Crédito:CERN
El modelo estándar de física de partículas encapsula nuestro conocimiento actual de las partículas elementales y sus interacciones. El modelo estándar no está completo; por ejemplo, no describe observaciones como la gravedad, no tiene predicciones para la materia oscura, que constituye la mayor parte de la materia del universo, o que los neutrinos tienen masa.
Para corregir las debilidades del modelo estándar, los físicos proponen extensiones y verifican las colisiones en el LHC para ver si las predicciones de esos modelos de "física más allá del modelo estándar" aparecerían como nuevas partículas o cambios en el comportamiento de partículas conocidas. Supersimetría, o SUSY para abreviar, es una de esas extensiones del modelo estándar. La supersimetría predice que cada tipo de partícula conocido en el modelo estándar tiene un socio supersimétrico. El número de tipos de partículas en la naturaleza se duplicaría efectivamente, y serían posibles muchas interacciones nuevas entre las partículas regulares y las nuevas partículas SUSY.
En un experimento de colisionador como CMS, la esperanza es producir algunas partículas SUSY y luego buscar signos de su descomposición dentro del detector. Una de las firmas más comunes para la supersimetría se mediría como partículas aparentemente faltantes que crean un desequilibrio energético sustancial en el detector llamado energía transversal faltante. ¡Esta es una firma de estado final que es difícil pasar por alto!
Se han realizado muchas búsquedas en CMS para buscar estas firmas de energía transversal que faltan altas, pero no se ha encontrado tal evidencia de supersimetría. Pero, tal vez la supersimetría esté ahí, y es simplemente "más sigiloso" de lo que se pensaba inicialmente. Hay muchas firmas posibles diferentes que la supersimetría podría crear, y en algunas versiones modificadas de supersimetría, una característica clave es la predicción de que todas las partículas SUSY volverían a descomponerse en partículas de modelo estándar, por ejemplo, quarks, cada uno de los cuales aparecería en el detector como un rocío de partículas, que se llama jet. Si esta versión de supersimetría es real, La producción de partículas SUSY en una colisión protón-protón dará como resultado un estado final con muchos chorros en lugar de uno con una considerable pérdida de energía. En este caso, ¡Tendría sentido por qué estas búsquedas anteriores no han encontrado nada!
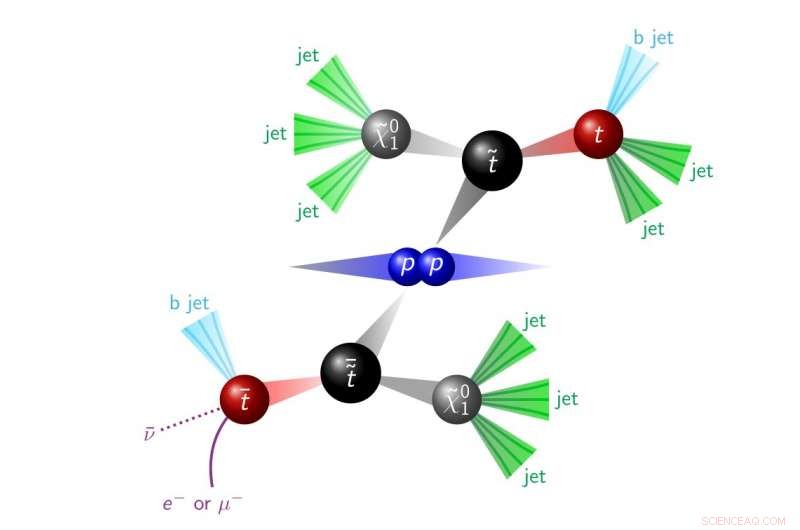
Figura 1. Una dramatización de una colisión protón-protón que produce partículas SUSY, que decaen a los objetos observados en el detector (esta es una firma para la denominada paridad R que viola SUSY). Crédito:CERN
El objetivo de esta búsqueda es averiguar si la supersimetría se ha estado escondiendo allí todo el tiempo buscando específicamente la producción de dos quarks top supersimétricos (llamados top squarks). Estos escuadrones superiores decaen en el detector, creando dos quarks top y muchos otros jets, como se muestra en la Figura 1. Esta firma no es tan evidente como una que incluye grandes cantidades de energía faltante, ya que hay muchas formas diferentes en que el modelo estándar puede producir dos quarks top y muchos jets. Sin embargo, esta señal de escuadra superior tiende a producir más chorros en promedio que cualquiera de los procesos de fondo conocidos. El modelado de eventos con una gran cantidad de chorros también es muy complicado, e incluso las mejores herramientas de simulación no siempre lo hacen bien. Por lo tanto, Se confía en los datos para predecir el número de eventos con un cierto número de chorros.
Nuestra estrategia no habría sido posible sin aprovechar el poder del aprendizaje automático y las redes neuronales. Una técnica genial de aprendizaje automático que se utilizó para identificar colisiones que podrían contener las desintegraciones de los escuadrones superiores se llama inversión de gradiente. que se puede explicar de la siguiente manera. Imagínese que está clasificando chocolates en dos categorías:chocolates con caramelo y chocolates regulares. Sabes que los chocolates de caramelo son más pesados que los chocolates normales porque están rellenos de caramelo. Digamos también que los bombones solo vienen en dos formas entre todas las variedades caramelo y regular:cuadrados o círculos. Finalmente, te dicen que los bombones cuadrados son, de media, más pesados que los circulares.
