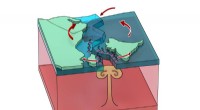
Una ilustración de intrincadas estructuras de flujo en turbulencia de una gran simulación realizada con 1, 024 nodos en Summit. El cuadro inferior derecho muestra una vista ampliada de una región de alta actividad. Crédito:Dave Pugmire y Mike Matheson, Laboratorio Nacional Oak Ridge
Turbulencia, el estado de movimiento fluido desordenado, es un rompecabezas científico de gran complejidad. La turbulencia impregna muchas aplicaciones en ciencia e ingeniería, incluida la combustión, transporte de contaminantes, predicción del tiempo, astrofísica, y más. Uno de los desafíos que enfrentan los científicos que simulan turbulencias radica en la amplia gama de escalas que deben capturar para comprender con precisión el fenómeno. Estas escalas pueden abarcar varios órdenes de magnitud y pueden ser difíciles de capturar dentro de las limitaciones de los recursos informáticos disponibles.
La informática de alto rendimiento puede hacer frente a este desafío cuando se combina con el código científico correcto; pero la simulación de flujos turbulentos en tamaños de problema más allá del estado actual de la técnica requiere un nuevo pensamiento en concierto con plataformas heterogéneas de primera línea.
Un equipo dirigido por P. K. Yeung, profesor de ingeniería aeroespacial e ingeniería mecánica en el Instituto de Tecnología de Georgia, realiza simulaciones numéricas directas (DNS) de turbulencia utilizando el nuevo código de su equipo, GPU para simulaciones de turbulencia a gran escala (GESTS). El DNS puede capturar con precisión los detalles que surgen de una amplia gama de escalas. A principios de este año, el equipo desarrolló un nuevo algoritmo optimizado para la supercomputadora IBM AC922 Summit en Oak Ridge Leadership Computing Facility (OLCF). Con el nuevo algoritmo, el equipo alcanzó un rendimiento de menos de 15 segundos de tiempo de reloj de pared por paso de tiempo para más de 6 billones de puntos de cuadrícula en el espacio, un nuevo récord mundial que supera el estado de la técnica anterior en el campo para el tamaño del problema.
Se espera que las simulaciones que realiza el equipo en Summit aclaren cuestiones importantes relacionadas con los flujos de fluidos turbulentos que se agitan rápidamente, lo que tendrá un impacto directo en el modelado de los flujos de reacción en motores y otros tipos de sistemas de propulsión.
GESTS es un código de dinámica de fluidos computacional en el Center for Accelerated Application Readiness en el OLCF, una instalación para usuarios de la Oficina de Ciencias del Departamento de Energía de EE. UU. en el Laboratorio Nacional de Oak Ridge del DOE. En el corazón de GESTS se encuentra un algoritmo matemático básico que calcula a gran escala, distribuidas transformadas rápidas de Fourier (FFT) en tres direcciones espaciales.
Una FFT es un algoritmo matemático que calcula la conversión de una señal (o un campo) de su dominio de tiempo o espacio original a una representación en el espacio de frecuencia (o número de onda) y viceversa para la transformada inversa. Yeung aplica ampliamente una gran cantidad de FFT para resolver con precisión la ecuación diferencial parcial fundamental de la dinámica de fluidos, la ecuación de Navier-Stokes, utilizando un enfoque conocido en matemáticas y computación científica como "métodos pseudoespectrales".
La mayoría de las simulaciones que utilizan un paralelismo masivo basado en CPU dividirán un dominio de solución 3-D, o el volumen de espacio donde se calcula el flujo de un fluido, a lo largo de dos direcciones en muchos "cuadros de datos largos", "o" lápices ". Sin embargo, cuando el equipo de Yeung se reunió en un Hackathon de la GPU de OLCF a finales de 2017 con el mentor David Appelhans, un miembro del personal de investigación de IBM, el grupo concibió una idea innovadora. Combinarían dos enfoques diferentes para abordar el problema. Primero dividirían el dominio 3-D en una dirección, formando una serie de "bloques" de datos en las CPU de gran memoria de Summit, luego, paralelice aún más dentro de cada losa utilizando las GPU de Summit.
