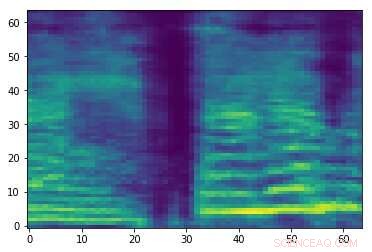
Espectrograma de una señal de audio aleatoria. Crédito:Esmailpour, Cardenal y Lemeiras Koerich.
Los ataques de audio adversarios son pequeñas perturbaciones que los humanos no perciben y que se agregan intencionalmente a las señales de audio para afectar el rendimiento de los modelos de aprendizaje automático (ML). Estos ataques generan serias preocupaciones sobre la seguridad de los modelos de ML, ya que pueden hacer que cometan errores y, en última instancia, generar predicciones erróneas.
Investigadores de la École de Technologie Supérieure, parte de la Universidad de Quebec en Canadá ha desarrollado recientemente un nuevo enfoque que podría ayudar a proteger las herramientas de clasificación de audio contra ataques adversarios. En su papel prepublicado en arXiv, revisan algunos de los ataques adversarios existentes más fuertes y su impacto en el rendimiento de los modelos de ML comunes, luego proponga un enfoque que pueda contrarrestar estos ataques.
"En este momento, hay muchos clasificadores fuertes y rápidos (en tiempo de ejecución) en términos de precisión, a saber, clasificadores de aprendizaje profundo (por ejemplo, redes neuronales convolucionales), que incluso puede superar el nivel humano de los medios (por ejemplo, habla, imagen, video, animación, texto, etc.) reconocimiento y regresión, "Mohammad Esmaeilpour, uno de los investigadores que realizó el estudio, dijo a TechXplore. "El talón de Aquiles de estos algoritmos avanzados es su vulnerabilidad a las entradas que contienen perturbaciones cuidadosamente diseñadas, conocidos como ataques adversarios ".
Los ataques contradictorios funcionan produciendo muestras que se asemejan mucho a muestras de entrenamiento legítimas, pero que en realidad llevan a un modelo o modelos de ML a generar etiquetas incorrectas con altos niveles de confianza. En la investigación de ML, si hay suficientes datos para entrenar a un clasificador, el desafío clave ya no es mejorar su precisión de reconocimiento, pero asegurando su resistencia contra ataques adversarios.
"Los ataques contradictorios son amenazas activas para todos los algoritmos basados en datos, incluso aquellos capacitados en pequeños conjuntos de datos, ", Dijo Esmaeilpour." Esto despertó nuestro interés en estudiar la amenaza de ataques adversarios para aplicaciones de reconocimiento de voz y audio, Dado que todos los teléfonos inteligentes ahora están equipados con un asistente de voz virtual como Siri, Asistente de Google y Cortana ".
En su estudio, Esmaeilpour y sus colegas llevaron a cabo experimentos con conjuntos de datos de audio ambiental, en lugar de conjuntos de datos de voz. Sin embargo, en el futuro, su enfoque también podría extenderse al reconocimiento de voz, lo que ayudaría a proteger a los asistentes de voz contra ataques adversarios.
Espectrograma adversario elaborado asociado con la señal de audio en la primera imagen. Si bien las dos imágenes son similares, tienen diferentes etiquetas, sugiriendo que se está produciendo un ataque. Crédito:Esmailpour, Cardenal y Lemeiras Koerich.
"Nuestro principal objetivo en este documento fue estudiar la amenaza de los ataques adversarios para clasificadores de audio convencionales y de aprendizaje profundo y, idealmente, proponer un algoritmo más confiable en términos de resistencia contra algunos ataques comunes como base para una clasificación de audio realmente sólida, "Explicó Esmaeilpour." Queríamos hacer un equilibrio justo para los clasificadores en la precisión del reconocimiento, complejidad computacional, y robustez frente a los ataques adversarios ".
