Un nuevo diseño de chip fotónico reduce drásticamente la energía necesaria para calcular con luz, con simulaciones que sugieren que podría ejecutar redes neuronales ópticas 10 millones de veces más eficientemente que sus contrapartes eléctricas. Crédito:MIT News
Los investigadores del MIT han desarrollado un nuevo chip "fotónico" que utiliza luz en lugar de electricidad y consume relativamente poca energía en el proceso. El chip podría usarse para procesar redes neuronales masivas millones de veces más eficientemente que las computadoras clásicas de hoy.
Las redes neuronales son modelos de aprendizaje automático que se utilizan ampliamente para tareas como la identificación robótica de objetos, procesamiento natural del lenguaje, desarrollo de fármacos, imagenes medicas, y propulsar coches sin conductor. Nuevas redes neuronales ópticas, que utilizan fenómenos ópticos para acelerar el cálculo, pueden funcionar mucho más rápido y más eficientemente que sus contrapartes eléctricas.
Pero a medida que las redes neuronales ópticas y tradicionales se vuelven más complejas, consumen toneladas de energía. Para abordar ese problema, investigadores y las principales empresas de tecnología, incluido Google, IBM, y Tesla, han desarrollado "aceleradores de IA, "chips especializados que mejoran la velocidad y la eficiencia del entrenamiento y prueba de redes neuronales.
Para chips eléctricos, incluyendo la mayoría de los aceleradores de IA, hay un límite mínimo teórico para el consumo de energía. Recientemente, Los investigadores del MIT han comenzado a desarrollar aceleradores fotónicos para redes neuronales ópticas. Estos chips realizan órdenes de magnitud de manera más eficiente, pero dependen de algunos componentes ópticos voluminosos que limitan su uso a redes neuronales relativamente pequeñas.
En un artículo publicado en Revisión física X , Los investigadores del MIT describen un nuevo acelerador fotónico que utiliza componentes ópticos más compactos y técnicas de procesamiento de señales ópticas, para reducir drásticamente tanto el consumo de energía como el área del chip. Eso permite que el chip escale a redes neuronales varios órdenes de magnitud más grandes que sus contrapartes.
El entrenamiento simulado de redes neuronales en el conjunto de datos de clasificación de imágenes del MNIST sugiere que, en teoría, el acelerador puede procesar redes neuronales más de 10 millones de veces por debajo del límite de consumo de energía de los aceleradores eléctricos tradicionales y aproximadamente 1, 000 veces por debajo del límite de los aceleradores fotónicos. Los investigadores ahora están trabajando en un chip prototipo para probar experimentalmente los resultados.
"La gente busca tecnología que pueda computar más allá de los límites fundamentales del consumo de energía, "dice Ryan Hamerly, un postdoctorado en el Laboratorio de Investigación de Electrónica. "Los aceleradores fotónicos son prometedores ... pero nuestra motivación es construir un [acelerador fotónico] que pueda escalar a grandes redes neuronales".
Las aplicaciones prácticas de estas tecnologías incluyen la reducción del consumo de energía en los centros de datos. "Existe una demanda creciente de centros de datos para ejecutar grandes redes neuronales, y se está volviendo cada vez más intratable computacionalmente a medida que crece la demanda, "dice el coautor Alexander Sludds, estudiante de posgrado en el Laboratorio de Investigación en Electrónica. El objetivo es "satisfacer la demanda computacional con hardware de red neuronal ... para abordar el cuello de botella del consumo de energía y la latencia".
Junto a Sludds y Hamerly en el artículo están:la coautora Liane Bernstein, un estudiante de posgrado de RLE; Marin Soljacic, profesor de física del MIT; y Dirk Englund, un profesor asociado del MIT de ingeniería eléctrica y ciencias de la computación, un investigador en RLE, y jefe del Laboratorio de Fotónica Cuántica.
Diseño compacto
Las redes neuronales procesan datos a través de muchas capas computacionales que contienen nodos interconectados, llamadas "neuronas, "para encontrar patrones en los datos. Las neuronas reciben información de sus vecinos aguas arriba y calculan una señal de salida que se envía a las neuronas aguas abajo. A cada entrada también se le asigna un" peso, "un valor basado en su importancia relativa para todas las demás entradas. A medida que los datos se propagan" más profundamente "a través de las capas, la red aprende progresivamente información más compleja. En el final, una capa de salida genera una predicción basada en los cálculos de las capas.
Todos los aceleradores de IA tienen como objetivo reducir la energía necesaria para procesar y mover datos durante un paso específico de álgebra lineal en redes neuronales. llamado "multiplicación de matrices". Allí, las neuronas y los pesos se codifican en tablas separadas de filas y columnas y luego se combinan para calcular los resultados.
