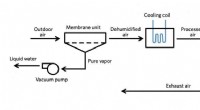
Un nuevo método para decodificar los procesos de toma de decisiones utilizados por los algoritmos de aprendizaje automático de 'caja negra' funciona al encontrar la entrada mínima que aún dará una respuesta correcta. En este ejemplo, los investigadores primero presentaron un algoritmo con una foto de un girasol y preguntaron "¿De qué color es la flor?" Esto resultó en la respuesta correcta, 'amarillo.' Los investigadores descubrieron que podían obtener la misma respuesta correcta, con un grado de confianza igualmente alto, haciendo al algoritmo una pregunta de una sola palabra:"¿Flor?" Crédito:Shi Feng / Universidad de Maryland
Inteligencia artificial, específicamente, aprendizaje automático:es parte de la vida diaria de los usuarios de computadoras y teléfonos inteligentes. Desde la autocorrección de errores tipográficos hasta la recomendación de música nueva, Los algoritmos de aprendizaje automático pueden ayudar a hacer la vida más fácil. También pueden cometer errores.
Puede ser un desafío para los informáticos descubrir qué salió mal en tales casos. Esto se debe a que muchos algoritmos de aprendizaje automático aprenden de la información y hacen sus predicciones dentro de una "caja negra virtual, "dejando pocas pistas para que las sigan los investigadores.
Un grupo de informáticos de la Universidad de Maryland ha desarrollado un nuevo enfoque prometedor para interpretar algoritmos de aprendizaje automático. A diferencia de los esfuerzos anteriores, que normalmente buscaba "romper" los algoritmos eliminando palabras clave de las entradas para dar una respuesta incorrecta, en cambio, el grupo UMD redujo las entradas al mínimo requerido para obtener la respuesta correcta. De media, los investigadores obtuvieron la respuesta correcta con una entrada de menos de tres palabras.
En algunos casos, Los algoritmos modelo de los investigadores proporcionaron la respuesta correcta basada en una sola palabra. Frecuentemente, la palabra o frase de entrada parecía tener poca conexión obvia con la respuesta, revelando información importante sobre cómo reaccionan algunos algoritmos a un lenguaje específico. Debido a que muchos algoritmos están programados para dar una respuesta pase lo que pase, incluso cuando se lo solicite una entrada sin sentido, los resultados podrían ayudar a los científicos informáticos a construir algoritmos más efectivos que puedan reconocer sus propias limitaciones.
Los investigadores presentarán su trabajo el 4 de noviembre 2018 en la Conferencia de 2018 sobre métodos empíricos en el procesamiento del lenguaje natural.
"Los modelos de caja negra parecen funcionar mejor que los modelos más simples, como árboles de decisión, pero incluso las personas que escribieron el código inicial no pueden saber exactamente qué está sucediendo, "dijo Jordan Boyd-Graber, el autor principal del estudio y profesor asociado de informática en la UMD. "Cuando estos modelos devuelven respuestas incorrectas o sin sentido, es difícil averiguar por qué. Así que en vez, tratamos de encontrar la entrada mínima que produjera el resultado correcto. La entrada promedio fue de unas tres palabras, pero podríamos reducirlo a una sola palabra en algunos casos ".
Crédito:CC0 Public Domain
En un ejemplo, los investigadores ingresaron una foto de un girasol y la pregunta basada en texto, "¿De qué color es la flor?" como entradas en un algoritmo de modelo. Estas entradas arrojaron la respuesta correcta de "amarillo". Después de reformular la pregunta en varias combinaciones cortas diferentes de palabras, los investigadores encontraron que podían obtener la misma respuesta con "¿flor?" como la única entrada de texto para el algoritmo.
En otro, ejemplo más complejo, los investigadores utilizaron la indicación, "En 1899, John Jacob Astor IV invirtió $ 100, 000 para que Tesla desarrolle y produzca un nuevo sistema de iluminación. En lugar de, Tesla utilizó el dinero para financiar sus experimentos en Colorado Springs ".
Luego le preguntaron al algoritmo, "¿En qué gastó Tesla el dinero de Astor?" y recibió la respuesta correcta, "Experimentos de Colorado Springs". Reducir esta entrada a una sola palabra "hizo" arrojó la misma respuesta correcta.
El trabajo revela información importante sobre las reglas que los algoritmos de aprendizaje automático aplican a la resolución de problemas. Muchos problemas del mundo real con los algoritmos surgen cuando una entrada que tiene sentido para los humanos da como resultado una respuesta sin sentido. Al mostrar que lo contrario también es posible, que las entradas sin sentido también pueden producir resultados correctos, Respuestas sensatas:Boyd-Graber y sus colegas demuestran la necesidad de algoritmos que puedan reconocer cuándo responden a una pregunta sin sentido con un alto grado de confianza.
"La conclusión es que todas estas cosas sofisticadas de aprendizaje automático pueden ser bastante estúpidas, "dijo Boyd-Graber, quien también tiene nombramientos conjuntos en el Instituto de Estudios Informáticos Avanzados de la Universidad de Maryland (UMIACS), así como en el Centro de Ciencias del Lenguaje y la Facultad de Estudios de la Información de la UMD. "Cuando los científicos informáticos entrenan estos modelos, normalmente solo les mostramos preguntas reales u oraciones reales. No les mostramos frases sin sentido ni palabras sueltas. Los modelos no saben que estos ejemplos deberían confundirlos ".
La mayoría de los algoritmos se obligarán a sí mismos a dar una respuesta, incluso con datos insuficientes o contradictorios, según Boyd-Graber. Esto podría estar en el corazón de algunos de los resultados incorrectos o sin sentido generados por los algoritmos de aprendizaje automático, en los algoritmos de modelo utilizados para la investigación, así como algoritmos del mundo real que nos ayudan al marcar el correo electrónico no deseado u ofrecer direcciones de conducción alternativas. Comprender más sobre estos errores podría ayudar a los científicos informáticos a encontrar soluciones y crear algoritmos más fiables.
"Demostramos que se puede entrenar a los modelos para que sepan que deben confundirse, ", Dijo Boyd-Graber." Entonces pueden simplemente salir y decir:'Me has mostrado algo que no puedo entender' ".