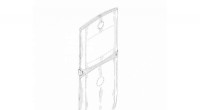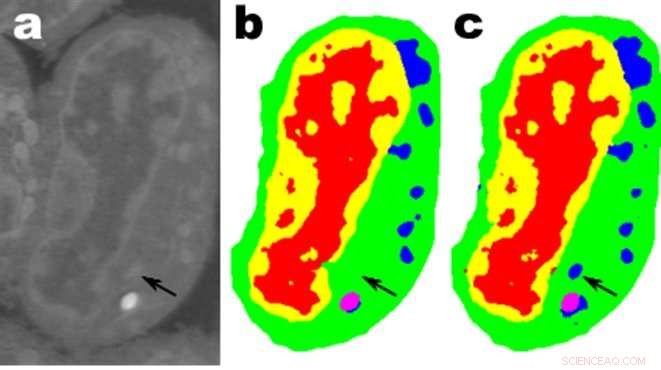
Imágenes de un corte de células linfoblastoides de ratón; una. son los datos sin procesar, b es la segmentación manual correspondiente y c es la salida de una red MS-D con 100 capas. Crédito:Datos de A. Ekman y C. Larabell, Centro Nacional de Tomografía por Rayos X.
Los matemáticos del Laboratorio Nacional Lawrence Berkeley del Departamento de Energía (Berkeley Lab) han desarrollado un nuevo enfoque para el aprendizaje automático dirigido a datos de imágenes experimentales. En lugar de depender de las decenas o cientos de miles de imágenes que utilizan los métodos típicos de aprendizaje automático, este nuevo enfoque "aprende" mucho más rápidamente y requiere muchas menos imágenes.
Daniël Pelt y James Sethian del Centro de Matemáticas Avanzadas para Aplicaciones de Investigación Energética (CAMERA) de Berkeley Lab cambiaron la perspectiva habitual del aprendizaje automático al desarrollar lo que llaman una "Red neuronal de convolución densa de escala mixta (MS-D)" que requiere muchos menos parámetros que los métodos tradicionales, converge rápidamente, y tiene la capacidad de "aprender" de un conjunto de entrenamiento notablemente pequeño. Su enfoque ya se está utilizando para extraer la estructura biológica de las imágenes celulares, y está preparado para proporcionar una nueva herramienta computacional importante para analizar datos en una amplia gama de áreas de investigación.
A medida que las instalaciones experimentales generan imágenes de mayor resolución a velocidades más altas, los científicos pueden tener dificultades para gestionar y analizar los datos resultantes, que a menudo se hace minuciosamente a mano. En 2014, Sethian estableció CAMERA en Berkeley Lab como un centro interdisciplinario para desarrollar y ofrecer nuevas matemáticas fundamentales necesarias para capitalizar las investigaciones experimentales en las instalaciones de los usuarios de la Oficina de Ciencias del DOE. CAMERA es parte de la División de Investigación Computacional del laboratorio.
"En muchas aplicaciones científicas, Se requiere un tremendo trabajo manual para anotar y etiquetar imágenes; puede llevar semanas producir un puñado de imágenes cuidadosamente delineadas, "dijo Sethian, quien también es profesor de matemáticas en la Universidad de California, Berkeley. "Nuestro objetivo era desarrollar una técnica que aprenda de un conjunto de datos muy pequeño".
Los detalles del algoritmo se publicaron el 26 de diciembre de 2017 en un artículo en el procedimientos de la Academia Nacional de Ciencias .
"El avance resultó de darse cuenta de que la reducción y la ampliación habituales que capturan características en varias escalas de imagen podrían reemplazarse por convoluciones matemáticas que manejan múltiples escalas dentro de una sola capa, "dijo Pelt, quien también es miembro del Computational Imaging Group en Centrum Wiskunde &Informatica, el instituto nacional de investigación de matemáticas e informática de los Países Bajos.
