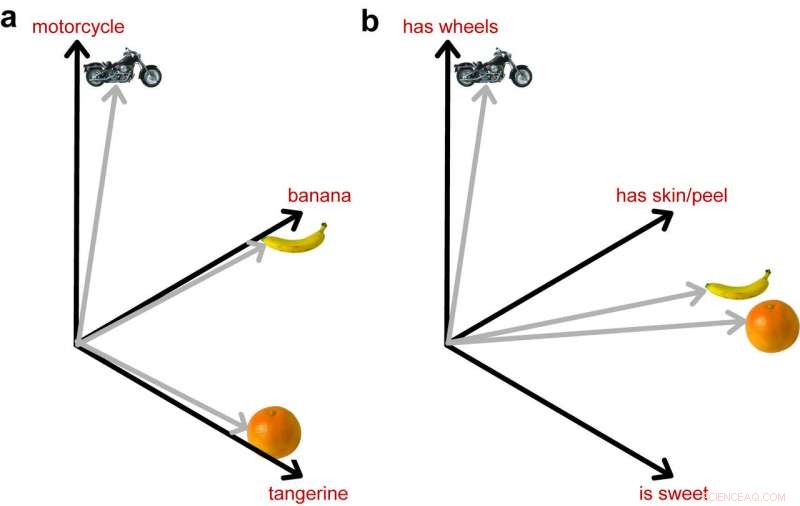
La imagen de la izquierda muestra cómo los DNN entrenados para identificar objetos representan estas 3 imágenes como igualmente diferentes. La imagen de la derecha muestra el importante papel que juega la información semántica al acercar las dos frutas en el espacio, ya que están más cerca en su significado. Crédito:Lorraine Tyler et al.
Los investigadores de neurociencia de la Universidad de Cambridge han combinado la visión por computadora con la semántica, desarrollar un nuevo modelo que podría ayudar a comprender mejor cómo se procesan los objetos en el cerebro.
La capacidad humana de reconocer objetos implica dos procesos principales, un rápido análisis visual del objeto y la activación del conocimiento semántico adquirido a lo largo de la vida. La mayoría de los estudios anteriores han investigado estos dos procesos por separado; por lo tanto, su interacción sigue siendo poco clara.
El equipo de investigadores de Cambridge ha investigado los procesos de reconocimiento de objetos utilizando un nuevo método que combina redes neuronales profundas con un modelo semántico de red atractora. En contraste con la mayoría de los estudios anteriores, su técnica da cuenta tanto de la información visual como del conocimiento conceptual sobre los objetos.
"Anteriormente habíamos realizado muchas investigaciones con personas sanas y pacientes con daño cerebral para comprender mejor cómo se procesan los objetos en el cerebro". "dijeron los investigadores de Cambridge Tech Xplore . "Una de las principales contribuciones de este trabajo es mostrar que comprender qué es un objeto implica que la información visual se transforme rápidamente con el tiempo en una representación significativa, y este proceso de transformación se logra a lo largo del lóbulo temporal ventral ".
Los investigadores creen firmemente que acceder a la memoria semántica es una parte clave para comprender qué es un objeto, de modo que las teorías que solo se centran en las propiedades relacionadas con la visión no captan completamente este complejo proceso.
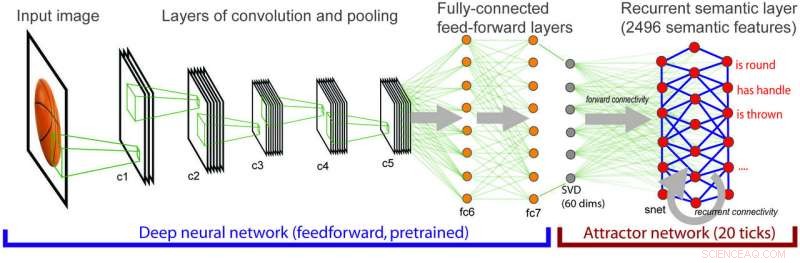
Arquitectura del modelo integrado donde la información visual cada vez más compleja se mapea sobre información semántica. Crédito:Lorraine Tyler et al.
