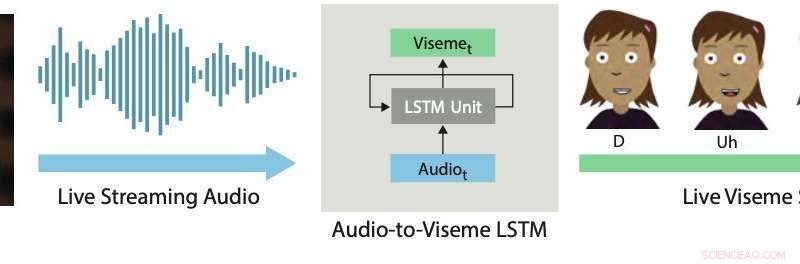
Sincronización de labios en tiempo real. Nuestro enfoque de aprendizaje profundo utiliza un LSTM para convertir audio de transmisión en vivo en visemas discretos para personajes 2D. Crédito:Aneja &Li.
La animación 2-D en vivo es una forma de comunicación bastante nueva y poderosa que permite a los artistas humanos controlar a los personajes de dibujos animados en tiempo real mientras interactúan e improvisan con otros actores o miembros de una audiencia. Ejemplos recientes incluyen a Stephen Colbert entrevistando a invitados de dibujos animados en El show tardío , Homer respondiendo preguntas telefónicas en vivo de los espectadores durante un segmento de Los Simpsons , Archer hablando con una audiencia en vivo en ComicCon, y las estrellas de Disney Star contra las fuerzas del mal y Mi pequeño Pony organizar sesiones de chat en vivo con fans a través de YouTube o Facebook Live.
La producción de animaciones 2D en vivo realistas y efectivas requiere el uso de sistemas interactivos que pueden transformar automáticamente las actuaciones humanas en animaciones en tiempo real. Un aspecto clave de estos sistemas es lograr una buena sincronización de labios, lo que esencialmente significa que las bocas de los personajes animados se mueven apropiadamente al hablar, imitando los movimientos observados en la boca de los artistas intérpretes o ejecutantes.
Una buena sincronización de labios puede hacer que la animación 2D en vivo sea más convincente y poderosa. permitiendo que los personajes animados encarnen la interpretación de manera más realista. En cambio, La sincronización de labios deficiente normalmente rompe la ilusión de los personajes como participantes en vivo en una actuación o diálogo.
En un artículo prepublicado recientemente en arXiv, dos investigadores de Adobe Research y la Universidad de Washington introdujeron un sistema interactivo basado en aprendizaje profundo que genera automáticamente sincronización de labios en vivo para personajes animados en 2-D en capas. El sistema que desarrollaron utiliza un modelo de memoria a corto plazo a largo plazo (LSTM), una arquitectura de red neuronal recurrente (RNN) que a menudo se aplica a tareas que implican clasificar o procesar datos, además de hacer predicciones.
"Dado que el habla es el componente dominante de casi todas las animaciones en vivo, Creemos que el problema más crítico a abordar en este dominio es la sincronización de labios en vivo, que implica transformar el discurso de un actor en los correspondientes movimientos de la boca (es decir, secuencia viseme) en el personaje animado. En este trabajo, nos enfocamos en crear sincronización de labios de alta calidad para animaciones 2-D en vivo, "Wilmot Li y Deepali Aneja, los dos investigadores que llevaron a cabo la investigación, dijo a TechXplore por correo electrónico.
Li es un científico principal de Adobe Research con un Ph.D. en ciencias de la computación que ha estado llevando a cabo una extensa investigación centrada en temas en la intersección de los gráficos por computadora y la interacción persona-computadora. Aneja, por otra parte, actualmente está completando un doctorado. en informática en la Universidad de Washington, donde forma parte del Laboratorio de Gráficos e Imágenes.
El sistema desarrollado por Li y Aneja utiliza un modelo LSTM simple para convertir la entrada de audio de transmisión en una secuencia de visema correspondiente a 24 cuadros por segundo, con menos de 200 milisegundos de latencia. En otras palabras, su sistema permite que los labios de un personaje animado se muevan de manera similar a los de un usuario humano que habla en tiempo real, con menos de 200 milisegundos de retraso entre la voz y el movimiento de los labios.
"En este trabajo, realizamos dos contribuciones:identificar la representación de funciones y la configuración de red adecuadas para lograr resultados de vanguardia para la sincronización de labios en vivo en 2D y diseñar un nuevo método de aumento para recopilar datos de entrenamiento para el modelo, "Li y Aneja explicaron.
"Para la sincronización de labios de autoría manual, los animadores profesionales toman decisiones estilísticas sobre la elección específica de visemas y el momento y el número de transiciones. Como resultado, Es poco probable que el entrenamiento de un solo modelo de `` propósito general '' sea suficiente para la mayoría de las aplicaciones, "Dijeron Li y Aneja. Además, Obtener datos de sincronización de labios etiquetados para entrenar modelos de aprendizaje profundo puede ser costoso y llevar mucho tiempo. Los animadores profesionales pueden dedicar de cinco a siete horas de trabajo por minuto de discurso a las secuencias de visemas de autoría manual. Consciente de estas limitaciones, Li y Aneja desarrollaron un método que puede generar datos de entrenamiento de forma más rápida y eficaz.