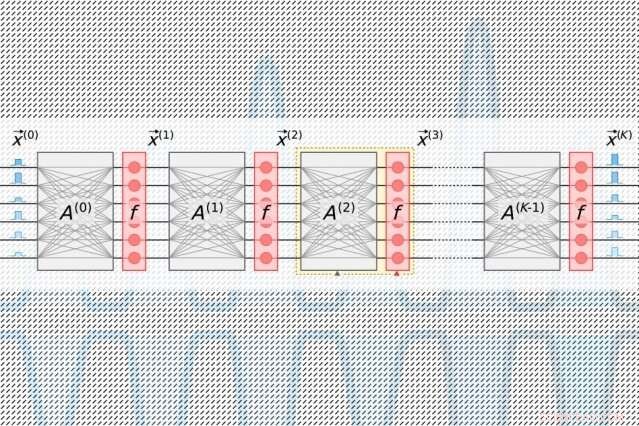
En los aceleradores fotónicos tradicionales, Los láseres pulsados codificados con información sobre cada neurona en una capa fluyen hacia guías de ondas y a través de divisores de haz. Las señales ópticas resultantes se alimentan a una cuadrícula de componentes ópticos cuadrados, llamados "interferómetros Mach-Zehnder, "que están programados para realizar la multiplicación de matrices. Los interferómetros, que están codificados con información sobre cada peso, utilice técnicas de interferencia de señales que procesen las señales ópticas y los valores de peso para calcular una salida para cada neurona. Pero hay un problema de escala:para cada neurona debe haber una guía de ondas y, por cada peso, debe haber un interferómetro. Debido a que el número de pesos se cuadra con el número de neuronas, esos interferómetros ocupan mucho espacio.
"Te das cuenta rápidamente de que la cantidad de neuronas de entrada nunca puede ser mayor de 100, aproximadamente, porque no puede colocar tantos componentes en el chip, "Dice Hamerly." Si su acelerador fotónico no puede procesar más de 100 neuronas por capa, entonces hace que sea difícil implementar grandes redes neuronales en esa arquitectura ".
El chip de los investigadores se basa en un dispositivo más compacto esquema "optoelectrónico" energéticamente eficiente que codifica datos con señales ópticas, pero usa "detección homodina balanceada" para la multiplicación de matrices. Esa es una técnica que produce una señal eléctrica medible después de calcular el producto de las amplitudes (alturas de onda) de dos señales ópticas.
Los pulsos de luz codificados con información sobre las neuronas de entrada y salida para cada capa de la red neuronal, que son necesarias para entrenar la red, fluyen a través de un solo canal. Los pulsos separados codificados con información de filas enteras de pesos en la tabla de multiplicación de matrices fluyen a través de canales separados. Las señales ópticas que transportan la neurona y los datos de peso se abren en abanico a la red de fotodetectores homodinos. Los fotodetectores utilizan la amplitud de las señales para calcular un valor de salida para cada neurona. Cada detector alimenta una señal de salida eléctrica para cada neurona en un modulador, que convierte la señal nuevamente en un pulso de luz. Esa señal óptica se convierte en la entrada para la siguiente capa, etcétera.
El diseño requiere solo un canal por neurona de entrada y salida, y solo tantos fotodetectores homodinos como neuronas, no pesos. Debido a que siempre hay muchas menos neuronas que pesos, esto ahorra un espacio significativo, por lo que el chip puede escalar a redes neuronales con más de un millón de neuronas por capa.
Encontrar el punto ideal
Con aceleradores fotónicos, hay un ruido inevitable en la señal. Cuanta más luz se alimenta al chip, cuanto menos ruido y mayor es la precisión, pero eso se vuelve bastante ineficiente. Menos luz de entrada aumenta la eficiencia pero afecta negativamente el rendimiento de la red neuronal. Pero hay un "punto óptimo, "Bernstein dice, que utiliza una potencia óptica mínima manteniendo la precisión.
Ese punto óptimo para los aceleradores de IA se mide en cuántos julios se necesitan para realizar una sola operación de multiplicar dos números, como durante la multiplicación de matrices. Ahora, los aceleradores tradicionales se miden en picojulios, o una billonésima de julio. Los aceleradores fotónicos se miden en attojulios, que es un millón de veces más eficiente.
En sus simulaciones, los investigadores descubrieron que su acelerador fotónico podría funcionar con una eficiencia inferior a attojulios. "Hay una potencia óptica mínima que puedes enviar, antes de perder precisión. El límite fundamental de nuestro chip es mucho más bajo que los aceleradores tradicionales ... y más bajo que otros aceleradores fotónicos, "Dice Bernstein.
Esta historia se vuelve a publicar por cortesía de MIT News (web.mit.edu/newsoffice/), un sitio popular que cubre noticias sobre la investigación del MIT, innovación y docencia.