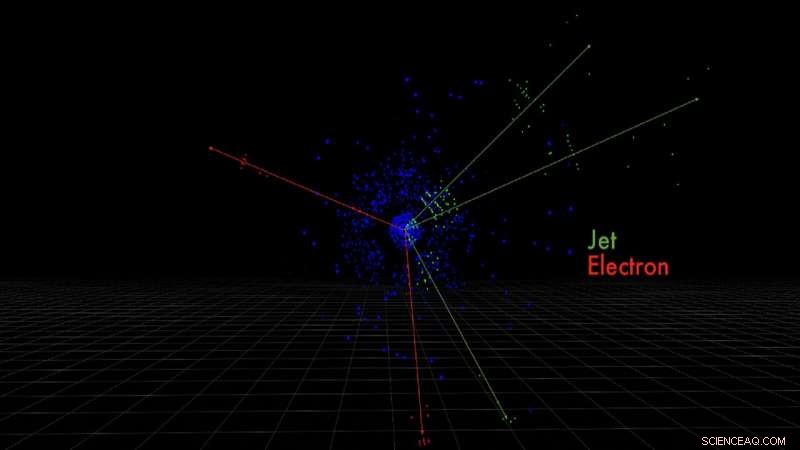
Estos son los píxeles detectores de electrones y chorros de quark producidos por una colisión de protones simulada, medido por el detector ATLAS. Crédito:Taylor Childers
Si bien la física y la cosmología de altas energías parecen mundos separados en términos de escala pura, Los físicos y cosmólogos de Argonne están utilizando métodos similares de aprendizaje automático para abordar problemas de clasificación tanto para partículas subatómicas como para galaxias.
La física de altas energías y la cosmología parecen mundos separados en términos de escala pura, pero los componentes invisibles que componen el campo de uno informan la composición y dinámica del otro:estrellas en colapso, nebulosas nacientes de estrellas y, quizás, materia oscura.
Por décadas, las técnicas mediante las cuales los investigadores de ambos campos estudiaron sus dominios parecían casi incompatibles, así como. La física de altas energías se basó en aceleradores y detectores para obtener información sobre las interacciones energéticas de las partículas, mientras los cosmólogos miraban a través de todo tipo de telescopios para desvelar los secretos del universo.
Si bien ninguno ha renunciado al equipo fundamental de su campo en particular, Los físicos y cosmólogos del Laboratorio Nacional Argonne del Departamento de Energía de EE. UU. (DOE) están atacando problemas complejos de múltiples escalas utilizando diversas formas de una técnica de inteligencia artificial llamada aprendizaje automático.
Ya utilizado en numerosos campos, El aprendizaje automático puede ayudar a identificar patrones ocultos aprendiendo de los datos de entrada y mejorando progresivamente las predicciones sobre nuevos datos. Puede aplicarse a tareas de clasificación visual o en la reproducción rápida de cálculos complicados y computacionalmente costosos.
Con el potencial de transformar radicalmente la forma en que se conduce la ciencia, Estas técnicas de IA nos ayudarán a comprender mejor la distribución de las galaxias en todo el universo o visualizar mejor la formación de nuevas partículas de las que podríamos inferir nueva física.
"Largo de las décadas, hemos desarrollado algoritmos tradicionales que reconstruyen las firmas de las diversas partículas que nos interesan, "dijo Taylor Childers, un físico de partículas y un científico informático con Argonne Leadership Computing Facility (ALCF), una instalación para usuarios de la Oficina de Ciencias del DOE.
"Ha llevado mucho tiempo desarrollarlos y son muy precisos, ", agregó." Pero al mismo tiempo, Sería interesante saber si las técnicas de clasificación de imágenes del aprendizaje automático que han sido utilizadas con éxito por Google y Facebook pueden simplificar o acortar el desarrollo de algoritmos que identifican firmas de partículas en nuestros detectores 3-D ".
Childers trabaja con físicos de alta energía de Argonne, todos los cuales son miembros de la colaboración experimental ATLAS en el Gran Colisionador de Hadrones (LHC) del CERN, el colisionador de partículas más grande y poderoso del mundo. Buscando resolver una amplia gama de problemas de física, el detector ATLAS tiene ocho pisos de altura y 150 pies de largo en un punto alrededor del anillo colisionador de circunferencia de 17 millas del LHC, donde mide los productos de los protones que chocan a velocidades cercanas a la velocidad de la luz.
Según el sitio web de ATLAS, "más de mil millones de interacciones de partículas tienen lugar en el detector ATLAS cada segundo, una velocidad de datos equivalente a 20 conversaciones telefónicas simultáneas mantenidas por cada persona en la tierra ".
Si bien solo un pequeño porcentaje de estas colisiones se considera digno de estudio, aproximadamente un millón por segundo, todavía proporciona una montaña de datos para que los científicos investiguen.
Estas colisiones de partículas de alta velocidad crean nuevas partículas a su paso, como electrones o lluvias de quarks, cada uno dejando una firma única en el detector. Son estas firmas las que a Childers le gustaría identificar a través del aprendizaje automático.
Entre los desafíos se encuentra capturar esas firmas de energía como imágenes en un complejo espacio tridimensional. Una fotografía, por ejemplo, es esencialmente una representación 2-D de datos 3-D con posiciones verticales y horizontales. Los datos de píxeles, los colores de la imagen, están orientados espacialmente y tienen información espacial codificada en ellos, por ejemplo, los ojos de un gato están al lado de la nariz, y las orejas están arriba a la izquierda y a la derecha.
"Así que su orientación espacial es importante. Lo mismo ocurre con las imágenes que tomamos en el LHC. Cuando una partícula atraviesa nuestro detector, deja una firma de energía en patrones espaciales que son específicos de las diferentes partículas, "explicó Childers.