El equipo identificó las partes de un código de CPU base que requieren más tiempo y se propuso diseñar un nuevo algoritmo que reduciría el costo de estas operaciones. empujar los límites del mayor tamaño de problema posible, y aprovechar las características únicas centradas en datos de Summit, la supercomputadora más poderosa e inteligente del mundo para la ciencia abierta.
"Diseñamos este algoritmo para que sea de paralelismo jerárquico para garantizar que funcione bien en un sistema jerárquico, "Appelhans dijo." Pusimos hasta dos losas en un nodo, pero como cada nodo tiene 6 GPU, rompimos cada bloque y colocamos esas piezas individuales en diferentes GPU ".
En el pasado, los lápices pueden haber sido distribuidos entre muchos nodos, pero el método del equipo hace uso de la comunicación en el nodo de Summit y su gran cantidad de memoria de CPU para adaptarse a bloques de datos completos en un solo nodo.
"Originalmente planeamos ejecutar el código con la memoria que reside en la GPU, lo que nos habría limitado a tamaños de problemas más pequeños, "Dijo Yeung." Sin embargo, en el OLCF GPU Hackathon, nos dimos cuenta de que la conexión NVLink entre la CPU y la GPU es tan rápida que podríamos maximizar el uso de los 512 gigabytes de memoria de la CPU por nodo ".
La realización llevó al equipo a adaptar algunas de las piezas principales del código (kernels) para el movimiento de datos de la GPU y el procesamiento asincrónico. lo que permite que la computación y el movimiento de datos ocurran simultáneamente. Los núcleos innovadores transformaron el código y permitieron al equipo resolver problemas mucho más grandes que nunca a un ritmo mucho más rápido que nunca.
El éxito del equipo demostró que incluso grandes, Las aplicaciones dominadas por la comunicación pueden beneficiarse enormemente de la supercomputadora más poderosa del mundo cuando los desarrolladores de código integran la arquitectura heterogénea en el diseño del algoritmo.
Coalesciendo en el éxito
Uno de los ingredientes clave para el éxito del equipo fue la combinación perfecta entre la experiencia científica de dominio de larga data del equipo de Georgia Tech y el pensamiento innovador y el conocimiento profundo de la máquina de Appelhans.
También fueron cruciales para el logro los sistemas Ascent y Summitdev de acceso temprano de la OLCF y una asignación de un millón de horas de nodo en Summit proporcionada por el programa Innovative Novel and Computational Impact on Theory and Experiment (INCITE), administrado conjuntamente por las instalaciones de computación de liderazgo de Argonne y Oak Ridge, y el Programa Summit Early Science en 2019.
Oscar Hernández, desarrollador de herramientas en la OLCF, ayudó al equipo a superar los desafíos a lo largo del proyecto. Uno de esos desafíos fue averiguar cómo ejecutar cada proceso paralelo único (que obedece al estándar de interfaz de paso de mensajes [MPI]) en la CPU junto con varias GPU. Típicamente, uno o más procesos MPI están vinculados a una sola GPU, pero el equipo descubrió que el uso de varias GPU por proceso MPI permite que los procesos MPI envíen y reciban un número menor de mensajes más grandes de lo que el equipo planeó originalmente. Usando el modelo de programación OpenMP, Hernández ayudó al equipo a reducir la cantidad de tareas de MPI, mejorando el rendimiento de la comunicación del código y, por lo tanto, conduciendo a más aceleraciones.
Kiran Ravikumar, un estudiante de doctorado de Georgia Tech en el proyecto, presentará detalles del algoritmo dentro del programa técnico de la Conferencia de Supercomputación 2019, SC19.
El equipo planea usar el código para hacer más incursiones en los misterios de la turbulencia; también introducirán otros fenómenos físicos como la mezcla oceánica y los campos electromagnéticos en el código en el futuro.
"Este código, y sus futuras versiones, proporcionará oportunidades interesantes para importantes avances en la ciencia de la turbulencia, con conocimientos de generalidad relacionados con la mezcla turbulenta en muchos entornos naturales y diseñados, "Dijo Yeung.