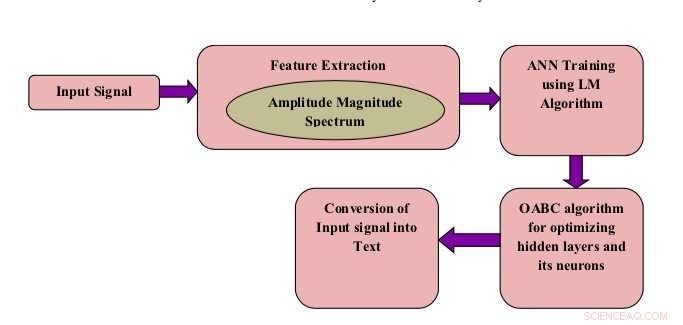
Diagrama de bloques del modelo propuesto. Crédito:Shukla &Jain.
Durante la última década más o menos, Los avances en el aprendizaje automático han allanado el camino para el desarrollo de herramientas de reconocimiento de voz cada vez más avanzadas. Analizando archivos de audio del habla humana, estas herramientas pueden aprender a identificar palabras y frases en diferentes idiomas, convertirlos a un formato legible por máquina.
Si bien varios modelos basados en el aprendizaje automático han logrado resultados prometedores en las tareas de reconocimiento de voz, no siempre funcionan bien en todos los idiomas. Por ejemplo, cuando un idioma tiene un vocabulario con muchas palabras que suenan similares, el rendimiento de los sistemas de reconocimiento de voz puede disminuir considerablemente.
Investigadores de la Facultad de Ingeniería y Tecnología de la Misión Mahatma Gandhi y del Instituto de Tecnología de la Información Jaypee, En India, han desarrollado un sistema de reconocimiento de voz para abordar este problema. Este nuevo sistema, presentado en un artículo publicado en Springer Link's Revista internacional de tecnología del habla , combina una red neuronal artificial (ANN) con una técnica de optimización conocida como colonia de abejas artificial de oposición (OABC).
"En este trabajo, la estructura predeterminada de las ANN se rediseña utilizando el algoritmo de Levenberg-Marquardt para recuperar una tasa de predicción óptima con precisión, "Los investigadores escribieron en su artículo." Las capas ocultas y las neuronas de las capas ocultas se optimizan aún más utilizando la técnica de optimización de colonias de abejas artificiales de oposición ".
Una característica única del sistema desarrollado por los investigadores es que utiliza un algoritmo de optimización OABC para optimizar las capas de la ANN y las neuronas artificiales. Como sugiere el nombre, Los algoritmos de colonia de abejas artificiales (ABC) están diseñados para simular el comportamiento de las abejas melíferas para abordar una variedad de problemas de optimización.
"Generalmente, los algoritmos de optimización inicializan aleatoriamente las soluciones en el dominio coincidente, "explicaron los investigadores en su artículo." Pero esta solución podría ir en la dirección opuesta a la mejor solución, aumentando así la sobrecarga computacional de manera significativa. Por lo tanto, esta inicialización basada en la oposición se denomina OABC ".
El sistema desarrollado por los investigadores considera las palabras individuales pronunciadas por diferentes personas como una señal de entrada de voz. Después, extrae las llamadas características del espectrograma de modulación de amplitud (AM), que son esencialmente características específicas del sonido.
Las características extraídas por el modelo se utilizan para entrenar a la ANN para que reconozca el habla humana. Después de entrenarlo en una gran base de datos de archivos de audio, la ANN aprende a predecir palabras aisladas en nuevas muestras de habla humana.
Los investigadores probaron su sistema en una serie de clips de audio de voz humana y lo compararon con técnicas de reconocimiento de voz más convencionales. Su técnica superó a todos los demás métodos, logrando notables puntuaciones de precisión.
"La sensibilidad, especificidad, y la precisión del método propuesto es del 90,41 por ciento, 99,66 por ciento y 99,36 por ciento, respectivamente, que es mejor que todos los métodos existentes, "escribieron los investigadores en su artículo.
En el futuro, el sistema de reconocimiento de voz podría utilizarse para lograr una comunicación hombre-máquina más eficaz en una variedad de entornos. Además, el enfoque que utilizaron para desarrollar el sistema podría inspirar a otros equipos a diseñar modelos similares, que combinan técnicas de optimización de ANN y OABC.
© 2019 Science X Network