Agregue a eso la cantidad de datos codificados no solo en las firmas, pero el espacio tridimensional a su alrededor. Donde los ejemplos tradicionales de aprendizaje automático para el reconocimiento de imágenes:esos gatos, de nuevo:trata con cientos de miles de píxeles, Las imágenes de ATLAS contienen cientos de millones de píxeles detectores.
Entonces la idea él dijo, es tratar las imágenes del detector como imágenes tradicionales. Mediante una técnica de aprendizaje automático llamada redes neuronales convolucionales, que aprenden cómo se relacionan espacialmente los datos, pueden extraer el espacio 3-D para identificar más fácilmente las características de partículas específicas.

La imagen muestra un anillo de Einstein (centro a la derecha) formado por lentes gravitacionales de una galaxia en formación de estrellas (azul) por una galaxia roja luminosa masiva (naranja). Este sistema fue descubierto por primera vez por Sloan Digital Sky Survey en 2007; las imágenes son del telescopio espacial Hubble. Crédito:NASA
Childers espera que estos algoritmos de aprendizaje automático eventualmente reemplacen a los algoritmos tradicionales hechos a mano, reduciendo en gran medida el tiempo que lleva procesar cantidades similares de datos, así como mejorando la precisión de los resultados medidos.
"También podemos reemplazar el desarrollo de una década necesario para los nuevos detectores y reducirlo con nuevos modelos de capacitación para futuros detectores, " él dijo.
Un espacio mas grande
Los cosmólogos de Argonne están utilizando métodos similares de aprendizaje automático para abordar problemas de clasificación, pero a una escala mucho mayor.
"El problema con la cosmología es que los objetos que estamos mirando son complicados y borrosos, "dijo Salman Habib, Director de División de la División de Ciencias Computacionales de Argonne y Director Adjunto Interino de su división de Física de Altas Energías. "Así que describir los datos de una manera más simple se vuelve muy difícil".
Él y sus colegas están aprovechando las supercomputadoras de Argonne y otros laboratorios nacionales del DOE para reconstruir los detalles del universo, galaxia por galaxia. Están creando catálogos de galaxias simuladas altamente detallados que se pueden usar para comparar datos reales tomados de telescopios de levantamiento. como el gran telescopio de exploración sinóptica, una asociación entre el DOE y la National Science Foundation.
Pero para que estos activos sean valiosos para los investigadores, deben estar lo más cerca posible de la realidad.
Algoritmos de aprendizaje automático, Habib dijo:Son muy buenos para seleccionar características que pueden caracterizarse fácilmente por la geometría, como esos gatos. Todavía, similar a la advertencia en los espejos de los vehículos, los objetos en los cielos no siempre son lo que parecen.
Tomemos el fenómeno de las lentes gravitacionales fuertes; la distorsión de una fuente de luz de fondo, una galaxia o un cúmulo de galaxias, por una masa intermedia. La desviación de las trayectorias de los rayos de luz de la fuente debido a la gravedad conduce a una distorsión de la forma de la fuente de fondo, posición y orientación; esta distorsión proporciona información sobre la distribución masiva del objeto interviniente. La situación de observación real no es tan sencilla, sin embargo.
Una mancha completamente redonda con lentes, por ejemplo, puede parecer estirado en una dirección u otra, mientras una ronda, El objeto sin lente en forma de disco puede parecer elíptico si se ve parcialmente de borde.
"Entonces, ¿cómo saber si el objeto que estás mirando no es un objeto redondo que se ha girado, "¿O uno que ha sido enfocado?", preguntó Habib. "Estos son los tipos de cosas complicadas que el aprendizaje automático tiene que poder resolver".
Para hacer esto, los investigadores crean una muestra de entrenamiento de millones de objetos de apariencia realista, la mitad de los cuales tienen lentes. Luego, los algoritmos de aprendizaje automático se encargan de tratar de aprender las diferencias entre los objetos con lente y sin lente. Los resultados se verifican con un conjunto conocido de objetos sin lentes y con lentes sintéticos.
Pero los resultados solo cuentan la mitad de la historia:qué tan bien funcionan los algoritmos en los datos de prueba. Para avanzar aún más en su precisión para datos reales, los investigadores mezclan un porcentaje de datos sintéticos con datos previamente observados y ejecutan los algoritmos, de nuevo, comparar qué tan bien eligieron los objetos con lentes en la muestra de entrenamiento con los datos de combinación.
"En el final, puede encontrar que funciona razonablemente bien, pero tal vez no tan bien como quisieras, "explicó Habib." Podrías decir 'Está bien, esta información por sí sola no será suficiente, Necesito recolectar más '. Es un proceso bastante largo y complejo ".
Dos objetivos principales de la cosmología moderna, él dijo, deben comprender por qué se acelera la expansión del universo y cuál es la naturaleza de la materia oscura. La materia oscura es aproximadamente cinco veces más abundante que la materia normal, pero su origen último sigue siendo un misterio. Para acercarse remotamente a una respuesta, la ciencia debe ser muy deliberada, muy preciso.
"En la etapa actual, No creo que podamos resolver todos nuestros problemas con las aplicaciones de aprendizaje automático, "admitió Habib." Pero yo diría que el aprendizaje automático será muy importante para todos los aspectos de la cosmología de precisión en el futuro cercano ".
A medida que se desarrollan y perfeccionan las técnicas de aprendizaje automático, su utilidad tanto para la física de altas energías como para la cosmología seguramente crecerá exponencialmente, proporcionando la esperanza de nuevos descubrimientos o nuevas interpretaciones que alteren nuestra comprensión del mundo en múltiples escalas.