'Théâtre D'opéra Spatial' Crédito:Jason Allen / Midjourney
El mes pasado se otorgó un premio de arte en la Feria Estatal de Colorado a una obra que, sin que los jueces lo supieran, fue generada por un sistema de inteligencia artificial (IA).
Las redes sociales también han visto una explosión de imágenes extrañas generadas por IA a partir de descripciones de texto, como "la cara de un shiba inu mezclada con el costado de una barra de pan en un banco de cocina, arte digital".

O tal vez "Una nutria marina al estilo de 'La joven de la perla' de Johannes Vermeer":

'Una nutria marina al estilo de 'La joven de la perla' de Johannes Vermeer'. Crédito:OpenAI
Usted se estará preguntando qué está pasando aquí. Como alguien que investiga colaboraciones creativas entre humanos e IA, puedo decirles que detrás de los titulares y los memes se está gestando una revolución fundamental, con profundas implicaciones sociales, artísticas, económicas y tecnológicas.
Cómo llegamos aquí
Se podría decir que esta revolución comenzó en junio de 2020, cuando una empresa llamada OpenAI logró un gran avance en IA con la creación de GPT-3, un sistema que puede procesar y generar lenguaje de formas mucho más complejas que los esfuerzos anteriores. Puede tener conversaciones con él sobre cualquier tema, pedirle que escriba un artículo de investigación o una historia, resuma un texto, escriba un chiste y realice casi cualquier tarea de lenguaje imaginable.
En 2021, algunos de los desarrolladores de GPT-3 recurrieron a las imágenes. Entrenaron un modelo en miles de millones de pares de imágenes y descripciones de texto, luego lo usaron para generar nuevas imágenes a partir de nuevas descripciones. Llamaron a este sistema DALL-E, y en julio de 2022 lanzaron una nueva versión muy mejorada, DALL-E 2.

