Planificador de movimiento de conducción autónoma basado en datos en la plataforma Apollo. Crédito:Fan et al.
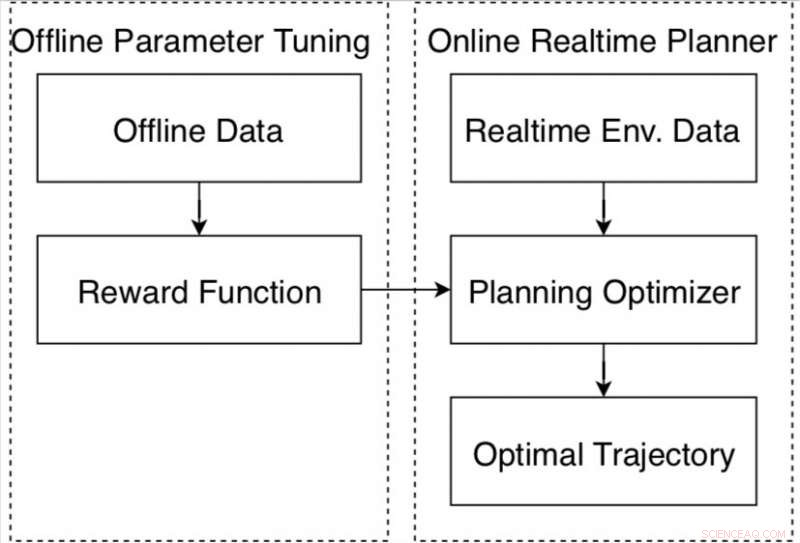
Investigadores de la empresa multinacional de tecnología china Baidu han desarrollado recientemente un marco de autoajuste basado en datos para vehículos autónomos basado en la plataforma de conducción autónoma Apollo. El marco, presentado en un artículo publicado previamente en arXiv, consiste en un nuevo algoritmo de aprendizaje por refuerzo y una estrategia de entrenamiento fuera de línea, así como un método automático de recopilación y etiquetado de datos.
Un planificador de movimiento para la conducción autónoma es un sistema diseñado para generar una trayectoria segura y cómoda para llegar al destino deseado. Diseñar y poner a punto estos sistemas para garantizar que funcionen bien en diferentes condiciones de conducción es una tarea difícil que varias empresas e investigadores de todo el mundo están tratando de abordar actualmente.
"La planificación de movimiento para vehículos de conducción autónoma tiene muchos problemas, "Fan Haoyang, uno de los investigadores que realizó el estudio, le dijo a Tech Xplore. "Uno de los principales desafíos es que tiene que lidiar con miles de escenarios diferentes. Por lo general, definimos un ajuste funcional de recompensa / costo que puede adaptar esas diferencias en los escenarios. Sin embargo, nos parece una tarea difícil ".
Típicamente, El ajuste funcional del costo de recompensa requiere un trabajo extenso por parte de los investigadores, así como los recursos y el tiempo dedicados tanto a las simulaciones como a las pruebas en carretera. Además, el entorno puede cambiar drásticamente con el tiempo y a medida que las condiciones de conducción se vuelven más complicadas, ajustar el rendimiento del planificador de movimiento se vuelve cada vez más difícil.

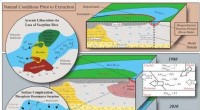
Bucle de ajuste de algoritmo para el planificador de movimiento en la plataforma de conducción autónoma Apollo. Crédito:Fan et al.
"Para resolver sistemáticamente este problema, Desarrollamos un marco de autoajuste basado en datos basado en el marco de conducción autónoma de Apollo, ", Dijo Fan." La idea del autoajuste es aprender los parámetros de los datos de conducción demostrados por humanos. Por ejemplo, nos gustaría comprender a partir de los datos cómo los conductores humanos equilibran la velocidad y la comodidad de conducción con las distancias de los obstáculos. Pero en escenarios más complicados, por ejemplo, una ciudad llena de gente, ¿Qué podemos aprender de los conductores humanos? "
El marco de autoajuste desarrollado en Baidu incluye un nuevo algoritmo de aprendizaje por refuerzo, que puede aprender de los datos y mejorar su rendimiento con el tiempo. En comparación con la mayoría de los algoritmos de aprendizaje por refuerzo inverso, se puede aplicar eficazmente a diferentes escenarios de conducción.
