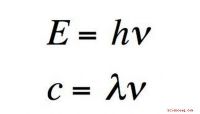Crédito:CC0 Public Domain
Técnicas de aprendizaje automático más conocido por enseñar a los coches autónomos a detenerse en los semáforos en rojo, pronto podrá ayudar a los investigadores de todo el mundo a mejorar su control sobre la reacción más complicada conocida por la ciencia:la fusión nuclear.
Las reacciones de fusión son típicamente átomos de hidrógeno calentados para formar una nube gaseosa llamada plasma que libera energía cuando las partículas chocan entre sí y se fusionan. Controlar mejor estas reacciones podría generar enormes cantidades de energía ambientalmente limpia a partir de los reactores nucleares de las plantas de energía de fusión del futuro.
"La conexión entre el aprendizaje automático y la energía de fusión no es obvia, ", dijo el investigador de Sandia National Laboratories, Aidan Thompson, investigador principal para un premio de tres años de la Oficina de Ciencias del Departamento de Energía de $ 2.2 millones anuales para hacer esa misma conexión. "Simplemente pon, hemos sido pioneros en el uso del aprendizaje automático para mejorar las simulaciones del material de la pared del reactor cuando interactúa con el plasma. Esto ha estado más allá del alcance de las simulaciones a escala atómica del pasado ".
El resultado esperado debería sugerir modificaciones de procedimiento o estructurales para mejorar la producción de energía nuclear, él dijo.
El poder del aprendizaje automático en el modelado de la fusión nuclear
El aprendizaje automático es poderoso porque utiliza medios matemáticos y estadísticos para descubrir una situación, en lugar de analizar todos los datos de la categoría deseada. Por ejemplo, solo se necesita una pequeña cantidad de fotos de perros para enseñarle a un sistema de reconocimiento el concepto de "perrito"; en otras palabras, "esto es un perro", en lugar de escanear todas las fotos de perros que existen.
El enfoque de aprendizaje automático de Sandia para la fusión nuclear es el mismo, pero más complicado.
“No es un problema trivial observar físicamente lo que está sucediendo dentro de las paredes de un reactor, ya que estas estructuras son bombardeadas internamente con hidrógeno, helio, deuterio y tritio como partes de un plasma sobrecalentado, "dijo Thompson.
Describió los componentes del plasma en círculos que golpean y alteran la composición de los muros de contención y los átomos pesados que se desprenden de los muros golpeados y alteran el plasma. Las reacciones tienen lugar en nanosegundos a temperaturas tan calientes como el sol. Intentar modificar componentes mediante prueba y error para mejorar los resultados es extraordinariamente laborioso.
Algoritmos de aprendizaje automático, por otra parte, usan datos generados por computadora sin mediciones directas de experimentos y pueden producir información que eventualmente podría usarse para hacer que las interacciones del plasma con el material de la pared de contención sean menos dañinas y así mejorar la producción de energía general de los reactores de fusión.
"No hay otra forma de obtener esta información, "dijo Thompson.
Un pequeño número de átomos predice la energía de muchos
El equipo de Thompson espera que al usar grandes conjuntos de datos de cálculos de mecánica cuántica en condiciones extremas como datos de entrenamiento, pueden construir un modelo de aprendizaje automático que predice la energía de cualquier configuración de átomos.
Este modelo, llamado potencial interatómico de aprendizaje automático, o MLIAP, se puede insertar en enormes códigos clásicos de dinámica molecular, como los galardonados LAMMPS de Sandia, o Simulador masivamente paralelo atómico / molecular a gran escala, software. De este modo, interrogando sólo a un número relativamente pequeño de átomos, pueden extender la precisión de la mecánica cuántica a la escala de millones de átomos necesarios para simular el comportamiento de los materiales de energía de fusión.
"Entonces, ¿por qué lo que estamos haciendo es aprendizaje automático y no solo llevar una gran cantidad de datos en la contabilidad?" pregunta Thompson retóricamente. "La respuesta corta es, generamos ecuaciones a partir de un conjunto infinito de posibles variables para construir modelos basados en la física, pero que contienen cientos o miles de parámetros que nos mantienen dentro del alcance de nuestro objetivo ".
Un problema es que la precisión del modelo MLIAP depende de la superposición entre los datos de entrenamiento y los entornos atómicos reales encontrados por la aplicación. dijo Thompson.
Estos entornos pueden ser varios, requiriendo nuevos datos de entrenamiento y alteración del modelo de aprendizaje automático. Reconocer y ajustar las superposiciones es parte del trabajo de los próximos años.
"Nuestro modelo al principio se utilizará para interpretar pequeños experimentos, "Dijo Thompson." A la inversa, que los datos experimentales se utilizarán para validar nuestro modelo, que luego se puede utilizar para hacer predicciones sobre lo que está sucediendo en un reactor de fusión a gran escala ".
El objetivo de dar acceso a los investigadores de la fusión a los modelos de aprendizaje automático de Sandia para construir mejores reactores de fusión es de aproximadamente tres años. dijo Thompson.