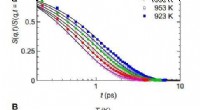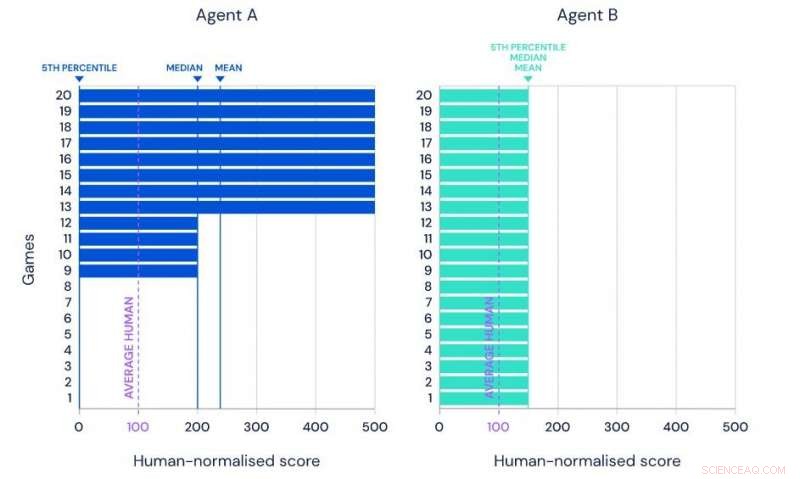
Ilustración de la media, rendimiento medio y percentil 5 de dos agentes hipotéticos en el mismo conjunto de referencia de 20 tareas. Crédito:Google
Para resolver mejor los desafíos complejos en los albores de la tercera década del siglo XXI, Alphabet Inc. ha aprovechado reliquias que datan de la década de 1980:los videojuegos.
La empresa matriz de Google informó esta semana que su unidad de inteligencia artificial DeepMind Technologies ha aprendido con éxito a jugar 57 videojuegos de Atari. Y el sistema informático funciona mejor que cualquier humano.
Atari, creador de Pong, uno de los primeros videojuegos exitosos de la década de 1970, pasó a popularizar muchos de los grandes videojuegos clásicos tempranos en la década de 1990. Los videojuegos se usan comúnmente con proyectos de inteligencia artificial porque desafían a los algoritmos para navegar por caminos y opciones cada vez más complejos, todo mientras se encuentra con escenarios cambiantes, amenazas y recompensas.
Apodado AGENT57, El sistema de inteligencia artificial de Alphabet examinó 57 juegos líderes de Atari que cubren una amplia gama de niveles de dificultad y diversas estrategias de éxito.
"Los juegos son un excelente campo de pruebas para crear algoritmos adaptativos, ", dijeron los investigadores en un informe en la página del blog de DeepMind." Proporcionan un rico conjunto de tareas que los jugadores deben desarrollar estrategias de comportamiento sofisticadas para dominar, pero también proporcionan una métrica de progreso fácil (puntuación del juego) para optimizar.
"El objetivo final no es desarrollar sistemas que destaquen en los juegos, sino más bien utilizar los juegos como un trampolín para desarrollar sistemas que aprendan a sobresalir en un amplio conjunto de desafíos, "decía el informe.
El sistema AlphaGo de DeepMind obtuvo un amplio reconocimiento en 2016 cuando venció al campeón mundial Lee Sedol en el juego estratégico de Go.
Entre la cosecha actual de 57 juegos de Atari, cuatro se consideran especialmente difíciles de dominar para los proyectos de IA:La venganza de Montezuma, Trampa, Solaris y Esquí. Los dos primeros juegos plantean lo que DeepMind llama el desconcertante "problema de exploración-explotación".
"Si uno sigue realizando comportamientos que sabe que funciona (explotar), ¿O debería uno probar algo nuevo (explorar) para descubrir nuevas estrategias que podrían ser aún más exitosas? ", pregunta DeepMind." Por ejemplo, si uno siempre pide su mismo plato favorito en un restaurante local, ¿O prueba algo nuevo que pueda superar al viejo favorito? La exploración implica tomar muchas acciones subóptimas para recopilar la información necesaria para descubrir un comportamiento en última instancia más fuerte ".
Los otros dos juegos desafiantes imponen largos tiempos de espera entre desafíos y recompensas, lo que dificulta el análisis exitoso de los sistemas de IA.
Los esfuerzos anteriores para dominar los cuatro juegos con IA fracasaron.
El informe dice que todavía hay margen de mejora. Para uno, Los tiempos de cálculo prolongados siguen siendo un problema. También, al tiempo que reconoce que "cuanto más se entrena, cuanto mayor sea su puntuación, "Los investigadores de DeepMind quieren que Agent57 funcione mejor. Quieren que domine varios juegos simultáneamente; actualmente, solo puede aprender un juego a la vez y debe realizar un entrenamiento cada vez que reinicia un juego.
Por último, Los investigadores de DeepMind prevén un programa que puede aplicar opciones de toma de decisiones similares a las de los humanos mientras se enfrentan a desafíos nunca antes vistos y en constante cambio.
"Verdadera versatilidad, que le resulta tan fácil a un niño humano, aún está mucho más allá del alcance de las IA, "concluyó el informe.
© 2020 Science X Network