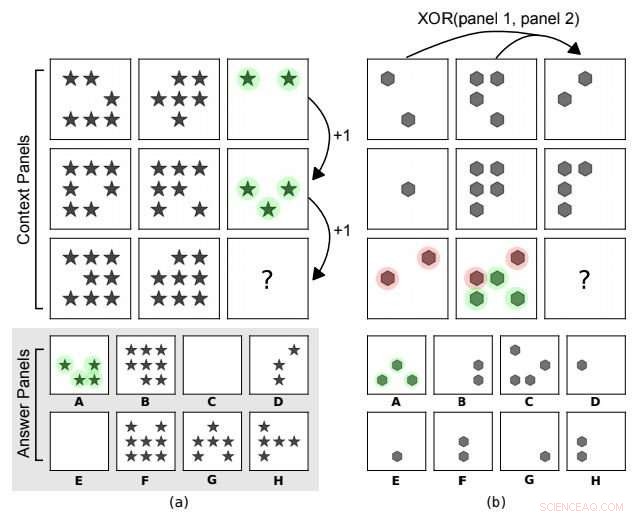
Matrices progresivas estilo cuervo. En (a) la regla abstracta subyacente es una progresión aritmética en el número de formas a lo largo de las columnas. En (b) hay una relación XOR en las posiciones de la forma a lo largo de las filas (panel 3 =XOR (panel 1, panel 2)). Otras características, como el tipo de forma, no se tienen en cuenta. A es la elección correcta para ambas. Crédito:arXiv:1807.04225 [cs.LG]
Pruebas, pruebas:DeepMind sienta a la IA para una prueba de coeficiente intelectual. Si bien los resultados del rendimiento de la IA no son asombrosos en cuanto a superar o igualar el razonamiento humano, es un comienzo. Los científicos de la IA reconocen que ha resultado difícil establecer su capacidad para razonar sobre conceptos abstractos. DeepMind quería ver cómo podía funcionar la IA y el equipo propuso un conjunto de datos y un desafío para sondear el razonamiento abstracto.
¿Puede la IA igualar nuestras habilidades para el razonamiento abstracto? ¿Podrán las redes neuronales profundas resolver mejor los problemas de razonamiento visual abstracto en el futuro? Los investigadores de DeepMind ciertamente han estado en el caso.
Su papel "Midiendo el razonamiento abstracto en redes neuronales, "está en arXiv. Los autores son David Barrett, Felix Hill, Adam Santoro, Ari Morcos, Timothy Lillicrap, de DeepMind. Puede comprobar lo que estaban buscando y cómo lo probaron. El artículo se centra básicamente en un enfoque para medir el razonamiento abstracto en máquinas de aprendizaje. En su discusión, el equipo dijo, sí, Ha habido avances en el aprendizaje del razonamiento y la representación abstracta en redes neuronales, pero la medida en que estos modelos exhiben algo parecido al razonamiento abstracto general "es objeto de mucho debate".
Los modelos para tener éxito tenían que hacer frente a regímenes de generalización en los que los datos de entrenamiento y prueba diferían. Dijeron que presentaban una arquitectura con una estructura diseñada para fomentar el razonamiento. Resultados:Bolsa mixta. Dijeron que su modelo era competente en ciertas formas de generalización, pero débil en otros.
Sin embargo, Cabe señalar que exploraron formas de medir y obtener un razonamiento abstracto más sólido en las redes neuronales.
"Las pruebas de coeficiente intelectual humano estándar a menudo requieren que los examinados interpreten escenas visuales perceptualmente simples aplicando principios que han aprendido a través de la experiencia diaria, ", dijo un blog de DeepMind." Todavía no tenemos los medios para exponer a los agentes de aprendizaje automático a un flujo similar de 'experiencias cotidianas', lo que significa que no podemos medir fácilmente su capacidad para transferir conocimientos del mundo real a pruebas de razonamiento visual. Sin embargo, podemos crear una configuración experimental que todavía hace un buen uso de las pruebas de razonamiento visual humano ".
Procedieron a construir un generador de problemas matriciales con un conjunto de factores abstractos. El equipo está fomentando más investigaciones sobre el razonamiento abstracto, y pusieron su conjunto de datos a disposición del público.
La pregunta general es si los científicos pueden lograr capacidades de razonamiento analítico similares a las humanas.
Si bien los resultados de sus pruebas de coeficiente intelectual podrían haber sido una bolsa mixta, los investigadores no ven esto como un juego de ganar o darse por vencido. Continuarán con su trabajo para explorar estrategias para mejorar la generalización y explorar modelos futuros. Como Buceo CIO remarcó, "Los asistentes inteligentes han recibido montañas de datos para ayudar a los consumidores en casi todas las áreas imaginables, sin embargo, cuando se presentan problemas desconocidos, aún pueden quedarse cortos ".
Los autores escribieron, en su resumen, "proponemos un conjunto de datos y un desafío diseñado para sondear el razonamiento abstracto, inspirado en una conocida prueba de coeficiente intelectual humano. Para tener éxito en este desafío, Los modelos deben hacer frente a varios "regímenes" de generalización en los que los datos de entrenamiento y de prueba difieren en formas claramente definidas. Mostramos que los modelos populares como ResNets funcionan mal, incluso cuando los conjuntos de entrenamiento y prueba difieren solo mínimamente, y presentamos una arquitectura novedosa, con una estructura diseñada para fomentar el razonamiento, que lo hace significativamente mejor ".
Buceo CIO describieron sus pruebas como pruebas de coeficiente intelectual visual. En el proceso, los autores estaban interesados en ver el desempeño en las habilidades para generalizar cuando los datos de las pruebas eran diferentes.
Emparejar la IA con las habilidades humanas para la abstracción sigue siendo una batalla cuesta arriba.
Como Buceo CIO Alex Hickey escribió, La IA necesitaría distinguir diferentes significados entre "comer espaguetis con queso" y "comer espaguetis con perros".
El documento comentó que probar las capacidades de las redes neuronales puede ser complicado y las redes neuronales tienen sus escollos. dada su capacidad de memorización y habilidad para explotar pistas estadísticas superficiales.
© 2018 Tech Xplore