (85,51 por ciento).
"Recall expresa la capacidad de encontrar todas las instancias relevantes en un conjunto de datos, mientras que la precisión expresa qué proporción de datos que nuestro modelo dice que eran relevantes en realidad eran relevantes, Middlebrook explicó. En otras palabras, Recuerde decirnos qué tan probable es que nuestro modelo prediga con precisión un acierto real como acierto. La precisión nos dice la proporción de aciertos previstos que en realidad fueron aciertos ".
Según los investigadores, si los sellos discográficos utilizaran alguno de estos modelos para predecir qué canciones tendrán más éxito, probablemente elegirían un modelo con una alta tasa de precisión que uno con una alta tasa de precisión. Esto se debe a que un modelo que alcanza una alta precisión asume menos riesgo, ya que es menos probable predecir que una canción que no tiene éxito se convertirá en un éxito.
"Los sellos discográficos tienen recursos limitados, ", Dijo Middlebrook." Si vierten estos recursos en una canción que el modelo predice que será un éxito y esa canción nunca se convierte en uno, entonces la etiqueta puede perder mucho dinero. Entonces, si un sello discográfico quiere correr un poco más de riesgo con la posibilidad de lanzar más discos exitosos, podrían optar por utilizar nuestro modelo de bosque aleatorio. Por otra parte, si un sello discográfico quiere asumir menos riesgos y al mismo tiempo lanzar algunos éxitos, deberían utilizar nuestro modelo SVM ".
Middlebrook y Sheik descubrieron que predecir el éxito de una cartelera en función de las características del audio de una canción es, De hecho, posible. En su investigación futura, los investigadores planean investigar otros factores que podrían contribuir al éxito de la canción, como la presencia en las redes sociales, experiencia de artista, e influencia de la etiqueta.
"Podemos imaginar un mundo en el que los sellos discográficos que buscan constantemente nuevos talentos se vean inundados de cintas mixtas y demos de los" próximos artistas calientes, "" Dijo Sheik. "La gente tiene un tiempo limitado para escuchar música con oídos humanos, así que "orejas artificiales, "como nuestros algoritmos, puede permitir a los sellos discográficos entrenar un modelo para el tipo de sonido que buscan y reducir en gran medida la cantidad de canciones que ellos mismos deben considerar ".
Clasificadores como los desarrollados por Middlebrook y Sheik podrían ayudar a los sellos discográficos a decidir en qué canciones invertir. Aunque la idea de utilizar el aprendizaje automático para hojear demos puede ser de interés para la industria de la música, Sheik advierte que también podría tener consecuencias no deseadas.
"Si bien este puede ser un futuro oportuno, la perspectiva de un proverbial "bloque de corte" que los artistas tienen que medir tiene el potencial de convertirse en una cámara de eco, o una situación en la que la música nueva debe sonar como música antigua para ser lanzada en la radio, ", Dijo Sheik." Los creadores de contenido en plataformas como YouTube, que también utiliza algoritmos para decidir qué videos se muestran a las masas, han denunciado las trampas de obligar a los artistas a trabajar para una máquina ".
Según Sheik, si las empresas y los productores empiezan a utilizar algoritmos para tomar decisiones artísticas, estos modelos deben diseñarse de manera que no obstaculicen el progreso del arte. Las arquitecturas desarrolladas por los dos investigadores de la USF, sin embargo, todavía no son capaces de lograrlo.
"Tendrán que introducirse e inventarse el sesgo de la novedad y otras características poco ortodoxas para que la música en su conjunto no se acerque a una singularidad cultural en manos de la conveniencia, ", Concluyó Sheik.
© 2019 Science X Network














