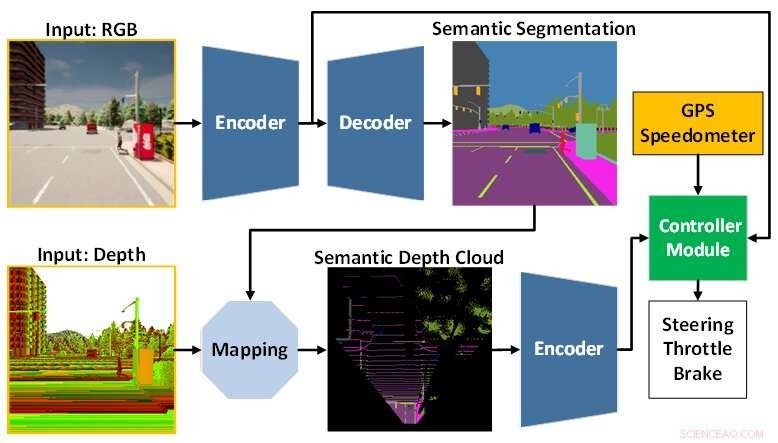
La arquitectura del modelo de IA se compone del módulo de percepción (azul) y el módulo del controlador (verde). El módulo de percepción se encarga de percibir el entorno a partir de los datos de observación proporcionados por una cámara RGBD. Mientras tanto, el módulo del controlador es responsable de decodificar la información extraída para estimar el grado de dirección, aceleración y frenado. Crédito:Universidad Tecnológica de Toyohashi
Un equipo de investigación formado por Oskar Natan, Ph.D. El estudiante y su supervisor, el profesor Jun Miura, afiliado al Laboratorio de Sistemas Inteligentes Activos (AISL), Departamento de Ingeniería Informática, Universidad Tecnológica de Toyohashi, ha desarrollado un modelo de IA que puede manejar la percepción y el control simultáneamente para una conducción autónoma. vehículo.
El modelo de IA percibe el entorno completando varias tareas de visión mientras conduce el vehículo siguiendo una secuencia de puntos de ruta. Además, el modelo de IA puede conducir el vehículo de manera segura en diversas condiciones ambientales en varios escenarios. Evaluado en tareas de navegación punto a punto, el modelo de IA logra la mejor manejabilidad de ciertos modelos recientes en un entorno de simulación estándar.
La conducción autónoma es un sistema complejo que consta de varios subsistemas que manejan múltiples tareas de percepción y control. Sin embargo, la implementación de múltiples módulos para tareas específicas es costosa e ineficiente, ya que todavía se necesitan numerosas configuraciones para formar un sistema modular integrado.
Además, el proceso de integración puede conducir a la pérdida de información ya que muchos parámetros se ajustan manualmente. Con una rápida investigación de aprendizaje profundo, este problema se puede abordar entrenando un solo modelo de IA con formas integrales y multitarea. Por lo tanto, el modelo puede proporcionar controles de navegación basados únicamente en las observaciones proporcionadas por un conjunto de sensores. Como ya no es necesaria la configuración manual, el modelo puede gestionar la información por sí mismo.
El desafío que queda para un modelo de extremo a extremo es cómo extraer información útil para que el controlador pueda estimar los controles de navegación correctamente. Esto se puede resolver proporcionando una gran cantidad de datos al módulo de percepción para percibir mejor el entorno circundante. Además, se puede utilizar una técnica de fusión de sensores para mejorar el rendimiento, ya que fusiona diferentes sensores para capturar diversos aspectos de los datos.
Sin embargo, es inevitable una gran carga de cálculo, ya que se necesita un modelo más grande para procesar más datos. Además, es necesaria una técnica de preprocesamiento de datos, ya que los diferentes sensores a menudo vienen con diferentes modalidades de datos. Además, el aprendizaje desequilibrado durante el proceso de entrenamiento podría ser otro problema, ya que el modelo realiza tareas de percepción y control simultáneamente.

Algunos registros de conducción realizados por el modelo de IA. Columnas (de izquierda a derecha):imagen en color, imagen de profundidad, resultado de segmentación semántica, mapa de vista de pájaro (BEV), comando de control. El clima y la hora para cada escena son los siguientes:(1) mediodía despejado, (2) atardecer nublado, (3) mediodía lluvioso, (4) atardecer con lluvia fuerte, (5) atardecer húmedo. Crédito:Universidad Tecnológica de Toyohashi
Para responder a esos desafíos, el equipo propone un modelo de IA entrenado con formas integrales y multitarea. El modelo está compuesto por dos módulos principales, a saber, los módulos de percepción y de control. La fase de percepción comienza con el procesamiento de imágenes RGB y mapas de profundidad proporcionados por una sola cámara RGBD.
Luego, la información extraída del módulo de percepción junto con la medición de la velocidad del vehículo y las coordenadas del punto de ruta son decodificadas por el módulo controlador para estimar los controles de navegación. Para garantizar que todas las tareas se puedan realizar por igual, el equipo emplea un algoritmo llamado normalización de gradiente modificado (MGN) para equilibrar la señal de aprendizaje durante el proceso de entrenamiento.
El equipo considera el aprendizaje por imitación, ya que permite que el modelo aprenda de un conjunto de datos a gran escala para que coincida con un estándar casi humano. Además, el equipo diseñó el modelo para usar una cantidad menor de parámetros que otros para reducir la carga computacional y acelerar la inferencia en un dispositivo con recursos limitados.
Basado en el resultado experimental en un simulador de conducción autónomo estándar, CARLA, se revela que la fusión de imágenes RGB y mapas de profundidad para formar un mapa semántico de vista de pájaro (BEV) puede mejorar el rendimiento general. Como el módulo de percepción tiene una mejor comprensión general de la escena, el módulo del controlador puede aprovechar información útil para estimar los controles de navegación correctamente. Además, el equipo afirma que el modelo propuesto es preferible para la implementación, ya que logra una mejor capacidad de conducción con menos parámetros que otros modelos.
La investigación fue publicada en IEEE Transactions on Intelligent Vehicles , y el equipo está trabajando actualmente en modificaciones y mejoras al modelo para abordar varios problemas cuando se conduce en condiciones de poca iluminación, como de noche, con lluvia intensa, etc. Como hipótesis, el equipo cree que agregar un sensor que no se ve afectado por los cambios en el brillo o la iluminación, como LiDAR, mejorará las capacidades de comprensión de la escena del modelo y dará como resultado una mejor capacidad de conducción. Otra tarea futura es aplicar el modelo propuesto a la conducción autónoma en el mundo real. Nuevo modelo básico mejora la precisión para la interpretación de imágenes de teledetección