Para que el algoritmo sea accesible para un amplio conjunto de investigadores, un equipo de Berkeley dirigido por Olivia Jain y Simon Mo construyó un portal web "Motor de datos de imágenes etiquetadas segmentadas (SlideCAM)" como parte del conjunto de herramientas CAMERA para las instalaciones experimentales del DOE.

Imágenes tomográficas de un mini-compuesto reforzado con fibra, reconstruido utilizando 1024 proyecciones (a) y 120 proyecciones (b). C ª), se muestra la salida de una red MS-D con la imagen (b) como entrada. Una pequeña región indicada por un cuadrado rojo se muestra ampliada en la esquina inferior derecha de cada imagen. Crédito:Daniël Pelt y James Sethian, Laboratorio de Berkeley
Una aplicación prometedora es la comprensión de la estructura interna de las células biológicas y un proyecto en el que el método MS-D de Pelt y Sethian solo necesitaba datos de siete células para determinar la estructura celular.
"En nuestro laboratorio, estamos trabajando para comprender cómo la estructura y morfología celular influye o controla el comportamiento celular. Pasamos innumerables horas segmentando manualmente las células para extraer la estructura, e identificar, por ejemplo, diferencias entre células sanas y enfermas, "dijo Carolyn Larabell, Director del Centro Nacional de Tomografía de Rayos X y Profesor de la Facultad de Medicina de la Universidad de California en San Francisco. "Este nuevo enfoque tiene el potencial de transformar radicalmente nuestra capacidad para comprender las enfermedades, y es una herramienta clave en nuestro nuevo proyecto patrocinado por Chan-Zuckerberg para establecer un Atlas de células humanas, una colaboración global para mapear y caracterizar todas las células de un cuerpo humano sano ".
Obtener más ciencia a partir de menos datos
Las imágenes están por todas partes. Los teléfonos inteligentes y los sensores han producido un tesoro de imágenes, muchos etiquetados con información pertinente que identifica el contenido. Usando esta vasta base de datos de imágenes con referencias cruzadas, Las redes neuronales convolucionales y otros métodos de aprendizaje automático han revolucionado nuestra capacidad para identificar rápidamente imágenes naturales que se parecen a las vistas y catalogadas anteriormente.
Estos métodos "aprenden" ajustando un conjunto asombrosamente grande de parámetros internos ocultos, guiado por millones de imágenes etiquetadas, y requiere una gran cantidad de tiempo de supercomputadora. Pero, ¿y si no tienes tantas imágenes etiquetadas? En muchos campos, tal base de datos es un lujo inalcanzable. Los biólogos registran imágenes de células y delinean minuciosamente los bordes y la estructura a mano:no es inusual que una persona pase semanas creando una sola imagen completamente tridimensional. Los científicos de materiales utilizan la reconstrucción tomográfica para observar el interior de rocas y materiales, y luego arremangarse para etiquetar diferentes regiones, identificando grietas, fracturas y huecos a mano. Los contrastes entre estructuras diferentes pero importantes a menudo son muy pequeños y el "ruido" en los datos puede enmascarar características y confundir lo mejor de los algoritmos (y los humanos).
Estas preciosas imágenes seleccionadas a mano no se acercan lo suficiente a los métodos tradicionales de aprendizaje automático. Para enfrentar este desafío, Los matemáticos de CAMERA atacaron el problema del aprendizaje automático a partir de cantidades muy limitadas de datos. Tratando de hacer "más con menos, "su objetivo era descubrir cómo construir un conjunto eficiente de" operadores "matemáticos que pudieran reducir en gran medida el número de parámetros. Estos operadores matemáticos naturalmente podrían incorporar restricciones clave para ayudar en la identificación, por ejemplo, al incluir requisitos sobre formas y patrones científicamente plausibles.
