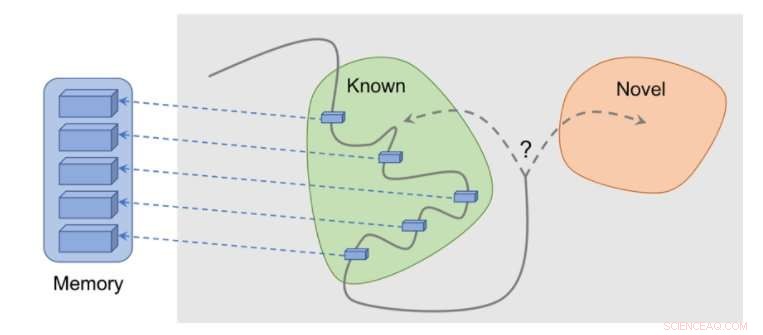
Cómo funciona el método:las observaciones se agregan a la memoria, La recompensa se calcula en función de qué tan lejos está nuestra observación actual de la observación más similar en la memoria. El agente recibe más recompensa por ver observaciones que aún no están representadas en la memoria. Crédito:Savinov et al.
Varias tareas del mundo real tienen recompensas escasas y esto plantea desafíos para el desarrollo de algoritmos de aprendizaje por refuerzo (RL). Una solución a este problema es permitir que un agente se cree de forma autónoma una recompensa, haciendo que las recompensas sean más densas y adecuadas para el aprendizaje.
Por ejemplo, inspirado en el curioso comportamiento con el que los animales exploran su entorno, La observación de algo nuevo por parte de un algoritmo RL podría ser recompensada con una bonificación. Este bono, resumido con la recompensa de la tarea real, permitiría que los algoritmos de RL aprendan de una recompensa combinada.
Investigadores de DeepMind, Google Brain y ETH Zurich han ideado recientemente un nuevo método de curiosidad que utiliza la memoria episódica para formar este bono de novedad. Esta bonificación se determina comparando las observaciones actuales y las observaciones almacenadas en la memoria.
"El objetivo principal de nuestro trabajo fue investigar nuevas formas basadas en la memoria de imbuir a los agentes de aprendizaje por refuerzo (RL) con 'curiosidad, 'con lo que nos referimos a un impulso para explorar el medio ambiente incluso en ausencia total de recompensas, "Tim Lillicrap de DeepMind y Nikolay Savinov de Google Brain le dijeron a TechXplore en un correo electrónico." La comunidad de investigadores ha abordado la curiosidad de diversas formas, pero sentimos que varias ideas podrían beneficiarse de una mayor exploración ".
Las ideas clave exploradas en este artículo reciente se basan en un estudio anterior realizado por Savinov, que propuso una nueva arquitectura de memoria inspirada en la navegación de los mamíferos. Esta arquitectura permite a los agentes repetir una ruta a través de un entorno utilizando solo un recorrido visual. El nuevo método desarrollado por los investigadores lleva esto un paso más allá, tratando de lograr una buena exploración impulsada por la curiosidad.
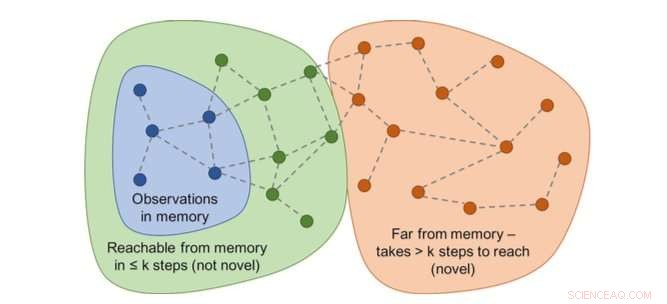
El gráfico de accesibilidad determinaría la novedad. En la práctica, este gráfico no está disponible, por lo que un aproximador de redes neuronales está capacitado para estimar un número de pasos entre observaciones. Crédito:Savinov et al.