"Este fue el detonante inicial de la investigación actual, donde queríamos comprender completamente cómo las entradas visuales de bajo nivel se asignan a una representación semántica del significado del objeto, "explicaron los investigadores. Para ello, utilizaron una red neuronal profunda estándar especializada en visión por computadora, llamado AlexNet.
"Este modelo, y a otros les gusta, puede identificar objetos en imágenes con una precisión muy alta, pero no incluyen ningún conocimiento explícito sobre las propiedades semánticas de los objetos, ", explicaron". Por ejemplo, plátanos y kiwis son muy diferentes en su apariencia (color diferente, forma, textura, etc) pero sin embargo, entendemos correctamente que ambos son frutos. Los modelos de visión por computadora pueden distinguir entre plátanos y kiwis, pero no codifican el conocimiento más abstracto de que ambos son frutos ".
Reconociendo las limitaciones de las redes neuronales para la visión por computadora, los investigadores combinaron el algoritmo de visión AlexNet con una red neuronal que analiza el significado conceptual, Incluir el conocimiento semántico en la ecuación.
"En el modelo combinado, el procesamiento visual se asigna al procesamiento semántico y activa nuestro conocimiento semántico sobre conceptos, ", dijeron los investigadores.
Su nueva técnica fue probada con datos de neuroimagen de 16 voluntarios, a quienes se les había pedido que nombraran imágenes de objetos mientras se les realizaba una resonancia magnética funcional. En comparación con los modelos de visión tradicionales de redes neuronales profundas (DNN), el nuevo método pudo identificar áreas del cerebro asociadas con el procesamiento visual y semántico.
Cómo las diferentes capas del DNN visual (púrpura) y la red de atracción semántica (rojo-amarillo) se mapean en diferentes regiones del cerebro. Crédito:Lorraine Tyler et al. 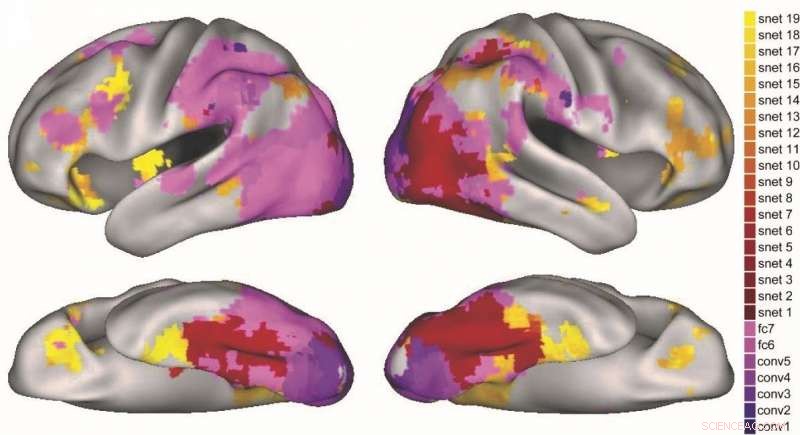
El método que idearon hizo predicciones sobre las etapas de activación semántica en el cerebro que son consistentes con explicaciones anteriores del procesamiento de objetos. donde un procesamiento semántico más grueso da paso a un procesamiento más fino. Los investigadores también encontraron que las diferentes etapas del modelo predijeron la activación en diferentes regiones de la vía de procesamiento de objetos del cerebro.
"Por último, mejores modelos de cómo las personas procesan los objetos visuales de manera significativa pueden tener implicaciones clínicas prácticas; por ejemplo, en la comprensión de condiciones como la demencia semántica, donde las personas pierden el conocimiento del significado de los conceptos de objeto, ", dijeron los investigadores.
El estudio realizado en Cambridge es una importante contribución al campo de las neurociencias, ya que mostró cómo las diferentes regiones del cerebro contribuyen al procesamiento visual y semántico de los objetos.
"Ahora es vital investigar cómo la información de una región puede transformarse en un estado diferente al que vemos en diferentes regiones del cerebro". ", agregaron los investigadores." Para esto, necesitamos entender cómo la conectividad, y la dinámica temporal apoyan estos procesos neuronales transformadores ".
La investigación fue publicada en Informes científicos recientemente.
© 2018 Tech Xplore