Dependemos de catalizadores para convertir nuestra leche en yogur, producir notas adhesivas a partir de pulpa de papel y desbloquear fuentes de energía renovables como los biocombustibles. Encontrar materiales catalizadores óptimos para reacciones específicas requiere experimentos laboriosos y cálculos de química cuántica computacionalmente intensivos.
A menudo, los científicos recurren a redes neuronales gráficas (GNN) para capturar y predecir la complejidad estructural de los sistemas atómicos, un sistema eficiente sólo después de que se completa la meticulosa conversión de estructuras atómicas 3D en coordenadas espaciales precisas en el gráfico.
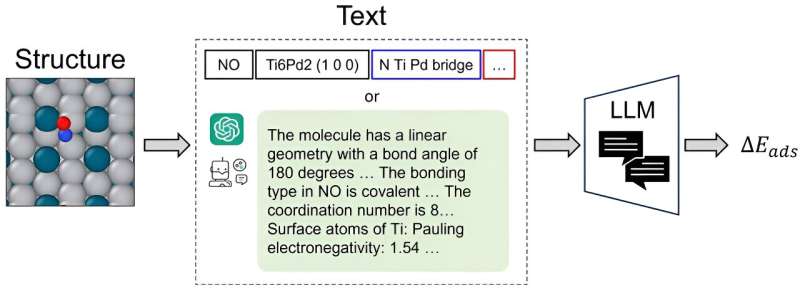
CatBERTa, un modelo de transformador de predicción de energía, fue desarrollado por investigadores de la Facultad de Ingeniería de la Universidad Carnegie Mellon como un enfoque para abordar la predicción de propiedades moleculares mediante el aprendizaje automático.
"Este es el primer enfoque que utiliza un modelo de lenguaje grande (LLM) para esta tarea, por lo que estamos abriendo una nueva vía para el modelado", dijo Janghoon Ock, Ph.D. candidato en el laboratorio de Amir Barati Farimani.
Un diferenciador clave es la capacidad del modelo para emplear texto directamente (lenguaje natural) sin ningún procesamiento previo para predecir las propiedades del sistema adsorbato-catalizador. Este método es notablemente beneficioso ya que sigue siendo fácilmente interpretable por los humanos, lo que permite a los investigadores integrar características observables en sus datos sin problemas.
Además, la aplicación del modelo de transformador en su investigación ofrece conocimientos sustanciales. Las puntuaciones de autoatención, en particular, son cruciales para mejorar su comprensión de la interpretabilidad dentro de este marco.
"No puedo decir que será una alternativa a los GNN de última generación, pero tal vez podamos utilizarlo como un enfoque complementario", dijo Ock. "Como dicen, 'Cuantos más, mejor'".
El modelo ofrece una precisión predictiva comparable a la lograda por versiones anteriores de GNN. En particular, CatBERTa tuvo más éxito cuando se entrenó con conjuntos de datos de tamaño limitado. Además, CatBERTa ha superado las capacidades de cancelación de errores de los GNN existentes.
El equipo se centró en la energía de adsorción, pero dijo que el enfoque se puede extender a otras propiedades, como la brecha HOMO-LUMO y las estabilidades relacionadas con los sistemas adsorbato-catalizador, dado un conjunto de datos adecuado.
Al integrar las capacidades de modelos de lenguaje extensos con las demandas del descubrimiento de catalizadores, el equipo tiene como objetivo optimizar el proceso de selección eficaz de catalizadores. Ock está trabajando para mejorar la precisión del modelo.
Los hallazgos se publican en la revista ACS Catalysis. .
Más información: Janghoon Ock et al, Predicción de energía catalizadora con CatBERTa:presentación de estrategias de exploración de funciones a través de modelos de lenguaje grandes, Catálisis ACS (2023). DOI:10.1021/acscatal.3c04956
Información de la revista: Catálisis ACS
Proporcionado por Ingeniería Mecánica de la Universidad Carnegie Mellon