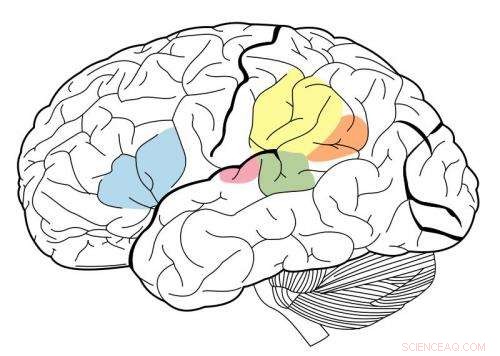
La corteza auditiva primaria está resaltada en magenta, y se sabe que interactúa con todas las áreas resaltadas en este mapa neuronal. Crédito:Wikipedia.
Mediante un sistema de aprendizaje automático conocido como red neuronal profunda, Los investigadores del MIT han creado el primer modelo que puede replicar el desempeño humano en tareas auditivas como identificar un género musical.
Este modelo, que consta de muchas capas de unidades de procesamiento de información que se pueden entrenar en grandes volúmenes de datos para realizar tareas específicas, fue utilizado por los investigadores para arrojar luz sobre cómo el cerebro humano puede estar realizando las mismas tareas.
"Lo que nos dan estos modelos, por primera vez, son sistemas de máquinas que pueden realizar tareas sensoriales que son importantes para los humanos y que lo hacen a nivel humano, "dice Josh McDermott, Frederick A. y Carole J. Middleton, profesora asistente de neurociencia en el Departamento de Ciencias Cerebrales y Cognitivas del MIT y autora principal del estudio. "Históricamente, este tipo de procesamiento sensorial ha sido difícil de entender, en parte porque realmente no hemos tenido una base teórica muy clara y una buena manera de desarrollar modelos de lo que podría estar sucediendo ".
El estudio, que aparece en la edición del 19 de abril de Neurona , también ofrece evidencia de que la corteza auditiva humana está organizada en una organización jerárquica, muy parecido a la corteza visual. En este tipo de arreglo, la información sensorial pasa por etapas sucesivas de procesamiento, con información básica procesada antes y características más avanzadas, como el significado de palabras extraídas en etapas posteriores.
El estudiante graduado del MIT, Alexander Kell, y el profesor asistente de la Universidad de Stanford, Daniel Yamins, son los autores principales del artículo. Otros autores son la ex estudiante visitante del MIT Erica Shook y el ex postdoctorado del MIT Sam Norman-Haignere.
Modelando el cerebro
Cuando las redes neuronales profundas se desarrollaron por primera vez en la década de 1980, Los neurocientíficos esperaban que tales sistemas pudieran usarse para modelar el cerebro humano. Sin embargo, las computadoras de esa época no eran lo suficientemente potentes para construir modelos lo suficientemente grandes para realizar tareas del mundo real como el reconocimiento de objetos o el reconocimiento de voz.
En los últimos cinco años, Los avances en la potencia informática y la tecnología de redes neuronales han hecho posible el uso de redes neuronales para realizar tareas difíciles del mundo real. y se han convertido en el enfoque estándar en muchas aplicaciones de ingeniería. En paralelo, algunos neurocientíficos han revisado la posibilidad de que estos sistemas puedan usarse para modelar el cerebro humano.
"Ha sido una gran oportunidad para la neurociencia, en el sentido de que podemos crear sistemas que puedan hacer algunas de las cosas que la gente puede hacer, y luego podemos interrogar los modelos y compararlos con el cerebro, "Dice Kell.
Los investigadores del MIT entrenaron su red neuronal para realizar dos tareas auditivas, uno que involucra el habla y el otro que involucra la música. Para la tarea del habla, los investigadores le dieron al modelo miles de grabaciones de dos segundos de una persona hablando. La tarea consistía en identificar la palabra en medio del clip. Para la tarea musical, Se pidió al modelo que identificara el género de un clip de música de dos segundos. Cada clip también incluía ruido de fondo para hacer la tarea más realista (y más difícil).
Después de muchos miles de ejemplos, el modelo aprendió a realizar la tarea con la misma precisión que un oyente humano.
"La idea es que, con el tiempo, el modelo mejora cada vez más en la tarea, ", Dice Kell." La esperanza es que esté aprendiendo algo general, así que si presenta un nuevo sonido que el modelo nunca ha escuchado antes, le irá bien, y en la práctica ese suele ser el caso ".
El modelo también tendía a cometer errores en los mismos clips en los que los humanos cometieron más errores.
Las unidades de procesamiento que componen una red neuronal se pueden combinar de diversas formas, formando diferentes arquitecturas que afectan el desempeño del modelo.
El equipo del MIT descubrió que el mejor modelo para estas dos tareas era el que dividía el procesamiento en dos conjuntos de etapas. El primer conjunto de etapas se compartió entre tareas, pero después de eso, se dividió en dos ramas para un análisis más detallado:una rama para la tarea de habla, y uno para la tarea de género musical.
Evidencia de jerarquía
Luego, los investigadores utilizaron su modelo para explorar una pregunta de larga data sobre la estructura de la corteza auditiva:si está organizada jerárquicamente.
En un sistema jerárquico, una serie de regiones del cerebro realiza diferentes tipos de cálculos sobre la información sensorial a medida que fluye a través del sistema. Está bien documentado que la corteza visual tiene este tipo de organización. Regiones anteriores, conocida como la corteza visual primaria, responder a características simples como el color o la orientación. Las etapas posteriores permiten tareas más complejas como el reconocimiento de objetos.
Sin embargo, Ha sido difícil probar si este tipo de organización también existe en la corteza auditiva, en parte porque no ha habido buenos modelos que puedan replicar el comportamiento auditivo humano.
"Pensamos que si podíamos construir un modelo que pudiera hacer algunas de las mismas cosas que hace la gente, entonces podríamos comparar diferentes etapas del modelo con diferentes partes del cerebro y obtener alguna evidencia de si esas partes del cerebro podrían estar organizadas jerárquicamente, "Dice McDermott.
Los investigadores encontraron que en su modelo, Las características básicas del sonido, como la frecuencia, son más fáciles de extraer en las primeras etapas. A medida que la información se procesa y avanza a lo largo de la red, se vuelve más difícil extraer la frecuencia, pero más fácil extraer información de nivel superior, como palabras.
Para ver si las etapas del modelo podrían replicar cómo la corteza auditiva humana procesa la información sonora, Los investigadores utilizaron imágenes de resonancia magnética funcional (fMRI) para medir diferentes regiones de la corteza auditiva a medida que el cerebro procesa los sonidos del mundo real. Luego compararon las respuestas del cerebro con las respuestas en el modelo cuando procesó los mismos sonidos.
Descubrieron que las etapas intermedias del modelo correspondían mejor a la actividad en la corteza auditiva primaria, y las etapas posteriores correspondieron mejor a la actividad fuera de la corteza primaria. Esto proporciona evidencia de que la corteza auditiva podría estar ordenada de manera jerárquica, similar a la corteza visual, dicen los investigadores.
"Lo que vemos muy claramente es una distinción entre la corteza auditiva primaria y todo lo demás, "Dice McDermott.
Los autores ahora planean desarrollar modelos que puedan realizar otros tipos de tareas auditivas, como determinar la ubicación de la que proviene un sonido en particular, para explorar si estas tareas se pueden realizar por las vías identificadas en este modelo o si requieren vías separadas, que luego podría investigarse en el cerebro.