Una forma de clasificar los chocolates es clasificar todos los chocolates cuadrados como chocolates de caramelo y todos los chocolates circulares como chocolates regulares. Después de todo, tanto los bombones cuadrados como los bombones de caramelo son en general más pesados. Este método de clasificación no es correcto porque no todos los chocolates cuadrados contienen caramelo, por lo que probablemente sea mejor clasificar los chocolates independientemente de su forma. Ignorar la forma al ordenar es equivalente a lo que la inversión de gradiente nos permite hacer en el contexto de la física. En lugar de caramelo y chocolates normales, la clasificación es entre eventos de señal y de fondo, y en lugar de forma, la clasificación debe ser independiente del número de chorros.
Esta estrategia es precisamente lo que se necesita para modelar la distribución del número de chorros directamente a partir de los datos. Los eventos en la categoría de fondo se utilizan para predecir cuántos eventos debería haber con un cierto número de inyectores en la categoría de señal. Dado que el modelo de señal tiende a producir más chorros que los fondos del modelo estándar, cualquier desviación de la predicción podría significar que efectivamente había algún SUSY escondido allí.
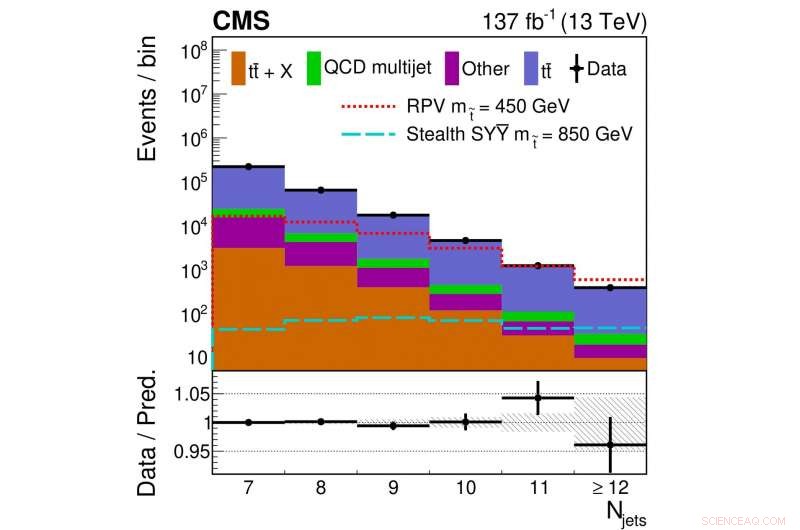
Figura 2. La distribución del número de eventos con un cierto número de chorros se muestra para los datos recopilados (puntos negros) y las contribuciones predichas de fondos de modelos estándar conocidos (bloques de colores). Diferentes líneas de colores / estilos muestran la distribución del número de chorros para diferentes modelos de SUSY con masas de squark superiores específicas.
La Figura 2 muestra una comparación de la distribución del número de chorros obtenidos a partir de los datos recopilados con la de nuestra predicción de fondo final. En este caso, la predicción asume que no hay contribución de nuestros modelos de señales hipotetizados. Aquí, la concordancia entre los datos y nuestra predicción de cuatro categorías de procesos de modelos estándar es razonablemente buena.
Cuando los datos se dividen en más categorías de las que se muestran en la Figura 2, se encuentra una pequeña desviación de nuestra predicción. Sin embargo, la desviación no es lo suficientemente grande como para hacer una afirmación sólida sobre si esto indica o no que la supersimetría podría ser correcta. Lo más probable es que haya solo una fluctuación estadística en los datos, o quizás que hay un problema de modelado desconocido.
En física de partículas, el "patrón oro" es declarar un descubrimiento de nueva física cuando un resultado tiene una significación de 5 desviaciones estándar o más. Esto significa que solo hay una probabilidad de 1 entre 3,5 millones de que el resultado sea solo de una fluctuación aleatoria en los datos. Evidencia, o afirmar que algo es lo suficientemente interesante como para considerar la posibilidad de que sea nuevo, solo se realiza con una significancia de 3 desviaciones estándar, lo que representa una probabilidad de 1 en 740 de que el resultado sea una fluctuación. Este estándar es muy estricto en comparación con la mayoría de las otras disciplinas científicas. El LHC produce una gran cantidad de datos, de modo que puede suceder que una desviación de la predicción del modelo estándar se obtenga simplemente por azar. En física de partículas, definitivamente no se justifica reclamar ninguna desviación sin examinar seriamente su validez estadística.
La importancia de la mayor desviación que se observó en este análisis, sin corrección por el efecto de mirar en otra parte, es 2,8 desviaciones estándar. Esto significa que incluso si no hay supersimetría, uno espera ver ese resultado una vez cada 368 veces, muy por debajo del umbral de 5 desviaciones estándar. Dado que CMS ha publicado más de 1000 artículos, muchos buscan en decenas o cientos de lugares, puede ver que una fluctuación ocasional en un resultado no es para nada sorprendente. Los resultados también se pueden interpretar como un límite en los escenarios de supersimetría sigilosa permitidos que aún son consistentes con los datos. Dependiendo de los detalles del modelo, Se pueden excluir las masas de squark superior por debajo de ~ 700 GeV.
Esta búsqueda es la primera de su tipo en el LHC, arrojando luz sobre una firma previamente inexplorada. La ligera discrepancia encontrada es tentadora e impulsa estudios de seguimiento para investigar si su origen es una simple fluctuación estadística. si se debe a nuestra comprensión del modelo estándar, que sería interesante por derecho propio, o si podría ser el primer signo de una nueva física. También, a partir de 2022, comenzará el próximo período de toma de datos del LHC. Esto ayudará a CMS a sacar conclusiones aún más contundentes sobre la posibilidad de una nueva física. Si realmente existe supersimetría sigilosa, entonces estos datos adicionales permitirían un resultado más significativo, potencialmente empujando hacia el patrón oro para el descubrimiento.