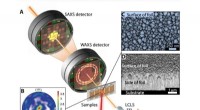
La próxima frontera del almacenamiento de datos:el ADN. Crédito:ymgerman / Shutterstock.com
La humanidad está produciendo datos a un ritmo inimaginable, hasta el punto de que las tecnologías de almacenamiento no pueden mantenerse al día. Cada cinco años la cantidad de datos que producimos aumenta diez veces, incluyendo fotos y videos. No es necesario almacenarlo todo, pero los fabricantes de almacenamiento de datos no están fabricando discos duros y chips flash lo suficientemente rápidos como para contener lo que queremos conservar. Como no vamos a dejar de tomar fotografías y grabar películas, necesitamos desarrollar nuevas formas de salvarlos.
Durante milenios la naturaleza ha desarrollado un increíble medio de almacenamiento de información:el ADN. Evolucionó para almacenar información genética, planos para la construcción de proteínas, pero el ADN se puede utilizar para muchos más propósitos. El ADN también es mucho más denso que los medios de almacenamiento modernos:los datos de cientos de miles de DVD podrían caber dentro de un paquete de ADN del tamaño de una caja de cerillas. El ADN también es mucho más duradero (miles de años) que los discos duros actuales, que puede durar años o décadas. Y mientras los formatos de disco duro y los estándares de conexión se vuelven obsoletos, El ADN nunca lo hará al menos mientras haya vida.
La idea de almacenar datos digitales en el ADN tiene varias décadas, pero un trabajo reciente de Harvard y el Instituto Europeo de Bioinformática mostró que el progreso en los métodos modernos de manipulación del ADN podría hacerlo posible y práctico en la actualidad. Muchos grupos de investigación, incluso en la ETH Zurich, la Universidad de Illinois en Urbana-Champaign y la Universidad de Columbia están trabajando en este problema. Nuestro propio grupo en la Universidad de Washington y Microsoft tiene el récord mundial por la cantidad de datos almacenados y recuperados exitosamente del ADN:200 megabytes.
Preparando bits para que se conviertan en átomos
Medios tradicionales como discos duros, unidades de memoria USB o DVD almacenan datos digitales cambiando el magnético, propiedades eléctricas u ópticas de un material para almacenar 0 y 1.
Para almacenar datos en ADN, El concepto es el mismo, pero el proceso es diferente. Las moléculas de ADN son secuencias largas de moléculas más pequeñas, llamados nucleótidos - adenina, citosina timina y guanina, generalmente designado como A, C, T y G. En lugar de crear secuencias de 0 y 1, como en los medios electrónicos, El almacenamiento de ADN utiliza secuencias de nucleótidos.
Hay varias formas de hacer esto, pero la idea general es asignar patrones de datos digitales a los nucleótidos del ADN. Por ejemplo, 00 podría ser equivalente a A, 01 a C, 10 a T y 11 a G. Para almacenar una imagen, por ejemplo, comenzamos con su codificación como un archivo digital, como un JPEG. Ese archivo es, en esencia, una larga cadena de 0 y 1. Digamos que los primeros ocho bits del archivo son 01111000; los dividimos en pares - 01 11 10 00 - que corresponden a C-G-T-A. Ese es el orden en el que unimos los nucleótidos para formar una cadena de ADN.
Los archivos de computadora digital pueden ser bastante grandes, incluso de terabytes para bases de datos grandes. Pero las hebras de ADN individuales tienen que ser mucho más cortas, con solo unos 20 bytes cada una. Eso es porque cuanto más larga es una hebra de ADN, más difícil es construir químicamente.
Por lo tanto, debemos dividir los datos en partes más pequeñas, y agregue a cada uno un indicador de en qué parte de la secuencia se encuentra. Cuando llega el momento de leer la información almacenada en el ADN, ese indicador asegurará que todos los fragmentos de datos permanezcan en su orden correcto.
Ahora tenemos un plan sobre cómo almacenar los datos. Lo siguiente que tenemos que hacer es hacerlo.
Almacenar los datos
Después de determinar en qué orden deben ir las letras, las secuencias de ADN se fabrican letra por letra con reacciones químicas. Estas reacciones son impulsadas por un equipo que admite botellas de A, C's, G's y T's y los mezcla en una solución líquida con otros químicos para controlar las reacciones que especifican el orden de las hebras físicas de ADN.
Este proceso nos aporta otro beneficio del almacenamiento de ADN:copias de seguridad. En lugar de hacer una hebra a la vez, las reacciones químicas forman muchas hebras idénticas a la vez, antes de hacer muchas copias del siguiente capítulo de la serie.
Una vez que se crean las hebras de ADN, debemos protegerlos contra los daños causados por la humedad y la luz. Entonces los secamos y los ponemos en un recipiente que los mantiene fríos y bloquea el agua y la luz.
Pero los datos almacenados son útiles solo si podemos recuperarlos más tarde.
Leyendo los datos
Para volver a leer los datos fuera del almacenamiento, utilizamos una máquina de secuenciación exactamente como las que se utilizan para el análisis del ADN genómico en las células. Esto identifica las moléculas, generando una secuencia de letras por molécula, que luego decodificamos en una secuencia binaria de 0 y 1 en orden. Este proceso puede destruir el ADN a medida que se lee, pero ahí es donde entran en juego esas copias de seguridad:hay muchas copias de cada secuencia.
Y si las copias de seguridad se agotan, es fácil hacer copias duplicadas para rellenar el almacenamiento, al igual que la naturaleza copia el ADN todo el tiempo.
En este momento, la mayoría de los sistemas de recuperación de ADN requieren leer toda la información almacenada en un contenedor en particular, incluso si queremos solo una pequeña cantidad. Esto es como leer toda la información de un disco duro solo para encontrar un mensaje de correo electrónico. Hemos desarrollado técnicas, basadas en métodos bioquímicos bien estudiados, que nos permiten identificar y leer solo las piezas específicas de información que un usuario necesita recuperar del almacenamiento de ADN.
Desafíos restantes
En el presente, El almacenamiento de ADN es experimental. Antes de que se convierta en algo común, debe estar completamente automatizado, y los procesos de construcción y lectura del ADN deben mejorarse. Ambos son propensos a errores y relativamente lentos. Por ejemplo, La síntesis de ADN actual nos permite escribir unos cientos de bytes por segundo; un disco duro moderno puede escribir cientos de millones de bytes por segundo. Una foto de iPhone promedio tardaría varias horas en almacenarse en el ADN, aunque se tarda menos de un segundo en guardar en el teléfono o transferir a una computadora.
Estos son desafíos importantes, pero somos optimistas porque todas las tecnologías relevantes están mejorando rápidamente. Más lejos, El almacenamiento de datos de ADN no necesita la precisión perfecta que requiere la biología, por lo que es probable que los investigadores encuentren formas aún más baratas y rápidas de almacenar información en el sistema de almacenamiento de datos más antiguo de la naturaleza.
Este artículo se publicó originalmente en The Conversation. Lea el artículo original.