
Crédito:Gupta et al.
El aprendizaje por refuerzo (RL) es una técnica de aprendizaje automático ampliamente utilizada que implica entrenar a agentes o robots de IA mediante un sistema de recompensa y castigo. Hasta aquí, Los investigadores en el campo de la robótica han aplicado principalmente técnicas de RL en tareas que se completan en períodos de tiempo relativamente cortos. como moverse hacia adelante o agarrar objetos.
Un equipo de investigadores de Google y Berkeley AI Research ha desarrollado recientemente un nuevo enfoque que combina RL con aprendizaje por imitación, un proceso llamado aprendizaje de políticas de relevo. Este enfoque, presentado en un artículo prepublicado en arXiv y presentado en la Conferencia sobre aprendizaje de robots (CoRL) 2019 en Osaka, se puede utilizar para capacitar a agentes artificiales para abordar tareas de múltiples etapas y de largo plazo, como las tareas de manipulación de objetos que abarcan períodos de tiempo más largos.
"Nuestra investigación se originó en muchos, en su mayoría sin éxito, experimentos con tareas muy largas utilizando aprendizaje por refuerzo (RL), "Abhishek Gupta, uno de los investigadores que realizó el estudio, dijo a TechXplore. "Hoy dia, RL en robótica se aplica principalmente en tareas que se pueden realizar en un corto período de tiempo, como agarrar, empujando objetos, caminando hacia adelante, etc. Si bien estas aplicaciones tienen mucho valor, Nuestro objetivo era aplicar el aprendizaje por refuerzo a tareas que requieren múltiples subobjetivos y operan en escalas de tiempo mucho más largas. como poner una mesa o limpiar una cocina ".
Antes de que comenzaran a desarrollar su enfoque, Gupta y sus colegas revisaron la literatura previa para tratar de determinar por qué las tareas más largas son particularmente difíciles de abordar con las técnicas actuales de RL. En su papel sugieren que, en general, hay dos razones principales para ello.
Primero, Es difícil para un robot identificar las soluciones óptimas para resolver tareas largas y complejas por sí solo. Segundo, Es difícil para el agente abordar con éxito una tarea larga para la que se proporciona retroalimentación solo al final de una secuencia larga. Retransmitir el aprendizaje de políticas, el nuevo enfoque de aprendizaje que presentaron, está diseñado para abordar ambos desafíos de frente.
Crédito:Gupta et al.
"Para abordar el desafío de que los robots resuelvan tareas de largo plazo por sí mismos, decidimos simplificar el problema y utilizar demostraciones proporcionadas por humanos, ", Dijo Gupta." Resolver tareas largas es difícil porque es extremadamente difícil que un robot descubra un comportamiento interesante por sí solo; las demostraciones proporcionadas por humanos se pueden usar como una guía para hacer cosas interesantes en un entorno ".
El enfoque para el aprendizaje de robots propuesto por Gupta y sus colegas tiene dos etapas distintas, uno en el que un agente aprende imitando a los humanos y el otro basado en RL. En la etapa de aprendizaje de imitación, un robot se alimenta de demostraciones humanas de cómo completar una tarea y produce políticas jerárquicas condicionadas por objetivos.
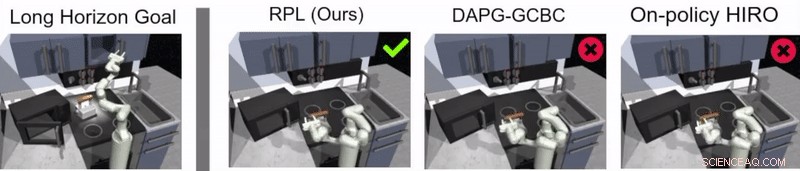
En su estudio, Los investigadores utilizaron su enfoque para entrenar a un agente artificial llamado Franka en tareas de manipulación de múltiples etapas y de largo plazo en un entorno de cocina simulado. que fue modelado usando la plataforma de simuladores de física MuJoCo. Este ambiente consistía en una cocina con un microondas que se podía abrir, cuatro quemadores de horno, un interruptor de luz del horno, un hervidor, dos gabinetes con bisagras y una puerta corrediza.

Crédito:Gupta et al.
"En tono rimbombante, aprender solo de las demostraciones no es suficiente para resolver las tareas desafiantes en nuestro entorno de cocina simulado, "Karol Hausman, otro investigador involucrado en el estudio, dijo a TechXplore. "Para mejorar esta solución inicial, permitimos que los robots practiquen las tareas por sí mismos para perfeccionar aún más sus comportamientos ".
Esencialmente, utilizando el método de aprendizaje de políticas de relevo propuesto por los investigadores, un agente aprende inicialmente procesando demostraciones humanas de cómo completar una tarea determinada y luego continúa aprendiendo por sí solo a través de RL. Facilitar el proceso de aprendizaje de políticas a largo plazo, el equipo utilizó un nuevo algoritmo de reetiquetado de datos que permite a un agente aprender políticas jerárquicas condicionadas por objetivos.
"Para hacer frente al desafío de la escasa retroalimentación, utilizamos una estructura jerárquica para nuestras políticas de control:la política de alto nivel propone metas que la política de bajo nivel intenta lograr, por ejemplo, cerrar un armario, apaga el quemador, etc., "Explicó Hausman." De esta manera, la tarea se puede descomponer fácilmente en subproblemas más pequeños que se pueden resolver con el aprendizaje por refuerzo de las demostraciones proporcionadas por humanos ".

Crédito:Gupta et al.
Guppta, Hausman y sus colegas evaluaron la efectividad del aprendizaje de políticas de retransmisión para entrenar robots en tareas de largo plazo dentro del entorno de cocina simulado que crearon. logrando resultados muy prometedores. Descubrieron que con la estructura de políticas y los datos de demostración adecuados, su enfoque permitió a los robots abordar tareas con un horizonte mucho más largo de lo que inicialmente creyeron posible.
"Esperamos que nuestros hallazgos puedan abrir nuevas vías para combinar la investigación de aprendizaje por imitación y refuerzo y nos brinde una dirección potencial que pueda permitir que los robots funcionen durante mucho tiempo". tareas complejas, "Dijo Hausman.
En el futuro, el enfoque de aprendizaje de políticas de relevo introducido por Gupta, Hausman y sus colegas podrían usarse para entrenar robots en una gama más amplia de tareas a largo plazo. Hasta ahora, los investigadores solo han probado su técnica en un entorno simulado; por lo tanto, Sería interesante evaluarlo en entornos del mundo real y ver si logra resultados igualmente prometedores.
"Como siguiente paso, nos gustaría analizar el problema de la generalización más allá de los datos de demostración, "Dijo Hausman." Eventualmente, también nos gustaría mejorar aún más la eficiencia de datos de nuestro método, pasar a las observaciones de píxeles y permitir el aprendizaje del mundo real en un robot físico ".
© 2019 Science X Network














