Oier Mees demostrando cómo funciona el nuevo enfoque. Crédito:Mees et al.
Con más robots ahora abriéndose camino en una serie de configuraciones, los investigadores están tratando de hacer que sus interacciones con los humanos sean lo más fluidas y naturales posible. Capacitar a los robots para que respondan de inmediato a las instrucciones habladas. como "levanta el vaso, muévelo a la derecha, "etc., sería ideal en muchas situaciones, ya que en última instancia permitiría interacciones humano-robot más directas e intuitivas. Sin embargo, esto no siempre es fácil, ya que requiere que el robot comprenda las instrucciones de un usuario, pero también saber mover objetos de acuerdo con relaciones espaciales específicas.
Investigadores de la Universidad de Friburgo en Alemania han ideado recientemente un nuevo enfoque para enseñar a los robots a mover objetos según las instrucciones de los usuarios humanos. que funciona clasificando representaciones de escenas "alucinadas". Su papel prepublicado en arXiv, será presentado en la Conferencia Internacional IEEE sobre Robótica y Automatización (ICRA) en París, este junio.
"En nuestro trabajo, nos concentramos en las instrucciones de colocación de objetos relacionales, como 'coloque la taza a la derecha de la caja' o 'coloque el juguete amarillo encima de la caja, '"Oier Mees, uno de los investigadores que realizó el estudio, dijo a TechXplore. "Para hacerlo, el robot necesita razonar sobre dónde colocar la taza en relación con la caja o cualquier otro objeto de referencia para reproducir la relación espacial descrita por un usuario ".
Entrenar a los robots para que entiendan las relaciones espaciales y mover objetos en consecuencia puede ser muy difícil, ya que las instrucciones del usuario no suelen delinear una ubicación específica dentro de una escena más grande observada por el robot. En otras palabras, si un usuario humano dice "coloque la taza a la izquierda del reloj, "a qué distancia del reloj debe colocar el robot la taza y dónde está el límite exacto entre las diferentes direcciones (p. ej., Derecha, izquierda, en frente de, detrás, etc.)?
"Debido a esta ambigüedad inherente, Tampoco existe una verdad fundamental o datos 'correctos' que puedan usarse para aprender a modelar relaciones espaciales, ", Dijo Mees." Abordamos el problema de la falta de disponibilidad de las anotaciones de las relaciones espaciales de las relaciones espaciales de la verdad del terreno desde la perspectiva del aprendizaje auxiliar ".
La idea principal detrás del enfoque ideado por Mees y sus colegas es que cuando se les dan dos objetos y una imagen que representa el contexto en el que se encuentran, es más fácil determinar la relación espacial entre ellos. Esto permite a los robots detectar si un objeto está a la izquierda del otro, en lo alto de ello, en frente de eso, etc.
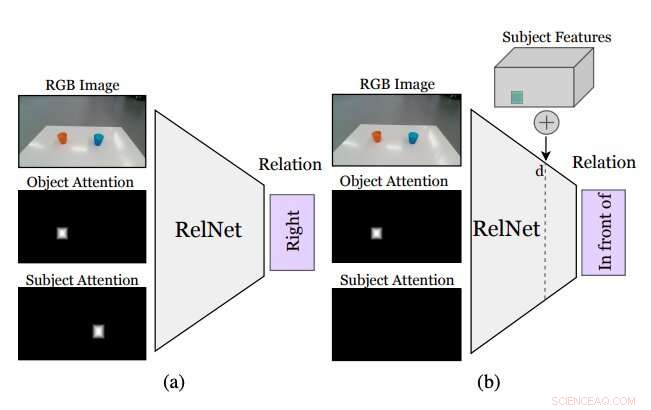
Figura que resume cómo funciona el enfoque ideado por los investigadores. Una CNN auxiliar, llamado RelNet, está entrenado para predecir relaciones espaciales dada la imagen de entrada y dos máscaras de atención que se refieren a dos objetos que forman una relación. (a) después del entrenamiento, la red puede ser "engañada" para clasificar escenas alucinadas mediante (b) la implementación de características de alto nivel de elementos en diferentes ubicaciones espaciales. Crédito:Mees et al.
Si bien la identificación de una relación espacial entre dos objetos no especifica dónde deben ubicarse los objetos para reproducir esa relación, la inserción de otros objetos dentro de la escena podría permitir al robot inferir una distribución sobre varias relaciones espaciales. Añadiendo estos inexistentes (es decir, objetos alucinados) a lo que el robot está viendo debería permitirle evaluar cómo se vería la escena si realizara una acción determinada (es decir, colocando uno de los objetos en un lugar específico de la mesa o superficie frente a él).