"Mientras actúa, el agente almacena instancias de representaciones de observación en su memoria episódica, "Lillicrap y Savinov dijeron." Para determinar si la observación actual es nueva o no, se compara con los de la memoria. Si no se encuentra nada similar, la observación actual se considera nueva y el agente es recompensado, de lo contrario, obtiene una recompensa negativa. Esto anima al agente a explorar un territorio desconocido, similar a ser curioso ".
Los investigadores encontraron que comparar pares de observaciones podría ser complicado, ya que, en última instancia, la comprobación de una coincidencia exacta no tiene sentido en entornos realistas. Esto se debe a que en situaciones del mundo real, un agente rara vez observa lo mismo dos veces.
"En lugar de, entrenamos una red neuronal para predecir si el agente puede alcanzar la observación actual de aquellos en la memoria tomando menos acciones que un umbral fijo; decir, cinco acciones, "Lillicrap y Savinov explicaron." Las observaciones dentro de esas cinco acciones se consideran similares, mientras que aquellos que requieren más acciones para hacer una transición se consideran diferentes ".
Lillicrap, Savinov y sus colegas probaron su enfoque en VizDoom y DMLab, dos entornos 3D visualmente ricos. En VizDoom, el agente aprendió a navegar con éxito hacia una meta distante al menos dos veces más rápido que el método de curiosidad ICM de última generación. En DMLab, el algoritmo se generalizó bien a nuevo, niveles del juego generados por procedimientos, alcanzando su objetivo deseado al menos dos veces más frecuentemente que ICM en laberintos de prueba con recompensas muy escasas.

El método basado en sorpresas (ICM) consiste en marcar constantemente las paredes con un dispositivo de ciencia ficción similar a un láser en lugar de explorar el laberinto. Este comportamiento es similar al cambio de canal descrito anteriormente:aunque el resultado del etiquetado es teóricamente predecible, no es fácil y aparentemente requiere un conocimiento profundo de la física que no es fácil de adquirir para un agente general. Crédito:Savinov et al.
"Notamos un inconveniente interesante en uno de los métodos más populares para infundir curiosidad a los agentes, "Lillicrap y Savinov dijeron." Descubrimos que este método, basado en la sorpresa que es calculada por un modelo que cambia lentamente que intenta predecir lo que sucederá a continuación, puede resultar en una respuesta de gratificación instantánea del agente:en lugar de resolver la tarea en cuestión, explotará acciones que conduzcan a consecuencias impredecibles para obtener una recompensa inmediata ".
Esta peculiar ocurrencia, también conocidos como problemas de "teleadicto", implica que un agente encuentre formas de gratificarse instantáneamente mediante la explotación de acciones que conducen a consecuencias impredecibles. Por ejemplo, cuando se le da un control remoto de TV, el agente no puede hacer otra cosa que cambiar de canal, incluso si su tarea original era completamente diferente, como buscar una meta en un laberinto.
"Esta deficiencia se puede aliviar utilizando la memoria episódica junto con una medida razonable de similitud de observación, cual es nuestro aporte, "Lillicrap y Savinov dijeron." Esto abre un camino a una exploración más inteligente ".

Nuestro método muestra una exploración razonable. Crédito:Savinov et al.
El nuevo método de curiosidad ideado por Lillicrap, Savinov, y sus colegas podrían ayudar a replicar habilidades similares a la curiosidad en algoritmos RL, permitiéndoles crear recompensas de forma autónoma para sí mismos. En el futuro, A los investigadores les gustaría usar la memoria episódica no solo para otorgar recompensas, sino también para planificar acciones.
"Por ejemplo, ¿Se puede utilizar el contenido recuperado de la memoria para pensar a dónde ir? ", dijeron Lillicrap y Savinov." Este es actualmente un gran desafío científico:si se resuelve, los agentes podrían adaptar rápidamente las estrategias de exploración a nuevos entornos, permitiendo que el aprendizaje ocurra a un ritmo mucho más rápido ".
© 2018 Tech Xplore