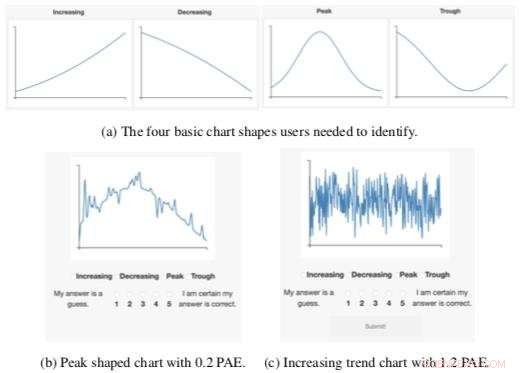
Figura que muestra un ejemplo de uno de los estudios de usuarios, en el que los usuarios tenían que clasificar los gráficos en función de su forma. El gráfico de la derecha muestra un ejemplo de un gráfico complejo que recibiría una puntuación de alta complejidad (c). Intuitivamente, es más difícil de leer que el gráfico de la izquierda. Para mejorar la legibilidad, un programa de visualización podría mejorar aspectos importantes de los datos para facilitar su lectura. Crédito:Gabriel Ryan, Wu Lab / Columbia Engineering
Doctores que leen electroencefalogramas en salas de emergencia, socorristas que miran varias pantallas que muestran datos en vivo de sensores en una zona de desastre, Los corredores que compran y venden instrumentos financieros deben tomar decisiones informadas con mucha rapidez. La complejidad de la visualización puede complicar la toma de decisiones cuando uno está mirando datos en un gráfico. Cuando el tiempo es crítico, es fundamental que un gráfico sea fácil de leer e interpretar.
Para ayudar a los tomadores de decisiones en escenarios como estos, Los informáticos de Columbia Engineering y Tufts University han desarrollado un nuevo método, "Entropía aproximada de píxeles", que mide la complejidad de una visualización de datos y se puede utilizar para desarrollar visualizaciones más fáciles de leer. Eugene Wu, profesor asistente de informática, y Gabriel Ryan, que entonces era estudiante de maestría y ahora Ph.D. estudiante en Columbia, presentará su artículo en la conferencia IEEE VIS 2018 el jueves, 25 de octubre en Berlín, Alemania.
"Este es un enfoque completamente nuevo para trabajar con gráficos de líneas con muchas aplicaciones potenciales diferentes, "dice Ryan, primer autor del artículo. "Nuestro método proporciona a los sistemas de visualización una forma de medir la dificultad de leer los gráficos de líneas, por lo que ahora podemos diseñar estos sistemas para simplificar o resumir automáticamente gráficos que serían difíciles de leer por sí mismos ".
Aparte de inspeccionar visualmente una visualización, Ha habido pocas formas de cuantificar automáticamente la complejidad de una visualización de datos. Para resolver este problema, El grupo de Wu creó Pixel Approximate Entropy para proporcionar una "puntuación de complejidad visual" que puede identificar automáticamente gráficos difíciles. Modificaron una medida de entropía de baja dimensión para operar en gráficos de líneas, y luego realizó una serie de estudios de usuarios que demostraron que la medida podía predecir qué tan bien los usuarios percibían los gráficos.
"En entornos de ritmo rápido, es importante saber si la visualización va a ser tan compleja que las señales pueden oscurecerse, "dice Wu, quien también es copresidente de los datos, Medios de comunicación, &Society Center en el Data Science Institute. "La capacidad de cuantificar la complejidad es el primer paso para hacer algo automáticamente al respecto".
El equipo espera su sistema, que es de código abierto, será especialmente útil para los científicos e ingenieros de datos que están desarrollando sistemas de ciencia de datos impulsados por IA. Al proporcionar un método que permite al sistema comprender mejor las visualizaciones que muestra, La entropía aproximada de píxeles ayudará a impulsar el desarrollo de sistemas de ciencia de datos más inteligentes.
"Por ejemplo, en el control industrial, un operador puede necesitar observar y reaccionar a las tendencias en las lecturas de una variedad de monitores del sistema a lo largo del tiempo, como en una planta química o de energía, Ryan agrega. “Un sistema que sea consciente de la complejidad de los gráficos podría adaptar las lecturas para garantizar que el operador pueda identificar tendencias importantes y reducir la fatiga al intentar interpretar señales potencialmente ruidosas.
El grupo de Wu planea extender la visualización de datos para usar estos modelos para alertar automáticamente a los usuarios y diseñadores cuando las visualizaciones pueden ser demasiado complejas y sugerir técnicas de suavizado. y desarrollar otros modelos perceptuales cuantitativos que puedan informar el diseño de sistemas de procesamiento y visualización de datos.