Mensaje que se muestra a los médicos para que realicen anotaciones. Crédito:IBM
Los últimos tiempos han sido testigos de un progreso significativo en la comprensión del lenguaje natural por parte de la IA, como traducción automática y respuesta a preguntas. Una razón vital detrás de estos desarrollos es la creación de conjuntos de datos, que utilizan modelos de aprendizaje automático para aprender y realizar una tarea específica. La construcción de tales conjuntos de datos en el dominio abierto a menudo consiste en texto proveniente de artículos de noticias. Esto suele ir seguido de la recopilación de anotaciones humanas de plataformas de colaboración colectiva como Crowdflower, o Amazon Mechanical Turk.
Sin embargo, El lenguaje utilizado en dominios especializados como la medicina es completamente diferente. El vocabulario utilizado por un médico al escribir una nota clínica es bastante diferente a las palabras de un artículo de noticias. Por lo tanto, Las tareas de lenguaje en estos dominios de conocimiento intensivo no pueden ser de fuentes múltiples, ya que tales anotaciones exigen experiencia en el dominio. Sin embargo, La recopilación de anotaciones de expertos en dominios también es muy costosa. Es más, Los datos clínicos son sensibles a la privacidad y, por lo tanto, no se pueden compartir fácilmente. Estos obstáculos han inhibido la contribución de conjuntos de datos lingüísticos en el ámbito médico. Debido a estos desafíos, La validación de algoritmos de alto rendimiento del dominio abierto en datos clínicos permanece sin investigar.
Para abordar estas brechas, Trabajamos con el Instituto de Tecnología de Massachusetts para construir MedNLI, un conjunto de datos anotado por médicos, realizando una tarea de inferencia del lenguaje natural (NLI) y basada en el historial médico de los pacientes. Más importante, lo ponemos a disposición del público para que los investigadores avancen en el procesamiento del lenguaje natural en la medicina.
Trabajamos con los laboratorios de investigación de datos críticos del MIT para construir un conjunto de datos para la inferencia del lenguaje natural en medicina. Usamos notas clínicas de su base de datos "Medical Information Mart for Intensive Care" (MIMIC), que es posiblemente la base de datos de registros de pacientes más grande disponible públicamente. Los médicos de nuestro equipo sugirieron que el historial médico anterior de un paciente contiene información vital de la que se pueden extraer inferencias útiles. Por lo tanto, extrajimos el historial médico pasado de las notas clínicas en MIMIC y presentamos una oración de este historial como premisa para un clínico. Luego se les pidió que usaran su experiencia médica y generaran tres oraciones:una oración que era definitivamente cierta sobre el paciente, dada la premisa; una frase que definitivamente era falsa, y finalmente una frase que posiblemente podría ser cierta.
Durante unos meses, hicimos una muestra aleatoria de 4, 683 tales locales y trabajó con cuatro médicos para construir MedNLI, un conjunto de datos de 14, 049 pares premisa-hipótesis. En el dominio abierto, Otros ejemplos de conjuntos de datos construidos de manera similar incluyen el conjunto de datos de inferencia del lenguaje natural de Stanford, que fue curada con la ayuda de 2, 500 trabajadores de Amazon Mechanical Turk y consta de 0,5 millones de pares premisa-hipótesis donde las oraciones premisas se extrajeron de los subtítulos de las fotos de Flickr. MultiNLI es otro y consta de texto premisa de géneros específicos como ficción, blogs, conversaciones telefónicas, etc.
El Dr. Leo Anthony Celi (científico principal de MIMIC) y el Dr. Alistair Johnson (científico investigador) de MIT Critical Data trabajaron con nosotros para hacer que MedNLI esté disponible públicamente. Crearon el repositorio de datos derivados de MIMIC, a lo que MedNLI actuó como la primera contribución a un conjunto de datos de procesamiento del lenguaje natural. Cualquier investigador con acceso a MIMIC también puede descargar MedNLI desde este repositorio.
Aunque de un tamaño modesto en comparación con los conjuntos de datos de dominio abierto, MedNLI es lo suficientemente grande como para informar a los investigadores a medida que desarrollan nuevos modelos de aprendizaje automático para la inferencia del lenguaje en medicina. Más importante, presenta desafíos interesantes que exigen ideas innovadoras. Considere algunos ejemplos de MedNLI:
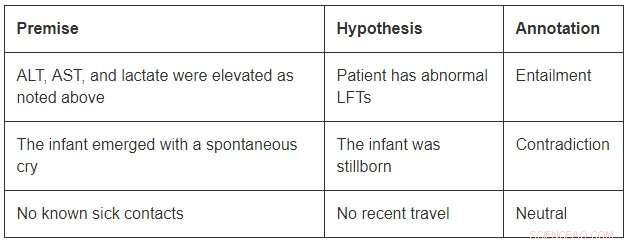
Para concluir la implicación en el primer ejemplo, uno debería poder expandir las abreviaturas ALT, AST, y LFT; entender que están relacionados; y concluir además que una medición elevada es anormal. El segundo ejemplo muestra una sutil inferencia de concluir que el surgimiento de un infante es una descripción de su nacimiento. Finalmente, el último ejemplo muestra cómo se utiliza el conocimiento común del mundo para derivar inferencias.
Los algoritmos de aprendizaje profundo de última generación pueden tener un alto rendimiento en las tareas del lenguaje porque tienen el potencial de volverse muy buenos en el aprendizaje de un mapeo preciso de las entradas a las salidas. Por lo tanto, La formación en un gran conjunto de datos anotado mediante anotaciones de fuentes colectivas suele ser una receta para el éxito. Sin embargo, todavía carecen de capacidad de generalización en condiciones que difieren de las encontradas durante el entrenamiento. Esto es aún más desafiante en dominios especializados e intensivos en conocimiento, como la medicina, donde los datos de formación son limitados y el lenguaje tiene muchos más matices.
Finalmente, aunque se han logrado grandes avances en el aprendizaje de una tarea lingüística de principio a fin, todavía existe la necesidad de técnicas adicionales que puedan incorporar bases de conocimiento curadas por expertos en estos modelos. Por ejemplo, SNOMED-CT es una terminología médica curada por expertos con más de 300.000 conceptos y relaciones entre los términos en su conjunto de datos. Dentro de MedNLI, Hicimos modificaciones simples a las arquitecturas de redes neuronales profundas existentes para infundir conocimiento de bases de conocimiento como SNOMED-CT. Sin embargo, una gran cantidad de conocimiento aún permanece sin explotar.
Esperamos que MedNLI abra nuevas direcciones de investigación en la comunidad del procesamiento del lenguaje natural.
Esta historia se vuelve a publicar por cortesía de IBM Research. Lea la historia original aquí.