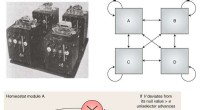
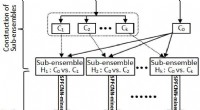
Uno de los desafíos clave es que los robots a menudo necesitan aprender a utilizar herramientas con diferentes orientaciones y tamaños. Además, deben comprender los efectos de sus acciones en los objetos que se manipulan, que pueden variar significativamente según la herramienta que se utilice.
Para superar estos desafíos, TL;DR utiliza una combinación de aprendizaje por refuerzo profundo y procesamiento del lenguaje natural. El algoritmo comienza aprendiendo una comprensión general de cómo interactúan las herramientas con los objetos a partir de un conjunto de demostraciones. Este conocimiento luego se utiliza para generar descripciones de texto de las acciones requeridas para tareas específicas, como "clavar el clavo en la madera" o "levantar la taza con el tenedor".
Una vez que se han generado las instrucciones de texto, TL;DR utiliza un modelo de procesamiento de lenguaje natural para extraer las acciones y objetos clave. Luego, estas acciones se representan utilizando el formato SMPL, una representación estándar para datos de movimiento.
Finalmente, el algoritmo utiliza un aprendizaje por refuerzo profundo para ajustar las acciones del robot en función de sus experiencias del mundo real. Esto permite que el robot se adapte a las variaciones del entorno y aprenda a utilizar las herramientas de forma eficaz.
En experimentos, los investigadores demostraron que TL;DR supera significativamente los enfoques existentes para el aprendizaje del uso de herramientas robóticas, particularmente cuando se trata de objetos y herramientas novedosos. El algoritmo también pudo aprender a utilizar herramientas complejas, como pinzas, para manipular objetos pequeños.
Los investigadores anticipan que TL;DR podría tener implicaciones importantes para las aplicaciones robóticas en diversos ámbitos, incluida la fabricación, la atención sanitaria y la exploración autónoma. Al permitir que los robots aprendan a utilizar herramientas de forma intuitiva, TL;DR puede ampliar la gama de tareas que los robots pueden realizar y reducir la necesidad de intervención humana.
El estudio fue coautor de Anirudha Parasuraman, Jialin Se y Peter Fazli. La investigación contó con el apoyo de ONR, NSF, Samsung, Toyota Research Institute y el MIT-IBM Watson AI Lab.