El modelo se puede entrenar sobre la marcha para generar imágenes de alta calidad en solo 12 segundos. Crédito:Bochang Moon del Instituto de Ciencia y Tecnología de Gwangju, Corea
Los gráficos por computadora de alta calidad, con su presencia omnipresente en juegos, ilustraciones y visualizaciones, se consideran lo último en tecnología de visualización.
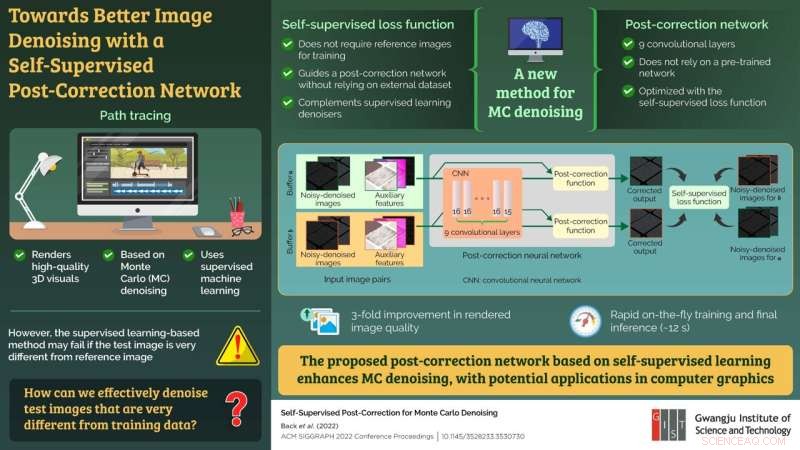
El método utilizado para generar imágenes realistas y de alta calidad se conoce como "trazado de ruta", que utiliza un enfoque de eliminación de ruido de Monte Carlo (MC) basado en el aprendizaje automático supervisado. En este marco de aprendizaje, el modelo de aprendizaje automático primero se entrena previamente con pares de imágenes ruidosas y limpias y luego se aplica a la imagen ruidosa real que se representará (imagen de prueba).
Si bien se considera el mejor enfoque en términos de calidad de imagen, es posible que este método no funcione bien si la imagen de prueba es muy diferente de las imágenes utilizadas para el entrenamiento.
Para abordar este problema, un grupo de investigadores, incluido Ph.D. el estudiante Jonghee Back y el profesor asociado Bochang Moon del Instituto de Ciencia y Tecnología de Gwangju en Corea, el científico investigador Binh-Son Hua de VinAI Research en Vietnam y el profesor asociado Toshiya Hachisuka de la Universidad de Waterloo en Canadá, propusieron, en un nuevo estudio, un nuevo método de eliminación de ruido de MC que no se basa en una referencia. Su estudio estuvo disponible en línea el 24 de julio de 2022 y se publicó en ACM SIGGRAPH 2022 Conference Proceedings .
"Los métodos existentes no solo fallan cuando los conjuntos de datos de prueba y entrenamiento son muy diferentes, sino que también lleva mucho tiempo preparar el conjunto de datos de entrenamiento para el entrenamiento previo de la red. Lo que se necesita es una red neuronal que se pueda entrenar solo con imágenes de prueba sobre la marcha sin necesidad para el preentrenamiento", dice el Dr. Moon, explicando la motivación detrás de su estudio.
Para lograr esto, el equipo propuso un nuevo enfoque de corrección posterior para una imagen sin ruido que comprendía un marco de aprendizaje automático autosupervisado y una red de corrección posterior, básicamente una red neuronal convolucional, para el procesamiento de imágenes. La red posterior a la corrección no dependía de una red previamente entrenada y podía optimizarse utilizando el concepto de aprendizaje autosupervisado sin depender de una referencia. Además, el modelo autosupervisado complementó e impulsó los modelos supervisados convencionales para la eliminación de ruido.
Para probar la eficacia de la red propuesta, el equipo aplicó su enfoque a los métodos de eliminación de ruido de última generación existentes. El modelo propuesto demostró una mejora triple en la calidad de la imagen renderizada en relación con la imagen de entrada al preservar los detalles más finos. Además, todo el proceso de entrenamiento sobre la marcha y la inferencia final tomó solo 12 segundos.
"Nuestro enfoque es el primero que no se basa en el entrenamiento previo utilizando un conjunto de datos externo. Esto, en efecto, acortará el tiempo de producción y mejorará la calidad del contenido basado en renderizado fuera de línea, como animación y películas", dice el Dr. Moon. , especulando sobre las posibles aplicaciones de su trabajo. Nuevo modelo básico mejora la precisión para la interpretación de imágenes de teledetección














