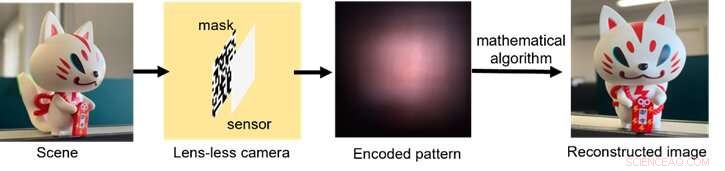
Un esquema de cómo funciona el proceso de imágenes sin lentes, desde la recolección de luz hasta la codificación de la señal y el posprocesamiento con algoritmos informáticos. Crédito:Xiuxi Pan de Tokyo Tech
Una cámara generalmente requiere un sistema de lentes para capturar una imagen enfocada, y la cámara con lentes ha sido la solución de imagen dominante durante siglos. Una cámara con lente requiere un sistema de lentes complejo para lograr imágenes de alta calidad, brillantes y sin aberraciones. Las últimas décadas han visto un aumento en la demanda de cámaras más pequeñas, livianas y económicas. Existe una clara necesidad de cámaras de próxima generación con alta funcionalidad, lo suficientemente compactas como para instalarlas en cualquier lugar. Sin embargo, la miniaturización de la cámara con lente está restringida por el sistema de lentes y la distancia de enfoque requerida por las lentes refractivas.
Los avances recientes en la tecnología informática pueden simplificar el sistema de lentes sustituyendo la informática por algunas partes del sistema óptico. Se puede abandonar toda la lente gracias al uso de la computación de reconstrucción de imágenes, lo que permite una cámara sin lente, que es ultradelgada, liviana y de bajo costo. La cámara sin lentes ha estado ganando terreno recientemente. Pero hasta el momento, no se ha establecido la técnica de reconstrucción de imágenes, lo que da como resultado una calidad de imagen inadecuada y un tiempo de cálculo tedioso para la cámara sin lentes.
Recientemente, los investigadores han desarrollado un nuevo método de reconstrucción de imágenes que mejora el tiempo de cálculo y proporciona imágenes de alta calidad. Al describir la motivación inicial detrás de la investigación, un miembro central del equipo de investigación, el profesor Masahiro Yamaguchi de Tokyo Tech, dice:"Sin las limitaciones de una lente, la cámara sin lente podría ser ultraminiatura, lo que podría permitir nuevas aplicaciones que son más allá de nuestra imaginación". Su trabajo ha sido publicado en Optics Letters .
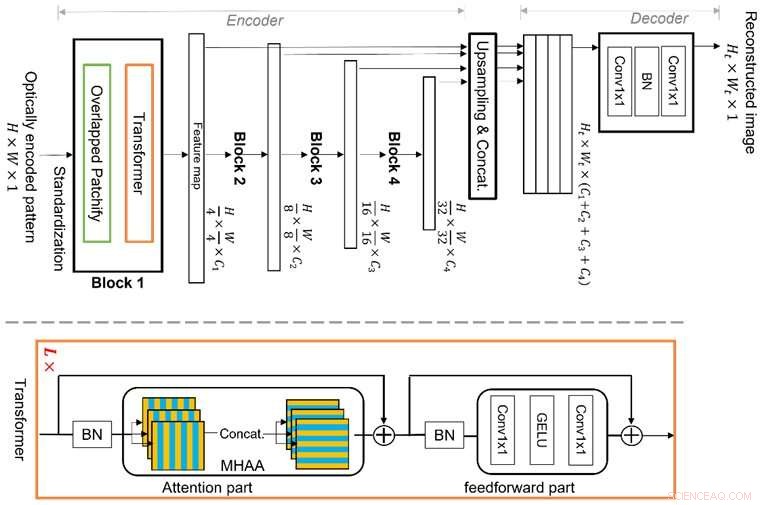
Vision Transformer (ViT) es una técnica de aprendizaje automático de vanguardia, que es mejor en el razonamiento de características globales debido a su estructura novedosa de bloques de transformadores de varias etapas con módulos de "parches" superpuestos. Esto le permite aprender de manera eficiente las características de la imagen en una representación jerárquica, lo que le permite abordar la propiedad de multiplexación y evitar las limitaciones del aprendizaje profundo convencional basado en CNN, lo que permite una mejor reconstrucción de la imagen. Crédito:Xiuxi Pan de Tokyo Tech
El hardware óptico típico de la cámara sin lente consiste simplemente en una máscara delgada y un sensor de imagen. Luego, la imagen se reconstruye utilizando un algoritmo matemático. La máscara y el sensor se pueden fabricar juntos en procesos de fabricación de semiconductores establecidos para la producción futura. La máscara codifica ópticamente la luz incidente y proyecta patrones en el sensor. Aunque los patrones fundidos no son interpretables por el ojo humano, se pueden decodificar con un conocimiento explícito del sistema óptico.