Una imagen generada por DALL-E a partir del mensaje "Mind in Bloom" que combina los estilos de Salvador Dalí, Henri Matisse y Brett Whiteley. Crédito:Rodolfo Ocampo / DALL-E
Al igual que GPT-3, DALL-E 2 fue un gran avance. Puede generar imágenes muy detalladas a partir de entradas de texto de forma libre, incluida información sobre estilo y otros conceptos abstractos.
Por ejemplo, aquí le pedí que ilustrara la frase "Mind in Bloom" combinando los estilos de Salvador Dalí, Henri Matisse y Brett Whiteley.
Los competidores entran en escena
Desde el lanzamiento de DALL-E 2, han surgido algunos competidores. Uno es el DALL-E Mini de uso gratuito pero de menor calidad (desarrollado de forma independiente y ahora rebautizado como Craiyon), que era una fuente popular de contenido de memes.
Casi al mismo tiempo, una empresa más pequeña llamada Midjourney lanzó un modelo que se acercaba más a las capacidades de DALL-E 2. Aunque todavía un poco menos capaz que DALL-E 2, Midjourney se ha prestado a interesantes exploraciones artísticas. Fue con Midjourney que Jason Allen generó la obra de arte que ganó la competencia de la Feria de Arte del Estado de Colorado.
Google también tiene un modelo de texto a imagen, llamado Imagen, que supuestamente produce resultados mucho mejores que DALL-E y otros. Sin embargo, Imagen aún no se ha lanzado para un uso más amplio, por lo que es difícil evaluar las afirmaciones de Google.
En julio de 2022, OpenAI comenzó a capitalizar el interés en DALL-E y anunció que 1 millón de usuarios tendrían acceso mediante pago por uso.
Sin embargo, en agosto de 2022 llegó un nuevo contendiente:Stable Diffusion.
Stable Diffusion no solo rivaliza con DALL-E 2 en sus capacidades, sino que, lo que es más importante, es de código abierto. Cualquiera puede usar, adaptar y modificar el código a su gusto.
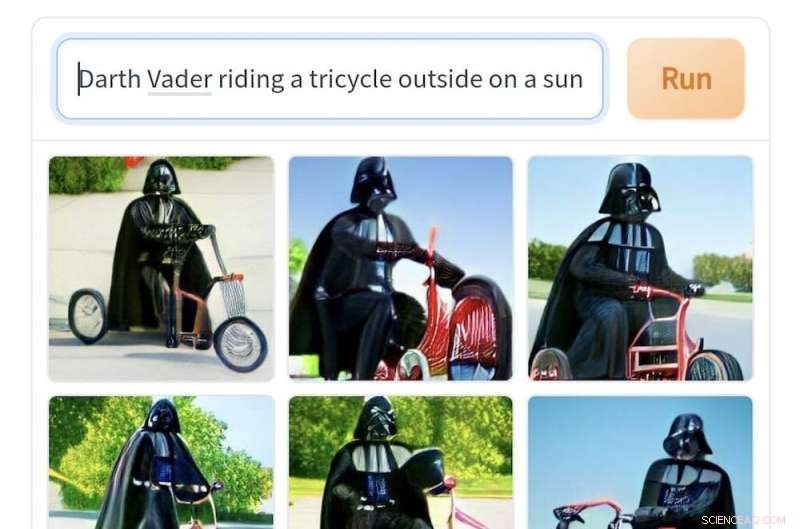
Imágenes generadas por Craiyon a partir del mensaje "Darth Vader montando un triciclo afuera en un día soleado". Crédito:Craiyon
Ya, en las semanas posteriores al lanzamiento de Stable Diffusion, la gente ha llevado el código al límite de lo que puede hacer.
Para dar un ejemplo:la gente rápidamente se dio cuenta de que, debido a que un video es una secuencia de imágenes, podían modificar el código de Stable Diffusion para generar video a partir de texto.
@StableDiffusion Img2Img x #ebsynth x @koe_recast TEST#stablediffusion #AIart pic.twitter.com/aZgZZBRjWM
— Scott Lighthiser (@LighthiserScott) 7 de septiembre de 2022
Otra herramienta fascinante creada con el código de Stable Diffusion es Diffuse the Rest, que le permite dibujar un boceto simple, proporcionar un mensaje de texto y generar una imagen a partir de él.
¿El fin de la creatividad?
¿Qué significa que puedes generar cualquier tipo de contenido visual, imagen o video, con unas pocas líneas de texto y el clic de un botón? ¿Qué pasa cuando puedes generar un guión de película con GPT-3 y una animación de película con DALL-E 2?
Y mirando más adelante, ¿qué significará cuando los algoritmos de las redes sociales no solo seleccionen contenido para su feed, sino que lo generen? ¿Qué pasará cuando esta tendencia se encuentre con el metaverso en unos años y se generen mundos de realidad virtual en tiempo real, solo para ti?
Todas estas son preguntas importantes a considerar.
Algunos especulan que, a corto plazo, esto significa que la creatividad humana y el arte están profundamente amenazados.
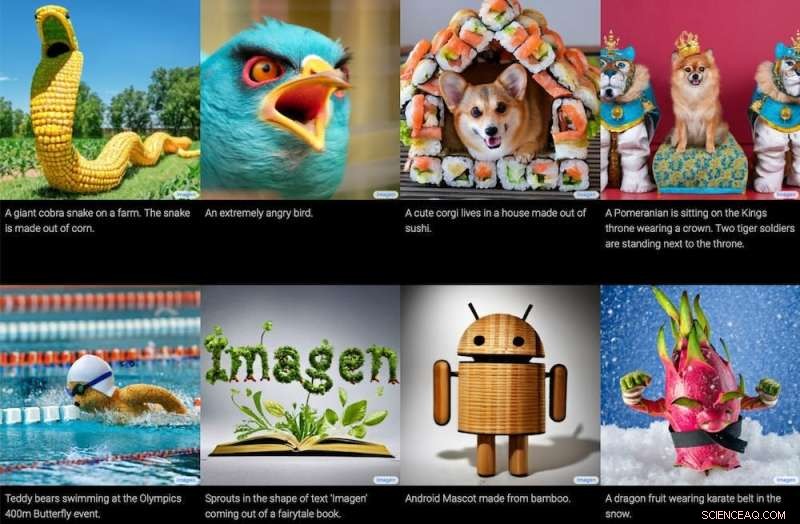
Images generated by the Imagen text-to-image model, together with the text that produced them. Google / Imagen
Perhaps in a world where anyone can generate any images, graphic designers as we know them today will be redundant. However, history shows human creativity finds a way. The electronic synthesizer did not kill music, and photography did not kill painting. Instead, they catalyzed new art forms.
I believe something similar will happen with AI generation. People are experimenting with including models like Stable Diffusion as a part of their creative process.
Or using DALL-E 2 to generate fashion-design prototypes:
Want to use @StableDiffusion right from #Photoshop? Now you can!https://t.co/gqFWpABQLY pic.twitter.com/LbgSWZz31L
— Christian Cantrell (@cantrell) September 8, 2022
A new type of artist is even emerging in what some call "promptology," or "prompt engineering". The art is not in crafting pixels by hand, but in crafting the words that prompt the computer to generate the image:a kind of AI whispering.
Collaborating with AI
The impacts of AI technologies will be multidimensional:we cannot reduce them to good or bad on a single axis.
New artforms will arise, as will new avenues for creative expression. However, I believe there are risks as well.
We live in an attention economy that thrives on extracting screen time from users; in an economy where automation drives corporate profit but not necessarily higher wages, and where art is commodified as content; in a social context where it is increasingly hard to distinguish real from fake; in sociotechnical structures that too easily encode biases in the AI models we train. In these circumstances, AI can easily do harm.
How can we steer these new AI technologies in a direction that benefits people? I believe one way to do this is to design AI that collaborates with, rather than replaces, humans.
Este artículo se vuelve a publicar de The Conversation bajo una licencia Creative Commons. Lea el artículo original. AI system makes image generator models like DALL-E 2 more creative