"Más comúnmente, 'pegar' objetos de manera realista en una imagen requiere acceso a modelos y siluetas 3D o diseñar cuidadosamente el procedimiento de optimización de las redes generativas adversarias (GAN), "Mees dijo." Además, "Pegar" ingenuamente máscaras de objetos en imágenes crea sutiles artefactos de píxeles que conducen a características notablemente diferentes y al entrenamiento se enfoca erróneamente en estas discrepancias. Adoptamos un enfoque diferente e implantamos características de alto nivel de los objetos en mapas de características de la escena generados por una red neuronal convolucional para alucinar las representaciones de la escena. que luego se clasifican como una tarea auxiliar para obtener la señal de aprendizaje ".
Antes de entrenar una red neuronal convolucional (CNN) para aprender relaciones espaciales basadas en objetos alucinados, los investigadores tenían que asegurarse de que fuera capaz de clasificar las relaciones entre pares individuales de objetos basándose en una sola imagen. Después, "engañaron" a su red, apodado RelNet, en la clasificación de escenas "alucinadas" mediante la implantación de características de alto nivel de elementos en diferentes ubicaciones espaciales.
"Nuestro enfoque permite que un robot siga las instrucciones de colocación en lenguaje natural dadas por usuarios humanos con una recopilación de datos o heurística mínima, "Mees dijo." A todo el mundo le gustaría tener un robot de servicio en casa que pueda realizar tareas mediante la comprensión de las instrucciones en lenguaje natural. Este es un primer paso para permitir que un robot comprenda mejor el significado de las preposiciones espaciales de uso común ".
La mayoría de los métodos existentes para entrenar a los robots para mover objetos utilizan información relacionada con las formas tridimensionales de los objetos para modelar relaciones espaciales por pares. Una limitación clave de estas técnicas es que a menudo requieren componentes tecnológicos adicionales, como los sistemas de seguimiento que pueden rastrear los movimientos de diferentes objetos. El enfoque propuesto por Mees y sus colegas, por otra parte, no requiere herramientas adicionales, ya que no se basa en técnicas de visión 3D.
Los investigadores evaluaron su método en una serie de experimentos en los que participaron robots y usuarios humanos reales. Los resultados de estas pruebas fueron muy prometedores, ya que su método permitió a los robots identificar de manera efectiva las mejores estrategias para colocar objetos en una mesa de acuerdo con las relaciones espaciales delineadas por las instrucciones habladas de un usuario humano.
"Nuestro enfoque novedoso de representaciones de escenas alucinantes también puede tener múltiples aplicaciones en las comunidades de robótica y visión por computadora, ya que a menudo los robots necesitan poder estimar qué tan bueno podría ser un estado futuro para razonar sobre las acciones que deben tomar, "Mees dijo." También podría utilizarse para mejorar el rendimiento de muchas redes neuronales, como redes de detección de objetos, mediante el uso de representaciones de escenas alucinadas como una forma de aumento de datos ".
Mees y sus colegas pudimos modelar un conjunto de preposiciones espaciales del lenguaje natural (por ejemplo, derecha, izquierda, encima de, etc.) de forma fiable y sin utilizar herramientas de visión 3D. En el futuro, el enfoque presentado en su estudio podría utilizarse para mejorar las capacidades de los robots existentes, permitiéndoles completar tareas simples de cambio de objetos de manera más efectiva mientras siguen las instrucciones habladas de un usuario humano.
Mientras tanto, su artículo podría informar el desarrollo de técnicas similares para mejorar las interacciones entre humanos y robots durante otras tareas de manipulación de objetos. Si se combina con métodos de aprendizaje auxiliares, El enfoque desarrollado por Mees y sus colegas también puede reducir los costos y esfuerzos asociados con la compilación de conjuntos de datos para la investigación robótica. ya que permite la predicción de probabilidades por píxeles sin requerir grandes conjuntos de datos anotados.
"Creemos que este es un primer paso prometedor para permitir un entendimiento compartido entre humanos y robots, "Concluyó Mees". En el futuro, queremos ampliar nuestro enfoque para incorporar una comprensión de las expresiones de referencia, con el fin de desarrollar un sistema de selección y colocación que siga las instrucciones del lenguaje natural ".
© 2020 Science X Network