Sin embargo, el proceso de decodificación, basado en la tecnología de reconstrucción de imágenes, sigue siendo un desafío. Los métodos tradicionales de decodificación basados en modelos se aproximan al proceso físico de la óptica sin lentes y reconstruyen la imagen resolviendo un problema de optimización "convexo". Esto significa que el resultado de la reconstrucción es susceptible a las aproximaciones imperfectas del modelo físico. Además, el cálculo necesario para resolver el problema de optimización requiere mucho tiempo porque requiere un cálculo iterativo. El aprendizaje profundo podría ayudar a evitar las limitaciones de la decodificación basada en modelos, ya que puede aprender el modelo y decodificar la imagen mediante un proceso directo no iterativo. Sin embargo, los métodos de aprendizaje profundo existentes para imágenes sin lentes, que utilizan una red neuronal convolucional (CNN), no pueden producir imágenes de alta calidad. Son ineficientes porque CNN procesa la imagen en función de las relaciones de los píxeles "locales" vecinos, mientras que la óptica sin lentes transforma la información local en la escena en información "global" superpuesta en todos los píxeles del sensor de imagen, a través de una propiedad llamada "multiplexación". "

La cámara sin lente consta de una máscara y un sensor de imagen con una distancia de separación de 2,5 mm. La máscara se fabrica mediante deposición de cromo en una placa de sílice sintética con un tamaño de apertura de 40 × 40 μm. Crédito:Xiuxi Pan de Tokyo Tech
El equipo de investigación de Tokyo Tech está estudiando esta propiedad de multiplexación y ahora ha propuesto un algoritmo de aprendizaje automático novedoso y dedicado para la reconstrucción de imágenes. El algoritmo propuesto se basa en una técnica de aprendizaje automático de vanguardia llamada Transformador de visión (ViT), que es mejor en el razonamiento de características globales. La novedad del algoritmo radica en la estructura de los bloques de transformadores multietapa con módulos "patchify" superpuestos. Esto le permite aprender eficientemente las características de la imagen en una representación jerárquica. En consecuencia, el método propuesto puede abordar la propiedad de multiplexación y evitar las limitaciones del aprendizaje profundo convencional basado en CNN, lo que permite una mejor reconstrucción de imágenes.
Si bien los métodos convencionales basados en modelos requieren largos tiempos de cálculo para el procesamiento iterativo, el método propuesto es más rápido porque la reconstrucción directa es posible con un algoritmo de procesamiento sin iteraciones diseñado por aprendizaje automático. La influencia de los errores de aproximación del modelo también se reduce drásticamente porque el sistema de aprendizaje automático aprende el modelo físico. Además, el método basado en ViT propuesto utiliza características globales en la imagen y es adecuado para procesar patrones moldeados en un área amplia del sensor de imagen, mientras que los métodos de decodificación basados en aprendizaje automático convencional aprenden principalmente las relaciones locales mediante CNN.
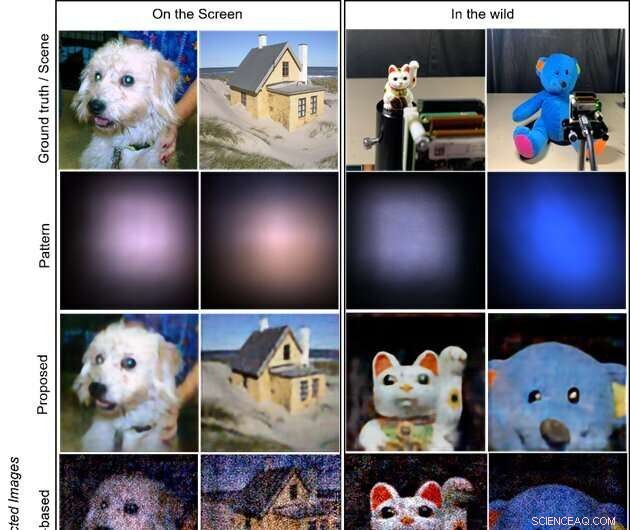
Los objetivos son las imágenes que se muestran en una pantalla LCD (las dos columnas de la izquierda) y los objetos en la naturaleza (las dos columnas de la derecha; el muñeco gato que hace señas y el oso de peluche), respectivamente. La primera fila muestra las imágenes reales del terreno que se muestran en la pantalla y las escenas de captura de objetos en estado salvaje. La segunda fila muestra los patrones capturados en el sensor. Las últimas tres filas ilustran las imágenes reconstruidas por los métodos propuestos, basados en modelos y basados en CNN, respectivamente. El método propuesto produce imágenes de la más alta calidad y visualmente atractivas. Crédito:Xiuxi Pan de Tokyo Tech
En resumen, el método propuesto resuelve las limitaciones de los métodos convencionales, como el procesamiento iterativo basado en la reconstrucción de imágenes y el aprendizaje automático basado en CNN con la arquitectura ViT, lo que permite la adquisición de imágenes de alta calidad en un corto período de tiempo informático. El equipo de investigación realizó además experimentos ópticos, como se informó en su última publicación en, que sugieren que la cámara sin lente con el método de reconstrucción propuesto puede producir imágenes de alta calidad y visualmente atractivas, mientras que la velocidad de procesamiento posterior es lo suficientemente alta para real. captura de tiempo.
"Nos damos cuenta de que la miniaturización no debería ser la única ventaja de la cámara sin lente. La cámara sin lente se puede aplicar a la imagen de luz invisible, en la que el uso de una lente no es práctico o incluso imposible. Además, la dimensionalidad subyacente de la información óptica capturada por la cámara sin lente es mayor que dos, lo que hace posible la creación de imágenes en 3D de una sola toma y el reenfoque posterior a la captura. Estamos explorando más funciones de la cámara sin lente. El objetivo final de una cámara sin lente es ser pequeña pero poderosa. Estamos emocionados de liderar en esta nueva dirección para las soluciones de imágenes y detección de próxima generación", dice el autor principal del estudio, el Sr. Xiuxi Pan de Tokyo Tech, mientras habla sobre su trabajo futuro. Ampliación de la microespectroscopia infrarroja con el método de reconstrucción computacional Lucy-Richardson-Rosen