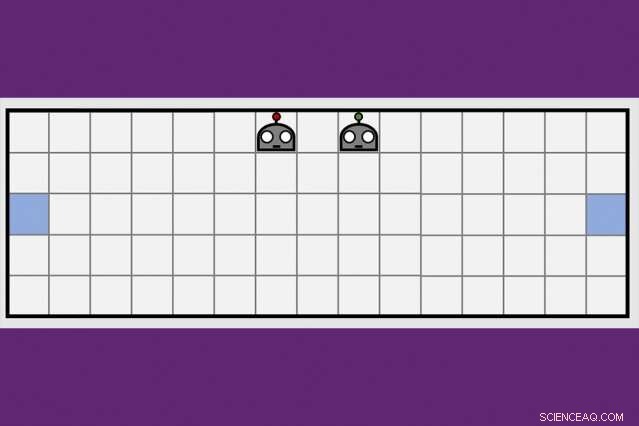
Usando una nueva técnica de aprendizaje cooperativo, Los investigadores del MIT-IBM Watson AI Lab redujeron a la mitad el tiempo que les tomó a un par de agentes robóticos aprender a maniobrar hacia lados opuestos de una sala virtual. Crédito:Dong-ki Kim
Los primeros programas de inteligencia artificial para derrotar a los mejores jugadores del mundo en el ajedrez y el juego Go recibieron al menos algunas instrucciones de los humanos. y ultimamente, no sería rival para una nueva generación de programas de IA que aprenden completamente por sí mismos, a través de prueba y error.
Una combinación de algoritmos de aprendizaje profundo y aprendizaje reforzado es responsable de que las computadoras logren el dominio en juegos de mesa desafiantes como el ajedrez y el Go. un número creciente de videojuegos, incluida la Sra. Pac-Man, y algunos juegos de cartas, incluido el póquer. Pero a pesar de todo el progreso, las computadoras aún se atascan cuanto más se asemeja un juego a la vida real, con información oculta, varios jugadores, juego continuo, y una combinación de recompensas a corto y largo plazo que hacen que calcular el movimiento óptimo sea desesperadamente complejo.
Para superar estos obstáculos Los investigadores de IA están explorando técnicas complementarias para ayudar a los agentes robóticos a aprender, siguiendo el modelo de la forma en que los humanos recogen nueva información no solo por nuestra cuenta, pero de la gente que nos rodea, y de los periódicos, libros, y otros medios. Una estrategia de aprendizaje colectivo desarrollada por MIT-IBM Watson AI Lab ofrece una nueva dirección prometedora. Los investigadores muestran que un par de agentes robot pueden reducir el tiempo que lleva aprender una tarea de navegación simple en un 50 por ciento o más cuando los agentes aprenden a aprovechar el creciente cuerpo de conocimientos de los demás.
El algoritmo les enseña a los agentes cuándo pedir ayuda, y cómo adaptar sus consejos a lo aprendido hasta ese momento. El algoritmo es único en el sentido de que ninguno de los agentes es un experto; cada uno es libre de actuar como alumno-maestro para solicitar y ofrecer más información. Los investigadores están presentando su trabajo esta semana en la Conferencia AAAI sobre Inteligencia Artificial en Hawai.
Coautores del artículo, que recibió una mención de honor al mejor trabajo estudiantil en AAAI, son Jonathan How, profesor del Departamento de Aeronáutica y Astronáutica del MIT; Shayegan Omidshafiei, un ex estudiante graduado del MIT ahora en DeepMind de Alphabet; Dong-ki Kim del MIT; Miao Liu, Gerald Tesauro, Matthew Riemer, y Murray Campbell de IBM; y Christopher Amato de Northeastern University.
"Esta idea de proporcionar acciones para mejorar al máximo el aprendizaje del estudiante, en lugar de decirle qué hacer, es potencialmente bastante poderoso, "dice Matthew E. Taylor, director de investigación de Borealis AI, el brazo de investigación del Royal Bank of Canada, que no participó en la investigación. "Si bien el documento se centra en escenarios relativamente simples, Creo que el marco alumno / profesor podría ampliarse y ser útil en videojuegos multijugador como Dota 2, fútbol robot, o escenarios de recuperación ante desastres ".
Por ahora, los profesionales todavía tienen la ventaja en Dota2, y otros juegos virtuales que favorecen el trabajo en equipo y la rapidez, pensamiento estrategico. (Aunque el brazo de investigación de IA de Alphabet, Mente profunda, fue noticia recientemente después de derrotar a un jugador profesional en el juego de estrategia en tiempo real, Starcraft.) Pero a medida que las máquinas mejoran en la maniobra de entornos dinámicos, Es posible que pronto estén listos para tareas del mundo real, como administrar el tráfico en una gran ciudad o coordinar equipos de búsqueda y rescate en tierra y en el aire.
"Las máquinas carecen del conocimiento de sentido común que desarrollamos cuando somos niños, "dice Liu, un ex postdoctorado del MIT ahora en el laboratorio MIT-IBM. "Por eso necesitan ver millones de fotogramas de vídeo, y dedicar mucho tiempo a los cálculos aprender a jugar bien un juego. Incluso entonces, carecen de formas eficientes de transferir sus conocimientos al equipo, o generalizar sus habilidades a un nuevo juego. Si podemos entrenar a los robots para que aprendan de los demás, y generalizar su aprendizaje a otras tareas, podemos empezar a coordinar mejor sus interacciones entre nosotros, y con los humanos ".
La idea clave del equipo de MIT-IBM fue que un equipo que se divide y conquista para aprender una nueva tarea, en este caso, maniobrar hacia los extremos opuestos de una habitación y tocar la pared al mismo tiempo, aprenderá más rápido.
Su algoritmo de enseñanza alterna entre dos fases. En el primero, tanto el alumno como el profesor deciden con cada paso respectivo si solicitar, o dar, asesoramiento basado en su confianza en que el próximo paso, o el consejo que van a dar, los acercará a su objetivo. Por lo tanto, el alumno solo pide consejo, y el maestro solo lo da, cuando es probable que la información agregada mejore su desempeño. Con cada paso, los agentes actualizan sus respectivas políticas de tareas y el proceso continúa hasta que alcanzan su objetivo o se les acaba el tiempo.
Con cada iteración, el algoritmo registra las decisiones del estudiante, el consejo del maestro, y su progreso de aprendizaje medido por la puntuación final del juego. En la segunda fase, una técnica de aprendizaje por refuerzo profundo utiliza los datos de enseñanza previamente registrados para actualizar ambas políticas de asesoramiento. "Con cada actualización, el profesor mejora en dar los consejos adecuados en el momento adecuado, "dice Kim, estudiante de posgrado en el MIT.
En un documento de seguimiento que se discutirá en un taller en AAAI, los investigadores mejoran la capacidad del algoritmo para rastrear qué tan bien los agentes están aprendiendo la tarea subyacente; en este caso, una tarea de empujar cajas:mejorar la capacidad de los agentes para dar y recibir consejos. Es otro paso que acerca al equipo a su objetivo a largo plazo de ingresar a la RoboCup, una competencia anual de robótica iniciada por investigadores académicos de IA.
"Necesitaríamos escalar a 11 agentes antes de poder jugar un partido de fútbol, "dice Tesauro, un investigador de IBM que desarrolló el primer programa de inteligencia artificial para dominar el juego de backgammon. "Va a requerir un poco más de trabajo, pero tenemos esperanzas".
Esta historia se vuelve a publicar por cortesía de MIT News (web.mit.edu/newsoffice/), un sitio popular que cubre noticias sobre la investigación del MIT, innovación y docencia.