El marco también incluye una estrategia de formación fuera de línea, ofreciendo una forma segura para que los investigadores ajusten los parámetros antes de probar un vehículo autónomo en la vía pública. También recopila datos de conductores expertos e información sobre el medio ambiente, etiquetarlos automáticamente para que puedan ser analizados por el algoritmo de aprendizaje por refuerzo.
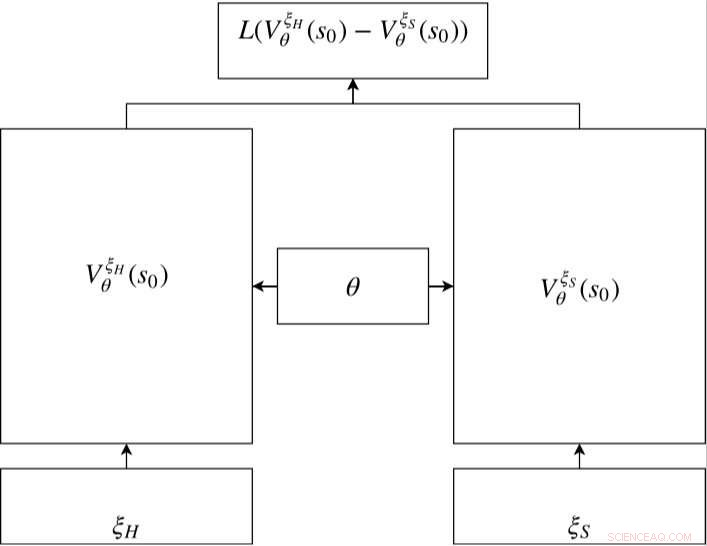
Red siamesa en RC-IRL. Las redes de valores de las trayectorias humana y muestreada comparten la misma configuración de parámetros de red. La función de pérdida evalúa la diferencia entre los datos muestreados y la trayectoria generada a través de las salidas de la red de valores. Crédito:Fan et al.
"Creo que desarrollamos una canalización segura para hacer un sistema escalable de aprendizaje automático mediante el uso de datos de demostración humana, "Fan dijo." Los datos de demostración humana de circuito abierto se recopilan y no necesitan etiquetado adicional. Dado que el proceso de formación también se realiza sin conexión, nuestro método es adecuado para la planificación del movimiento de conducción autónoma, mantener la seguridad de las pruebas públicas en la carretera ".
Los investigadores evaluaron un planificador de movimiento ajustado utilizando su marco tanto en simulaciones como en pruebas en carreteras públicas. En comparación con los enfoques existentes, su método basado en datos pudo adaptarse mejor a diferentes escenarios de conducción, desempeñándose consistentemente bien bajo una variedad de condiciones.
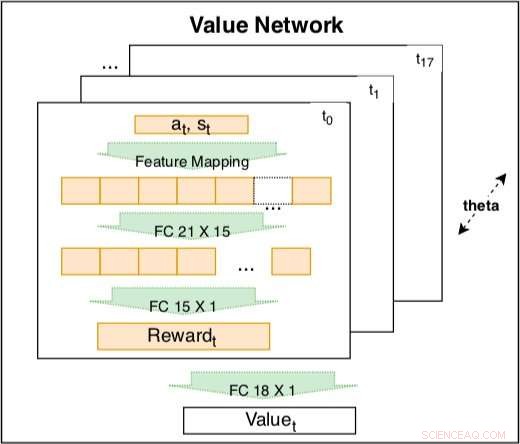
La red de valor dentro del modelo siamés se utiliza para capturar el comportamiento de conducción basado en características codificadas. La red es una combinación lineal entrenable de recompensas codificadas en diferentes momentos t =t0, ..., t17. El peso de la recompensa codificada es un factor de disminución del tiempo que se puede aprender. La recompensa codificada incluye una capa de entrada con 21 características sin procesar y una capa oculta con 15 nodos para cubrir posibles interacciones. Los parámetros de la recompensa en diferentes momentos comparten el mismo θ para mantener la coherencia. Crédito:Fan et al.
"Nuestra investigación se basa en la plataforma de conducción autónoma de código abierto Baidu Apollo, ", Dijo Fan." Esperamos que más y más personas de la academia y la industria puedan contribuir al ecosistema de conducción autónoma a través de Apollo. En el futuro, planeamos mejorar el marco actual de Baidu Apollo a un sistema escalable de aprendizaje automático que puede mejorar sistemáticamente la cobertura de escenarios de los vehículos de conducción autónoma ".
© 2018 Tech Xplore