Para entrenar su modelo LSTM de manera más efectiva, Li y Aneja introdujeron una nueva técnica que aumenta los datos de entrenamiento creados a mano mediante la deformación del tiempo de audio. Este procedimiento de aumento de datos logró una buena sincronización de labios incluso cuando entrenaba su modelo en un pequeño conjunto de datos etiquetado.
Para evaluar la efectividad de su sistema interactivo para producir sincronización de labios en tiempo real, los investigadores pidieron a los espectadores humanos que calificaran la calidad de las animaciones en vivo impulsadas por su modelo con las producidas con herramientas comerciales de animación 2-D. Descubrieron que la mayoría de los espectadores preferían la sincronización de labios generada por su enfoque sobre la producida por otras técnicas.
"También investigamos la compensación entre la calidad de la sincronización de labios y la cantidad de datos de entrenamiento, y descubrimos que nuestro método de aumento de datos mejora significativamente el resultado del modelo, "Li y Aneja dijeron." En general, podemos producir resultados razonables con solo 15 minutos de datos de sincronización de labios creados a mano ".
Curiosamente, los investigadores descubrieron que su modelo LSTM puede adquirir diferentes estilos de sincronización de labios en función de los datos con los que está entrenado, al mismo tiempo que se generaliza bien en una amplia gama de hablantes. Impresionado por los alentadores resultados obtenidos por el modelo, Adobe decidió integrar una versión dentro de su software Adobe Character Animator, lanzado en el otoño de 2018.
"Preciso, La sincronización de labios de baja latencia es importante para casi todas las configuraciones de animación en vivo, y nuestros experimentos de juicio humano muestran que nuestra técnica mejora los motores de sincronización de labios 2-D de última generación existentes, la mayoría de los cuales requieren procesamiento fuera de línea, "Dijeron Li y Aneja. Así, los investigadores creen que su trabajo tiene implicaciones prácticas inmediatas para la producción de animación 2-D en vivo y no en vivo. Los investigadores no están al tanto de trabajos previos de sincronización de labios en 2-D con comparaciones igualmente completas con herramientas comerciales.
En su estudio reciente, Li y Aneja pudieron abordar algunos de los desafíos técnicos clave asociados con el desarrollo de técnicas para la animación 2-D en vivo. Primero, demostraron un nuevo método para codificar reglas artísticas para la sincronización de labios en 2-D utilizando RNN, que podría mejorarse aún más en el futuro.
Los investigadores creen que hay muchas más oportunidades para aplicar técnicas modernas de aprendizaje automático para mejorar los flujos de trabajo de animación 2-D. "Hasta ahora, un desafío ha sido la falta de datos de capacitación, que es caro de recolectar. Sin embargo, como mostramos en este trabajo, Puede haber formas de aprovechar los datos estructurados y los algoritmos de edición automática (por ejemplo, deformación dinámica del tiempo) para maximizar la utilidad de los datos de animación hechos a mano, "Dijeron Li y Aneja.
Aunque la estrategia de aumento de datos propuesta por los investigadores puede reducir significativamente los requisitos de datos de entrenamiento para modelos diseñados para producir sincronización de labios en tiempo real, animar a mano suficiente contenido de sincronización de labios para entrenar nuevos modelos todavía requiere un trabajo y un esfuerzo considerables. Según Li y Aneja, sin embargo, reentrenar un modelo completo desde cero para cada nuevo estilo de sincronización de labios que encuentre puede ser innecesario.
Los investigadores están interesados en explorar estrategias de ajuste que podrían permitir a los animadores adaptar el modelo a diferentes estilos con una cantidad mucho menor de participación del usuario. "Una idea relacionada es aprender directamente un modelo de sincronización de labios que incluye explícitamente parámetros estilísticos ajustables. Si bien esto puede requerir un conjunto de datos de entrenamiento mucho más grande, el beneficio potencial es un modelo lo suficientemente general como para admitir una variedad de estilos de sincronización de labios sin entrenamiento adicional, ", dijeron los investigadores.
Curiosamente, en sus experimentos, los investigadores observaron que la simple pérdida de entropía cruzada que utilizaron para entrenar su modelo no reflejaba con precisión las diferencias de percepción más relevantes entre las secuencias de sincronización de labios. Más específicamente, encontraron que ciertas discrepancias (por ejemplo, omitir una transición o reemplazar un visema de boca cerrada con un visema de boca abierta) son mucho más obvios que otros. "Creemos que diseñar o aprender una pérdida basada en la percepción en investigaciones futuras puede conducir a mejoras en el modelo resultante, "Dijeron Li y Aneja.
© 2019 Science X Network