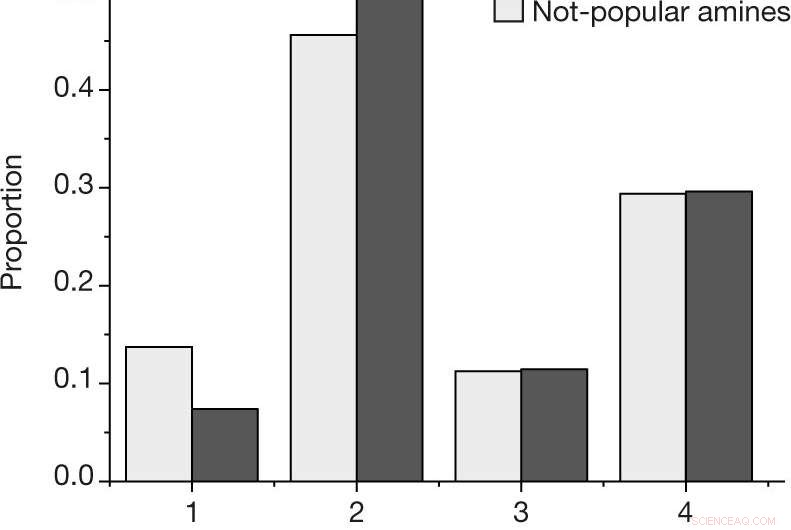
a, La proporción por resultado de cada reacción, utilizando la escala de resultados descrita en Métodos, para las aminas populares y no populares en el conjunto de datos seleccionados por humanos. B, Probabilidad estimada de observar al menos una reacción exitosa (resultado 4) o fracaso (resultados 1, 2 y 3) para una amina determinada, para las N =27 aminas populares y N =28 no populares entre el conjunto de datos seleccionados por humanos. Los valores centrales indican la proporción observada de resultados. Las barras de error indican una estimación de arranque de la desviación estándar. Crédito: Naturaleza (2019). DOI:10.1038 / s41586-019-1540-5
Un equipo de científicos de materiales del Haverford College ha demostrado cómo el sesgo humano en los datos puede afectar los resultados de los algoritmos de aprendizaje automático que se utilizan para predecir nuevos reactivos que se utilizarán en la fabricación de los productos deseados. En su artículo publicado en la revista Naturaleza , el grupo describe probar un algoritmo de aprendizaje automático con diferentes tipos de conjuntos de datos y lo que encontraron.
Una de las aplicaciones más conocidas de los algoritmos de aprendizaje automático es el reconocimiento facial. Pero existen posibles problemas con tales algoritmos. Uno de estos problemas ocurre cuando un algoritmo facial destinado a buscar a un individuo entre muchas caras se ha entrenado utilizando personas de una sola raza. En este nuevo esfuerzo, los investigadores se preguntaron si el sesgo, involuntariamente o de otra manera, podría estar apareciendo en los resultados del algoritmo de aprendizaje automático utilizados en aplicaciones químicas diseñadas para buscar nuevos productos.
Dichos algoritmos utilizan datos que describen los ingredientes de las reacciones que dan como resultado la creación de un nuevo producto. Pero los datos con los que se entrena el sistema podrían tener un gran impacto en los resultados. Los investigadores señalan que actualmente, Dichos datos se obtienen de los esfuerzos de investigación publicados, lo que significa que normalmente son generados por humanos. Señalan que los datos de tales esfuerzos podrían haber sido generados por los propios investigadores, o por otros investigadores que trabajan en esfuerzos separados. Los datos incluso podrían provenir de una sola persona que simplemente se relacione de memoria, o por sugerencia de un profesor, o un estudiante de posgrado con una idea brillante. La cuestión es, los datos podrían estar sesgados en términos de los antecedentes del recurso.
En este nuevo esfuerzo, los investigadores querían saber si tales sesgos podrían tener un impacto en los resultados de los algoritmos de aprendizaje automático utilizados para aplicaciones químicas. Descubrir, observaron un conjunto específico de materiales llamados boratos de vanadio con plantilla de amina. Cuando se sintetizan con éxito, Se forman cristales, una manera fácil de determinar si una reacción fue exitosa.
El experimento consistió en entrenar un algoritmo de aprendizaje automático con datos que rodean la síntesis de boratos de vanadio, y luego programar el sistema para crear el suyo propio. Algunos de los datos recopilados por los investigadores fueron generados por humanos, y parte de ella se recopiló al azar. Informan que el algoritmo entrenado con datos aleatorios funcionó mejor para encontrar formas de sintetizar los boratos de vanadio que cuando utilizó datos generados a partir de humanos. Afirman que esto muestra un claro sesgo en los datos que fueron creados por humanos.
© 2019 Science X Network