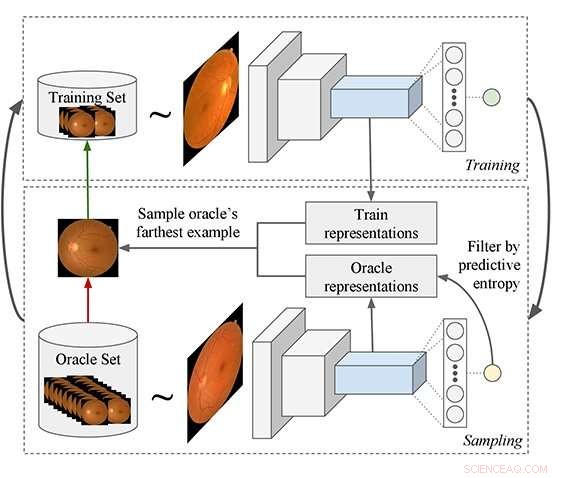
Canalización de aprendizaje activo propuesta:el proceso comienza con la capacitación de un modelo y su uso para consultar ejemplos de un conjunto de datos sin etiquetar que luego se agregan al conjunto de capacitación. Se propone una función de consulta novedosa que se adapta mejor a los modelos de aprendizaje profundo (DL). El modelo DL se utiliza para extraer características de los ejemplos de conjuntos de entrenamiento y de Oracle, y luego el algoritmo filtra los ejemplos de oráculo que tienen una entropía predictiva baja. Finalmente, Se selecciona el ejemplo de oráculo que, en promedio, es el más distante en el espacio de características de todos los ejemplos de entrenamiento. Crédito:Asim Smailagic
A medida que los sistemas de inteligencia artificial aprenden a reconocer y clasificar mejor las imágenes, se están volviendo altamente confiables en el diagnóstico de enfermedades, como el cáncer de piel, a partir de imágenes médicas. Pero a pesar de lo buenos que son para detectar patrones, La IA no reemplazará a su médico en el corto plazo. Incluso cuando se utiliza como herramienta, Los sistemas de reconocimiento de imágenes aún requieren que un experto etiquete los datos, y muchos datos además:necesita imágenes tanto de pacientes sanos como de pacientes enfermos. El algoritmo encuentra patrones en los datos de entrenamiento y cuando recibe nuevos datos, usa lo que ha aprendido para identificar la nueva imagen.
Un desafío es que para un experto es costoso y lento obtener y etiquetar cada imagen. Para abordar este asunto, un grupo de investigadores de la Facultad de Ingeniería de la Universidad Carnegie Mellon, incluidos los profesores Hae Young Noh y Asim Smailagic, se unieron para desarrollar una técnica de aprendizaje activo que utiliza un conjunto de datos limitado para lograr un alto grado de precisión en el diagnóstico de enfermedades como la retinopatía diabética o el cáncer de piel.
El modelo de los investigadores comienza a trabajar con un conjunto de imágenes sin etiquetar. El modelo decide cuántas imágenes etiquetar para tener un conjunto sólido y preciso de datos de entrenamiento. Elige un conjunto inicial de datos aleatorios para etiquetar. Una vez que esos datos están etiquetados, traza esos datos sobre una distribución porque las imágenes variarán según la edad, género, propiedad fisica, etc. Para tomar una buena decisión basada en estos datos, las muestras deben cubrir un gran espacio de distribución. Luego, el sistema decide qué datos nuevos deben agregarse al conjunto de datos, considerando la distribución actual de datos.
"El sistema mide qué tan óptima es esta distribución, "dijo Noh, un profesor asociado de ingeniería civil y ambiental, "y luego calcula métricas cuando se le agrega un determinado conjunto de datos nuevos, y selecciona el nuevo conjunto de datos que maximiza su optimización ".
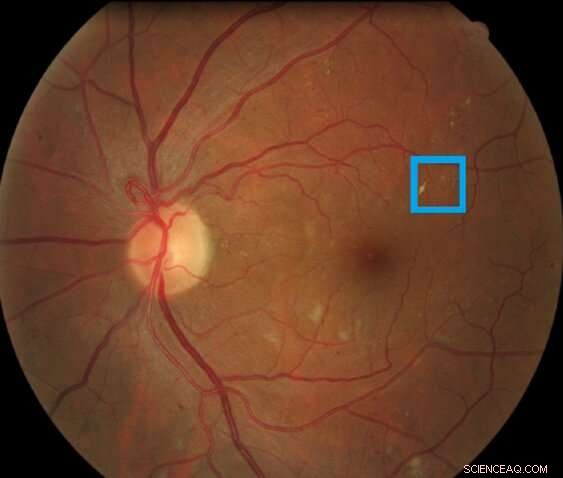
Imagen de una retina que contiene una lesión retiniana asociada a retinopatía diabética resaltada en el recuadro. Este tipo de lesión se llama microaneurisma. Crédito:Asim Smailagic
El proceso se repite hasta que el conjunto de datos tiene una distribución lo suficientemente buena como para ser utilizado como conjunto de entrenamiento. Su método, llamado MedAL (para el aprendizaje médico activo), logró un 80% de precisión en la detección de la retinopatía diabética, utilizando solo 425 imágenes etiquetadas, que es una reducción del 32% en el número de ejemplos etiquetados requeridos en comparación con la técnica de muestreo de incertidumbre estándar, y una reducción del 40% en comparación con el muestreo aleatorio.
También probaron el modelo en otras enfermedades, incluyendo imágenes de cáncer de piel y de mama, para mostrar que podría aplicarse a una variedad de imágenes médicas diferentes. El método es generalizable, ya que su enfoque está en cómo usar los datos de manera estratégica en lugar de tratar de encontrar un patrón o característica específica para una enfermedad. También podría aplicarse a otros problemas que utilizan el aprendizaje profundo pero tienen limitaciones de datos.
"Nuestro enfoque de aprendizaje activo combina un muestreo de incertidumbre basado en entropía predictiva y una función de distancia en un espacio de características aprendidas para optimizar la selección de muestras sin etiquetar, "dijo Smailagic, profesor de investigación en el Acelerador de Investigación de Ingeniería de Carnegie Mellon. "El método supera las limitaciones de los enfoques tradicionales al seleccionar de manera eficiente solo las imágenes que brindan la mayor cantidad de información sobre la distribución general de datos, reduciendo el costo de computación y aumentando tanto la velocidad como la precisión ".
El equipo incluía un doctorado en ingeniería civil y ambiental. estudiantes Mostafa Mirshekari, Jonathon Fagert, y Susu Xu, y los estudiantes de maestría en ingeniería eléctrica e informática Devesh Walawalkar y Kartik Khandelwal. Presentaron sus hallazgos en la Conferencia Internacional IEEE 2018 sobre Aprendizaje Automático y Aplicaciones en diciembre, donde recibieron un premio al mejor artículo por su trabajo novedoso.