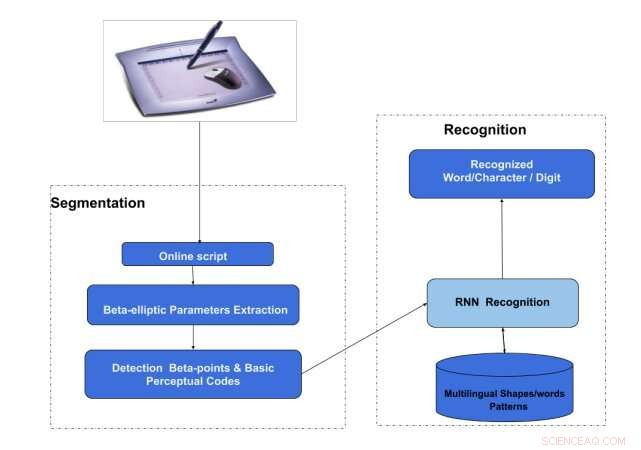
La arquitectura de OnHS-LSTM. Crédito:Akouaydi et al.
Investigadores de la Universidad de Sfax, en Túnez, Recientemente, han desarrollado un nuevo método para reconocer caracteres y símbolos escritos a mano en guiones en línea. Su técnica, presentado en un artículo publicado previamente en arXiv, ya ha logrado un desempeño notable en textos escritos tanto en alfabeto latino como en árabe.
En años recientes, Los investigadores han creado arquitecturas basadas en redes neuronales que pueden abordar una variedad de tareas, incluida la clasificación de imágenes, Reconocimiento facial, procesamiento del lenguaje natural (PNL), y muchos más. Los sistemas de reconocimiento de escritura a mano son herramientas informáticas que están diseñadas específicamente para reconocer caracteres y otros símbolos escritos a mano de manera similar a los humanos.
En sus primeros años de vida, De hecho, Los seres humanos desarrollan de manera innata la capacidad de comprender diferentes tipos de escritura a mano al identificar caracteres específicos tanto individualmente como cuando se agrupan. Durante la última década más o menos, muchos estudios han intentado replicar esta capacidad en sistemas informáticos, ya que esto permitiría en última instancia análisis más avanzados y automáticos de los textos escritos a mano.
"Nuestro documento maneja el problema del reconocimiento de guiones manuscritos en línea basado en un sistema de características de extracción y un sistema de enfoque profundo para la clasificación de secuencias, "Los investigadores escribieron en su artículo." Utilizamos un método existente combinado con nuevos clasificadores para lograr un sistema flexible ".
En su papel Los investigadores de la Universidad de Sfax presentan dos sistemas basados en redes neuronales profundas:un sistema de reconocimiento y segmentación de escritura a mano en línea que utiliza una red de memoria a largo plazo a corto plazo (OnHSR-LSTM) y un sistema de reconocimiento de escritura a mano en línea compuesto por un sistema convolucional largo y corto. red de memoria a término (OnHR-covLSTM).
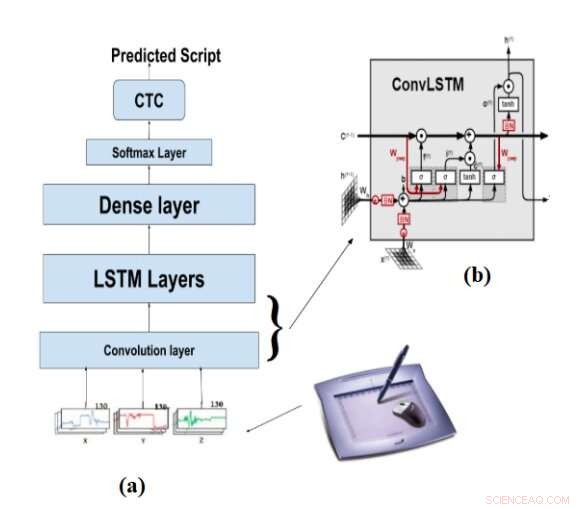
La arquitectura de (a) OnHR-convLSTM, (b) la celda convLSTM. Crédito:Akouaydi et al.
Su primer modelo, apodado OnHSR-LSTM, se basa en una teoría que describe el sistema perceptivo humano como un medio para transformar el lenguaje de marcas gráficas en representaciones simbólicas. Funciona detectando propiedades comunes de símbolos o caracteres y luego ordenándolos de acuerdo con leyes de percepción específicas, por ejemplo, basado en la proximidad, semejanza, etc.
"Finalmente, [el modelo] intenta construir una representación de la forma manuscrita basada en el supuesto de que la percepción de la forma es la identificación de características básicas que se ordenan hasta que identificamos un objeto, "explicaron los investigadores en su artículo". Por lo tanto, la representación de la escritura a mano es una combinación de trazos primitivos. La escritura a mano es una secuencia de códigos básicos que se agrupan para definir un carácter o una forma ".
La primera técnica propuesta por los investigadores divide esencialmente un guión escrito a mano en trazos elípticos individuales utilizando un modelo de generación de escritura a mano. Después, estos trazos se clasifican en códigos primitivos, que son utilizados por la arquitectura neuronal para reconocer palabras en escrituras manuscritas en línea.
El segundo sistema propuesto por los investigadores, OnHR-convLSTM, es un modelo generativo que utiliza la señal en línea de un script como entrada y está entrenado para predecir tanto caracteres como palabras. Esta segunda técnica es particularmente útil para tareas de aprendizaje de secuencias (es decir, tareas que involucran el procesamiento y clasificación de largas secuencias de caracteres y símbolos).
Los investigadores capacitaron y evaluaron ambos sistemas utilizando cinco bases de datos diferentes que contienen escrituras manuscritas en los alfabetos árabe y latino. Sus pruebas arrojaron resultados notables, con ambos sistemas logrando tasas de reconocimiento de más del 98 por ciento. Curiosamente, los investigadores encontraron que el rendimiento de ambas técnicas es comparable al que normalmente logran sujetos humanos en tareas similares.
"Ahora planeamos desarrollar y probar nuestros sistemas de reconocimiento propuestos en una base de datos a gran escala y otros scripts, "escribieron los investigadores.
© 2019 Science X Network