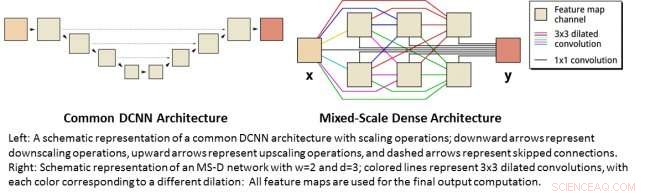
Izquierda:representación esquemática de una arquitectura DCNN común con operaciones de escalado; las flechas hacia abajo representan operaciones de reducción de escala, las flechas hacia arriba representan operaciones de ampliación y las flechas discontinuas representan conexiones omitidas. Derecha:Representación esquemática de una red MS-D con w =2 yd =3; las líneas de color representan convoluciones dilatadas de 3x3, con cada color correspondiente a una dilatación diferente:Todos los mapas de características se utilizan para el cálculo de salida final. Crédito:Daniël Pelt y James Sethian, Laboratorio de Berkeley
Redes neuronales de convolución densa de escala mixta
Muchas aplicaciones del aprendizaje automático para problemas de imágenes utilizan redes neuronales convolucionales profundas (DCNN), en el que la imagen de entrada y las imágenes intermedias están convolucionadas en un gran número de capas sucesivas, permitiendo que la red aprenda características altamente no lineales. Para lograr resultados precisos para problemas difíciles de procesamiento de imágenes, Los DCNN suelen depender de combinaciones de operaciones y conexiones adicionales que incluyen, por ejemplo, operaciones de reducción y ampliación para capturar características en varias escalas de imagen. Para entrenar redes más profundas y poderosas, A menudo se requieren tipos de capas y conexiones adicionales. Finalmente, Los DCNN suelen utilizar una gran cantidad de imágenes intermedias y parámetros entrenables, a menudo más de 100 millones, para lograr resultados para problemas difíciles.
En lugar de, la nueva arquitectura de red de "densidad de escala mixta" evita muchas de estas complicaciones y calcula convoluciones dilatadas como sustituto de las operaciones de escalado para capturar características en varios rangos espaciales, empleando múltiples escalas dentro de una sola capa, y conectando densamente todas las imágenes intermedias. El nuevo algoritmo logra resultados precisos con pocas imágenes y parámetros intermedios, eliminando tanto la necesidad de ajustar hiperparámetros como capas o conexiones adicionales para permitir el entrenamiento.
Obtener ciencia de alta resolución a partir de datos de baja resolución
Un desafío diferente es producir imágenes de alta resolución a partir de una entrada de baja resolución. Como cualquiera que haya intentado agrandar una foto pequeña y descubrió que solo empeora a medida que crece, esto suena casi imposible. Pero un pequeño conjunto de imágenes de entrenamiento procesadas con una red densa de escala mixta puede proporcionar un avance real. Como ejemplo, imagínese tratando de eliminar el ruido de las reconstrucciones tomográficas de un material de mini-composite reforzado con fibra. En un experimento descrito en el documento, las imágenes fueron reconstruidas usando 1, 024 adquirió proyecciones de rayos X para obtener imágenes con cantidades relativamente bajas de ruido. Luego se obtuvieron imágenes ruidosas del mismo objeto mediante la reconstrucción utilizando 128 proyecciones. Las entradas de entrenamiento eran imágenes ruidosas, con las imágenes silenciosas correspondientes utilizadas como salida de destino durante el entrenamiento. Luego, la red capacitada pudo tomar datos de entrada ruidosos de manera efectiva y reconstruir imágenes de mayor resolución.
Nuevas aplicaciones
Pelt y Sethian están adoptando su enfoque en una serie de nuevas áreas, como el análisis rápido en tiempo real de imágenes provenientes de fuentes de luz de sincrotrón y problemas de reconstrucción en la reconstrucción biológica, como el mapeo de células y cerebro.
"Estos nuevos enfoques son realmente emocionantes, ya que permitirán la aplicación del aprendizaje automático a una variedad mucho mayor de problemas de imágenes de lo que es posible actualmente, ", Dijo Pelt." Al reducir la cantidad de imágenes de entrenamiento requeridas y aumentar el tamaño de las imágenes que se pueden procesar, la nueva arquitectura se puede utilizar para responder preguntas importantes en muchos campos de investigación ".