Esto puede parecer un bocado, pero realmente significa mucho. Mozilla habla del "mayor conjunto de datos de voz transcrita de dominio público hasta la fecha". Traducción:Mayores de 14, 000 personas. En 18 idiomas. De casi 1, 400 horas (1, 368 para ser exactos) de voz grabada. Bienvenido a una iniciativa denominada Common Voice.
Esto es lo que decía el anuncio de Mozilla, en forma de blog el jueves de George Roter.
"Hoy dia, nos complace compartir nuestro primer conjunto de datos en varios idiomas con 18 idiomas representados, incluido el inglés, Francés, Alemán y chino mandarín (tradicional), pero también, por ejemplo, galés y kabyle. En total, el nuevo conjunto de datos incluye aproximadamente 1, 400 horas de clips de voz de más de 42, 000 personas ".
Los colaboradores del proyecto tienen especialidades profesionales que van desde candidatos a doctorado en reconocimiento de voz hasta científicos de aprendizaje automático y un profesor de lingüística computacional. Como tal, el esfuerzo representa una comunidad global de colaboradores de voz junto con lo que Mozilla acreditó como "voluntarios apasionados".
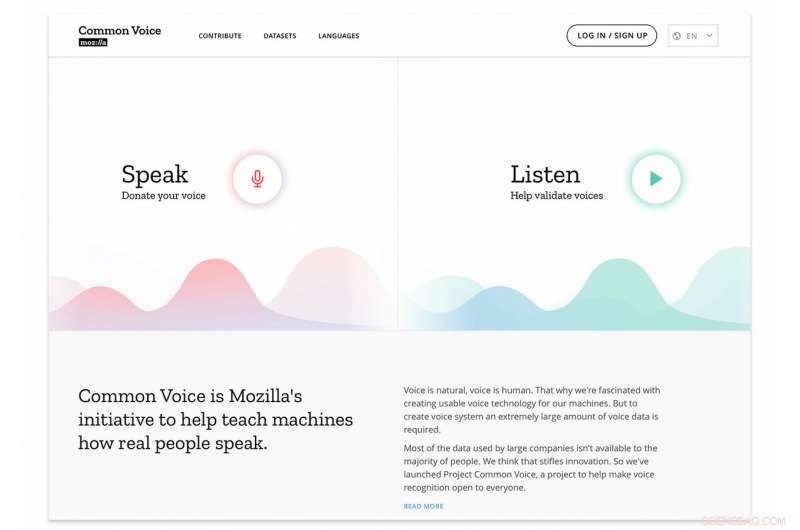
El propósito de Common Voice es ayudar a enseñar a las máquinas cómo habla la gente real. En breve, se ha convertido en una colección masiva de clips de voz en docenas de idiomas. Lo que sigue:el conjunto de datos completo estará disponible para descargar en el sitio de Common Voice.
Parece que los colaboradores del equipo de Mozilla también resolvieron los inevitables puntos débiles. El blog mencionó esos puntos. "Las personas que contribuyen no solo ven el progreso por idioma en la grabación y validación, pero también tienen indicaciones mejoradas que varían de un clip a otro; nueva funcionalidad para revisar, volver a grabar, y omitir clips como parte integral de la experiencia; la capacidad de moverse rápidamente entre hablar y escuchar; así como una función para optar por no participar en una sesión ".
Suena divertido o un sandbox académico, pero en realidad hay aspiraciones más sólidas entre quienes han contribuido a construir su corpus.
En 2019, Mariella Moon en Engadget ha notado la variedad de idiomas que ahora incluyen el holandés, Hakha-Chin, Esperanto, Farsi Vasco, Español, Francés, Alemán, Chino mandarín (tradicional), Galés y Kabyle.
TechRadar Olivia Tambini, dijo, "Al proporcionar una enorme biblioteca de voces humanas en una variedad de idiomas de forma gratuita, Mozilla podría estar abriendo las puertas a empresas que no tienen los recursos de Apple, Amazonas, y Google, para desarrollar sus propios asistentes de voz ".
Otro beneficio involucra a Mozilla en sí. Mariella Moon en Engadget dijo, "La propia organización planea utilizar los clips que recopila para mejorar su Speech-to-Text, Motores de texto a voz y DeepSpeech ".
Roter dijo:simple y llanamente, "Nuestro objetivo es lanzar productos habilitados por voz nosotros mismos, al mismo tiempo que apoya a investigadores y actores más pequeños ".
Tenga en cuenta que los derechos de fanfarronear pertenecen a que es el más grande, no el único, conjunto de datos de este tipo. Mozilla quería que los visitantes del sitio supieran que era el más grande, no el único, y también dijo que con el tiempo los visitantes del sitio pueden "mirar esta página como un centro de referencia para otros conjuntos de datos de voz de código abierto".
Si visita el sitio de Common Voice, recibirá el mensaje sobre su gran ambición. "Estamos construyendo ", dijo Mozilla. ¿Y qué están construyendo? Un" código abierto, conjunto de datos de voces en varios idiomas que cualquiera puede usar para entrenar aplicaciones habilitadas para voz ".
Los colaboradores pueden optar por proporcionar metadatos como su edad, sexo, y acento. Los clips de voz, a su vez, están etiquetados con información útil para entrenar motores de voz.
© 2019 Science X Network