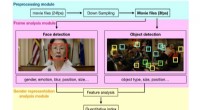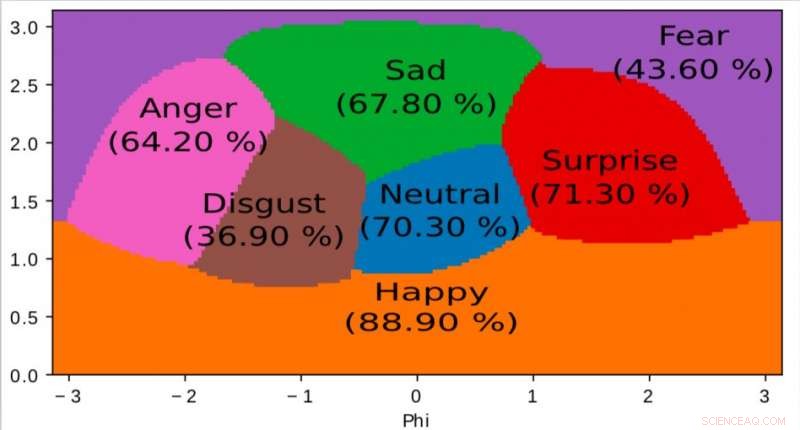
Una representación del espacio interno aprendido por nuestro algoritmo y utilizado para mapear emociones en un espacio continuo 2D. Es interesante notar que incluso si los datos de entrenamiento solo contienen etiquetas de emoción discretas, la red aprende un espacio continuo, permitiendo no solo describir con precisión el estado emocional de las personas, sino también posicionar las emociones en relación con los demás. Este espacio tiene una fuerte similitud con el espacio de valencia de excitación definido por la psicología moderna. Crédito:Jurie et al.
Investigadores de Orange Labs y Normandie University han desarrollado un nuevo modelo neuronal profundo para el reconocimiento de emociones audiovisuales que funciona bien con pequeños conjuntos de entrenamiento. Su estudio, que fue prepublicado en arXiv , sigue una filosofía de sencillez, limitando sustancialmente los parámetros que el modelo adquiere de los conjuntos de datos y utilizando técnicas de aprendizaje simples.
Las redes neuronales para el reconocimiento de emociones tienen una serie de aplicaciones útiles dentro de los contextos de la atención médica, análisis de clientes, vigilancia, e incluso animación. Si bien los algoritmos de aprendizaje profundo de última generación han logrado resultados notables, la mayoría todavía son incapaces de alcanzar la misma comprensión de las emociones alcanzada por los humanos.
"Nuestro objetivo general es facilitar la interacción humano-computadora al hacer que las computadoras puedan percibir varios detalles sutiles expresados por humanos, "Frédéric Jurie, uno de los investigadores que realizó el estudio, dijo a TechXplore. "Percibir emociones contenidas en imágenes, video, la voz y el sonido caen dentro de este contexto ".
Recientemente, Los estudios han reunido conjuntos de datos multimodales y temporales que contienen videos comentados y clips audiovisuales. Sin embargo, estos conjuntos de datos suelen contener una cantidad relativamente pequeña de muestras anotadas, mientras que para desempeñarse bien, la mayoría de los algoritmos de aprendizaje profundo existentes requieren conjuntos de datos más grandes.
Los investigadores intentaron abordar este problema desarrollando un nuevo marco para el reconocimiento de emociones audiovisuales, que fusiona el análisis de metraje visual y de audio, conservando un alto nivel de precisión incluso con conjuntos de datos de entrenamiento relativamente pequeños. Entrenaron su modelo neuronal en AFEW, un conjunto de datos de 773 clips audiovisuales extraídos de películas y anotados con emociones discretas.

Ilustración de cómo se puede utilizar este espacio 2D para controlar las emociones expresadas por los rostros, de forma continua, con la ayuda de redes generativas adversarias (GAN). Crédito:Jurie et al.
"Se puede ver este modelo como una caja negra que procesa el video e infiere automáticamente el estado emocional de las personas, "Jurie explicó." Una gran ventaja de modelos neuronales tan profundos es que aprenden por sí mismos cómo procesar el video mediante el análisis de ejemplos, y no requieren que los expertos proporcionen unidades de procesamiento específicas ".
El modelo ideado por los investigadores sigue el principio filosófico de la navaja de Occam, lo que sugiere que entre dos enfoques o explicaciones, el más simple es la mejor opción. A diferencia de otros modelos de aprendizaje profundo para el reconocimiento de emociones, por lo tanto, su modelo se mantiene relativamente simple. La red neuronal aprende un número limitado de parámetros del conjunto de datos y emplea estrategias básicas de aprendizaje.
"La red propuesta está formada por capas de procesamiento en cascada que abstraen la información, desde la señal hasta su interpretación, "Dijo Jurie." El audio y el video son procesados por dos canales diferentes de la red y se combinan últimamente en el proceso, casi al final ".
Cuando se prueba, su modelo de luz logró una prometedora precisión en el reconocimiento de emociones del 60,64 por ciento. También ocupó el cuarto lugar en el desafío Emotion Recognition in the Wild (EmotiW) de 2018, celebrada en la Conferencia Internacional ACM sobre Interacción Multimodal (ICMI), En colorado.

Ilustración de cómo se puede utilizar este espacio 2D para controlar las emociones expresadas por los rostros, de forma continua, con la ayuda de redes generativas adversarias (GAN). Crédito:Jurie et al.
"Nuestro modelo es una prueba de que siguiendo el principio de la navaja de Occam, es decir., eligiendo siempre las alternativas más simples para diseñar redes neuronales, es posible limitar el tamaño de los modelos y obtener redes neuronales muy compactas pero de última generación, que son más fáciles de entrenar, ", Dijo Jurie." Esto contrasta con la tendencia de la investigación de hacer que las redes neuronales sean cada vez más grandes ".
Los investigadores ahora continuarán explorando formas de lograr una alta precisión en el reconocimiento de emociones mediante el análisis simultáneo de datos visuales y auditivos. utilizando los conjuntos de datos de entrenamiento anotados limitados que están disponibles actualmente.
"Estamos interesados en varias direcciones de investigación, por ejemplo, cómo fusionar mejor las diferentes modalidades, cómo representar la emoción mediante descriptores completos compactos de significado semántico (y no solo etiquetas de clase) o cómo hacer que nuestros algoritmos sean capaces de aprender con menos, o incluso sin, datos anotados, "Dijo Jurie.
© 2018 Tech Xplore