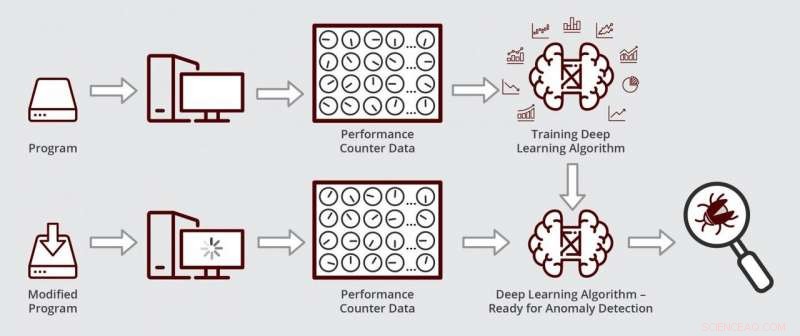
Esquema que ilustra cómo funciona el algoritmo de aprendizaje profundo de Muzahid. El algoritmo está listo para la detección de anomalías después de que se entrena por primera vez con los datos del contador de rendimiento de una versión libre de errores de un programa. Crédito:Ingeniería de Texas A&M
Todos hemos compartido la frustración:las actualizaciones de software destinadas a hacer que nuestras aplicaciones se ejecuten más rápido, sin darnos cuenta, terminan haciendo todo lo contrario. Estos bichos denominado en el campo de la informática como regresiones de rendimiento, requieren mucho tiempo para solucionarlos, ya que la localización de errores de software normalmente requiere una intervención humana sustancial.
Para superar este obstáculo, investigadores de la Universidad de Texas A&M, en colaboración con científicos informáticos de Intel Labs, ahora han desarrollado una forma completamente automatizada de identificar la fuente de errores causados por las actualizaciones de software. Su algoritmo, basado en una forma especializada de aprendizaje automático llamada aprendizaje profundo, no es solo llave en mano, pero también rápido, encontrar errores de rendimiento en unas pocas horas en lugar de días.
"La actualización de software a veces puede volverse en su contra cuando aparecen errores y causan ralentizaciones. Este problema es aún más exagerado para las empresas que utilizan sistemas de software a gran escala que evolucionan continuamente, "dijo el Dr. Abdullah Muzahid, profesor asistente en el Departamento de Ingeniería y Ciencias de la Computación. "Hemos diseñado una herramienta conveniente para diagnosticar regresiones de rendimiento que es compatible con una amplia gama de software y lenguajes de programación, expandiendo enormemente su utilidad ".
Los investigadores describieron sus hallazgos en la 32ª edición de Advances in Neural Information Processing Systems de las actas de la conferencia Neural Information Processing Systems en diciembre.
Para identificar la fuente de errores dentro del software, los depuradores a menudo verifican el estado de los contadores de rendimiento dentro de la unidad central de procesamiento. Estos contadores son líneas de código que monitorean cómo se está ejecutando el programa en el hardware de la computadora en la memoria. por ejemplo. Entonces, cuando se ejecuta el software, Los contadores realizan un seguimiento del número de veces que accede a determinadas ubicaciones de memoria, el tiempo que se queda ahí y cuando sale, entre otras cosas. Por eso, cuando el comportamiento del software falla, Los contadores se utilizan de nuevo para el diagnóstico.
"Los contadores de rendimiento dan una idea del estado de ejecución del programa, "dijo Muzahid." Entonces, si algún programa no se está ejecutando como debería, estos contadores suelen tener el signo revelador de un comportamiento anómalo ".
Sin embargo, los servidores y escritorios más nuevos tienen cientos de contadores de rendimiento, lo que hace que sea prácticamente imposible realizar un seguimiento de todos sus estados manualmente y luego buscar patrones aberrantes que sean indicativos de un error de rendimiento. Ahí es donde entra en juego el aprendizaje automático de Muzahid.
Al utilizar el aprendizaje profundo, los investigadores pudieron monitorear los datos provenientes de una gran cantidad de contadores simultáneamente al reducir el tamaño de los datos, que es similar a comprimir una imagen de alta resolución a una fracción de su tamaño original cambiando su formato. En los datos dimensionales inferiores, su algoritmo podría entonces buscar patrones que se desvíen de lo normal.
Cuando su algoritmo estuvo listo, los investigadores probaron si podía encontrar y diagnosticar un error de rendimiento en un software de gestión de datos disponible comercialmente utilizado por las empresas para realizar un seguimiento de sus números y cifras. Primero, entrenaron su algoritmo para reconocer datos de contador normales ejecutando un versión sin fallos del software de gestión de datos. Próximo, ejecutaron su algoritmo en una versión actualizada del software con la regresión de rendimiento. Descubrieron que su algoritmo localizó y diagnosticó el error en unas pocas horas. Muzahid dijo que este tipo de análisis podría llevar una cantidad considerable de tiempo si se realiza manualmente.
Además de diagnosticar regresiones de rendimiento en software, Muzahid señaló que su algoritmo de aprendizaje profundo también tiene usos potenciales en otras áreas de investigación, como desarrollar la tecnología necesaria para la conducción autónoma.
"La idea básica es una vez más la misma, que es capaz de detectar un patrón anómalo, "Dijo Muzahid." Los autos autónomos deben ser capaces de detectar si hay un automóvil o un ser humano frente a ellos y luego actuar en consecuencia. Entonces, nuevamente es una forma de detección de anomalías y la buena noticia es que es para lo que nuestro algoritmo ya está diseñado ".
Otros contribuyentes a la investigación incluyen al Dr. Mejbah Alam, Dr. Justin Gottschlich, Dra. Nesime Tatbul, Dr. Javier Turek y Dr. Timothy Mattson de Intel Labs.