Generalmente, Los clasificadores que son más robustos contra los ataques adversarios alcanzan una menor precisión de reconocimiento, y viceversa. En su estudio, los investigadores se centraron en el reentrenamiento adversario, una de las técnicas de defensa existentes más válidas que no ofusca la información del gradiente. A pesar de sus beneficios, esta estrategia de defensa en particular es costosa (ya que los ataques fuertes son costosos, El reentrenamiento adversario usando estos ataques será más costoso) y puede afectar negativamente el desempeño de reconocimiento de un clasificador.
"El caso ideal para nosotros sería proponer un clasificador de audio sin gradiente de ofuscación y sin reentrenamiento adversario que aprenda inherentemente 'características robustas', "Esmaeilpour dijo." Nuestro escenario de clasificación incluye varios pasos, principalmente mejora del espectrograma (representación 2D para señales de audio), reducción de dimensionalidad utilizando una técnica de descomposición algebraica, y suavizado mediante el uso de un codificador automático de eliminación de ruido convolucional, donde los dos últimos pasos (apilados juntos) han mostrado impactos positivos en la eliminación de pequeñas perturbaciones adversas potenciales desconocidas ".
Después de revisar algunos de los ataques adversarios más fuertes que existen y sus efectos en el rendimiento de los modelos de AA, los investigadores extrajeron características de los espectrogramas procesados por los modelos, los organizó en un libro de códigos y entrenó un algoritmo de máquina de vectores de soporte (SVM) en este libro de códigos. En su línea de formación, no implementaron técnicas de detección de ataques adversarios proactivos o reactivos ni algoritmos de defensa.
"Nuestro objetivo principal era 'aprender vectores de características robustos' sin ninguna sobrecarga previa o posterior al procesamiento para detectar posibles muestras adversas, "Esmaeilpour explicó." Nuestros resultados muestran que nuestro clasificador propuesto supera el aprendizaje profundo de última generación y los algoritmos convencionales contra cinco tipos de fuertes ataques adversarios para algunos conjuntos de datos de audio ambientales prácticos ".
Esmaeilpour y sus colegas demostraron estadísticamente la vulnerabilidad de los clasificadores convencionales (es decir, los clasificadores que aprenden del espacio de características) y los algoritmos de aprendizaje profundo (es decir, los algoritmos que aprenden de los datos sin procesar) contra los ataques adversarios. Según los investigadores, Actualmente no existe un algoritmo confiable basado en datos para la clasificación de audio que también sea robusto contra los ataques adversarios. Entre los modelos existentes, Los enfoques basados en el aprendizaje profundo parecen ser los menos seguros contra estos ataques, incluso si normalmente alcanzan la máxima precisión de reconocimiento.
"El escenario de clasificación que propusimos en nuestro artículo utiliza un SVM con kernel polinomial como clasificador final, "Dijo Esmaeilpour." Sin embargo, la aplicación de un codificador automático de eliminación de ruido convolucional en la parte superior de la descomposición de valores singulares seguida de un agrupamiento no supervisado de vectores de características robustas extraídas y aceleradas podría ayudar a aprender más componentes estructurales y probablemente características robustas, lo que podría permitirnos alcanzar un equilibrio razonable entre la precisión del reconocimiento (comparable al rendimiento de vanguardia) y la solidez frente a cinco fuertes ataques adversarios comunes ".
Si bien los resultados recopilados por los investigadores son muy prometedores, pueden variar según el conjunto de datos utilizado o la aplicación específica de un clasificador, de ahí que aún no sean generalizables. En el futuro, su estudio podría informar el desarrollo de otros clasificadores mejor equipados contra ataques adversarios, sin presentar pérdidas sustanciales en el desempeño (es decir, precisión de reconocimiento).
"El aprendizaje de funciones sólidas es un problema abierto y todavía no tenemos una idea clara de cómo abordarlo correctamente; nuestro equipo de investigación lo está estudiando y pronto se publicarán algunos resultados, "Dijo Esmaeilpour." Mientras tanto, estamos trabajando en una nueva, técnica de ataque adversarial fuerte y rápido destinada a utilizar este ataque para entrenar adversamente el modelo de aprendizaje (lo que mejora su robustez) y también guardar el rendimiento de reconocimiento del modelo antes de entrenarlo ".
© 2019 Science X Network