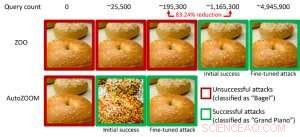
Figura 1:Comparación de rendimiento al convertir una imagen de bagel en una imagen de bagel adversaria clasificada como un "piano de cola" mediante ataques ZOO y AutoZOOM. Crédito:IBM
Estudios recientes han identificado la falta de robustez en los modelos de IA actuales frente a ejemplos contradictorios:entradas de datos evasivas de predicción manipuladas intencionalmente que son similares a los datos normales pero que harán que los modelos de IA bien entrenados se comporten mal. Por ejemplo, Las perturbaciones visualmente imperceptibles de una señal de alto se pueden diseñar fácilmente y llevar a un modelo de IA de alta precisión a una clasificación errónea. En nuestro artículo anterior publicado en la European Conference on Computer Vision (ECCV) en 2018, validamos que 18 modelos de clasificación diferentes entrenados en ImageNet, un gran conjunto de datos de reconocimiento de objetos públicos, todos son vulnerables a las perturbaciones adversas.
Notablemente, Los ejemplos contradictorios a menudo se generan en la configuración de "caja blanca", donde el modelo de IA es completamente transparente para un adversario. En el escenario práctico, al implementar un modelo de IA autodidacta como servicio, como una API de clasificación de imágenes en línea, uno puede creer falsamente que es robusto a los ejemplos contradictorios debido al acceso limitado y al conocimiento sobre el modelo de IA subyacente (también conocido como la configuración de "caja negra"). Sin embargo, Nuestro trabajo reciente publicado en AAAI 2019 muestra que la solidez debido al acceso limitado del modelo no está fundamentada. Proporcionamos un marco general para generar ejemplos contradictorios a partir del modelo de IA específico utilizando solo las respuestas de entrada y salida del modelo y algunas consultas del modelo. En comparación con el trabajo anterior (ataque ZOO), nuestro marco propuesto, llamado AutoZOOM, reduce al menos un 93% de consultas de modelos en promedio mientras logra un rendimiento de ataque similar, Proporcionar una metodología de consulta eficiente para evaluar la solidez contradictoria de los sistemas de IA con acceso limitado. Un ejemplo ilustrativo se muestra en la Figura 1, donde una imagen de bagel de adversario generada a partir de un clasificador de imágenes de caja negra se clasificará como el objetivo del ataque "piano de cola". Este artículo es seleccionado para presentación oral (29 de enero de 11:30-12:30 pm @ coral 1) y presentación de póster (29 de enero, 6:30-8:30 pm) en AAAI 2019.
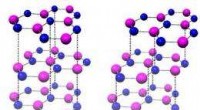
En la configuración de caja blanca, Los ejemplos adversarios a menudo se elaboran aprovechando el gradiente de un objetivo de ataque diseñado en relación con la entrada de datos para orientar la perturbación adversaria. lo que requiere conocer la arquitectura del modelo, así como los pesos del modelo para la inferencia. Sin embargo, en la configuración de caja negra, la adquisición del gradiente no es factible debido al acceso limitado a estos detalles del modelo. En lugar de, un adversario solo puede acceder a las respuestas de entrada-salida del modelo de IA implementado, al igual que los usuarios habituales (p. ej., cargar una imagen y recibir la predicción de una API de clasificación de imágenes en línea). Se demostró por primera vez en el ataque ZOO que es posible generar ejemplos contradictorios a partir de modelos con acceso limitado mediante el uso de técnicas de estimación de gradientes. Sin embargo, puede ser necesaria una gran cantidad de consultas de modelos para elaborar un ejemplo contradictorio. Por ejemplo, en la Figura 1, El ataque ZOO requiere más de 1 millón de consultas de modelos para encontrar la imagen del bagel del adversario. Para acelerar la eficiencia de las consultas en la búsqueda de ejemplos contradictorios en la configuración de caja negra, nuestro marco AutoZOOM propuesto tiene dos bloques de construcción novedosos:(i) una estrategia de estimación de gradiente aleatorio adaptativa para equilibrar el conteo de consultas y la distorsión, y (ii) un codificador automático que está entrenado fuera de línea con datos sin etiquetar o una operación de cambio de tamaño bilineal para la aceleración. Para (i), AutoZOOM presenta un estimador de gradientes optimizado y eficiente para consultas, que tiene un esquema adaptativo que utiliza pocas consultas para encontrar la primera perturbación adversaria exitosa y luego utiliza más consultas para afinar la distorsión y hacer que el ejemplo adversario sea más realista. Para (ii), como se muestra en la Figura 2, AutoZOOM implementa una técnica llamada "reducción de dimensión" para reducir la complejidad de encontrar ejemplos contradictorios. La reducción de dimensión puede realizarse mediante un codificador automático entrenado fuera de línea para capturar las características de los datos o un simple cambio de tamaño de imagen bilineal que no requiere ningún entrenamiento.
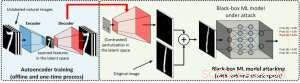
Figura 2:Ilustración de la técnica de reducción de dimensión utilizada en AutoZOOM para canjes de consultas. El decodificador puede ser un codificador automático entrenado fuera de línea o una operación de cambio de tamaño bilineal que no requiere ningún entrenamiento. Crédito:IBM
Con estas dos técnicas básicas, nuestros experimentos en clasificadores de imágenes basados en redes neuronales profundas de caja negra entrenados en MNIST, CIFAR-10 e ImageNet muestran que AutoZOOM logra un rendimiento de ataque similar al tiempo que logra una reducción significativa (al menos 93%) en el recuento de consultas promedio en comparación con el ataque ZOO. En ImageNet, esta drástica reducción significa millones de consultas de modelos menos, lo que hace que AutoZOOM sea una herramienta eficiente y práctica para evaluar la solidez contradictoria de los modelos de IA con acceso limitado. Es más, AutoZOOM es un acelerador de canje de consultas general que se puede aplicar fácilmente a diferentes métodos para generar ejemplos de confrontación en la práctica configuración de caja negra.
El código AutoZOOM es de código abierto y se puede encontrar aquí. Consulte también la Caja de herramientas de robustez contra adversarios de IBM para obtener más implementaciones sobre defensas y ataques contra adversarios.
Esta historia se vuelve a publicar por cortesía de IBM Research. Lea la historia original aquí.