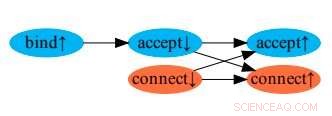
La relación sucede antes de aceptar y conectar llamadas al sistema que deriva de Box of Pain. Los colores indican diferentes hilos. Box of Pain es capaz de derivar que la conexión ↑ ocurre después de aceptar ↓, porque el segundo causa el primero. Crédito:Bittman, Miller y Alvaro.
En informática, Los sistemas distribuidos son sistemas con componentes ubicados en diferentes dispositivos, que se comunican entre sí. Si bien estos sistemas se han vuelto cada vez más comunes, normalmente están llenos de errores.
Algunos investigadores han intentado desarrollar herramientas para encontrar errores en sistemas distribuidos y eliminarlos, sin embargo, aún no ha surgido una solución tangible. En general, Las herramientas que 'perturban' las ejecuciones pueden probar qué tan robusto es un sistema ante fallas, mientras que las herramientas que "observan" las ejecuciones permiten a los investigadores comprender mejor los efectos de tales fallas en todo el sistema.
La mayoría de los enfoques y técnicas existentes para la detección y depuración de fallas están incompletos o se basan en pruebas, lo que significa que pueden ser útiles para encontrar errores pero no para eliminarlos. Consciente de esta brecha en la literatura, un equipo de investigadores de la UC Santa Cruz ha desarrollado recientemente una nueva técnica, llamado Caja de dolor, para el rastreo y la inyección de fallas en sistemas distribuidos no modificados.
"Nuestro laboratorio está obsesionado con la tolerancia a fallas, "Peter Alvaro, uno de los investigadores que realizó el estudio, dijo a TechXplore. "Sistemas distribuidos, es decir, sistemas que requieren la cooperación de una colección de computadoras independientes para cumplir su propósito, son omnipresentes, pero es muy difícil razonar sobre ellos, programar y depurar. Las técnicas de inyección de fallas pueden aumentar la confianza de que los sistemas distribuidos realmente pueden tolerar las fallas (por ejemplo, fallas de máquinas, particiones de red, etc.) que fueron diseñados para tolerar, mientras que la infraestructura de observabilidad (por ejemplo, rastreo) puede ayudarnos a comprender mejor cómo funcionan estos sistemas durante las fallas ".
El laboratorio de Álvaro se centra principalmente en un área de investigación llamada selección de experimentos, lo que implica elegir automáticamente las fallas que tienen más probabilidades de llevar un sistema a un mal estado. Él y sus colegas utilizan la infraestructura de rastreo para observar las ejecuciones, construya modelos de sistemas que produzcan trazas y luego use estos modelos para identificar fallas 'interesantes' para inyectar en un sistema.
"Desafortunadamente, nuestro enfoque asume que los sistemas ya están equipados con infraestructura de rastreo e inyección de fallas; para observar primero, y, en última instancia, perturbar la ejecución del sistema, "Dijo Álvaro." En la práctica, muchos sistemas no lo son, y agregar estas capacidades puede resultar costoso y llevar mucho tiempo. Nos preguntamos qué se necesitaría para poder realizar el rastreo y la inyección de fallas de forma transparente, en sistemas no modificados, para que podamos aplicar nuestros enfoques de búsqueda de errores a "cualquier" software distribuido. Box of Pain es donde finalmente aterrizamos ".
Caja de dolor el enfoque ideado por los investigadores de la UC Santa Cruz, es esencialmente un marco para rastrear un sistema informático complejo para comprender mejor su comportamiento, simule fallas dentro de él y observe qué sucede cuando algo sale mal. Por ejemplo, Box of Pain puede simular una red rota y comparar el comportamiento de los programas con su comportamiento en condiciones normales.
"Nuestra técnica hace esto mediante la observación de eventos clave en los comportamientos de los programas, como eventos de comunicación, choques y condiciones de salida, "Daniel Bittman, otro investigador involucrado en el estudio, explicado. "Con esta información, construye en vivo una comprensión de cómo interactúan las computadoras, permitiendo que el software de detección de errores automatizado experimente con la interrupción de los sistemas automáticamente ".
En contraste con otros sistemas de inyección de fallas, Box of Pain emplea un enfoque ligero para rastrear, centrándose en simular los efectos de fallas parciales en la comunicación en lugar de explorar las fallas en sí mismas. En su estudio, los investigadores evaluaron su técnica y encontraron que logró resultados muy prometedores, tanto en la observación de fallas como en la perturbación de sistemas distribuidos.
"Un hallazgo importante fue lo que pudimos hacer con nuestra visión algo limitada de un sistema informático complejo, ", Dijo Bittman." Dado que nuestro objetivo era comprender el comportamiento de un sistema de forma transparente (es decir, sin necesidad de realizar cambios en el sistema en estudio), la información que recopilamos al respecto es bastante genérica ".
Según Bittman, un primer paso clave en su investigación fue demostrar que podían reconstruir con éxito el patrón de comunicación de un sistema complejo con solo observar los eventos individuales de cada proceso y que esto se podía hacer en tiempo real. Esto es crucial porque los investigadores querían que su modelo de inyección de fallas les permitiera decirle a un sistema:'elimine toda comunicación entre el programa A y B después de que B envíe un mensaje a A'. Si no pudieron reconstruir el patrón de comunicación de un sistema hasta que terminó de ejecutarse, sin embargo, esta frase sería imposible de transmitir.
"Un segundo hallazgo importante fue la cantidad de formas en que la ejecución de un sistema en particular podría diferir mientras se logra el mismo resultado, ", Agregó Bittman." Varias computadoras que interactúan pueden funcionar a diferentes velocidades, y, por lo tanto, la forma en que interactúan puede ser diferente entre ejecuciones del mismo sistema con las mismas entradas, incluso si el resultado de la ejecución es el mismo. Esto tiene una consecuencia desafortunada:decidir cuándo inyectar una falla en un sistema se vuelve mucho más difícil. Sin embargo, pudimos proporcionar alguna evidencia inicial de que el problema, en la práctica, no es tan malo como podría parecer ".
Los resultados recogidos por Álvaro, Bittman y su colega Ethan Miller tienen implicaciones sustanciales para la inyección de fallas, ya que su enfoque podría facilitar la decisión y la realización de experimentos de inyección de fallas. Además, su estudio podría informar el desarrollo de marcos de depuración, que informaría a los desarrolladores con qué nivel de confianza su sistema está libre de errores en circunstancias particulares.
"Esta investigación acaba de comenzar, "Dijo Álvaro." De hecho, como admitimos fácilmente en el periódico, apenas hemos comenzado a usar Box of Pain con el propósito declarado de encontrar y aislar errores en sistemas distribuidos. Publicamos este primer informe porque estábamos emocionados de contarle a la comunidad sobre el desarrollo ".
Según Álvaro, Hay dos direcciones clave en las que su investigación podría desarrollarse más en un futuro próximo. Primeramente, aunque su estudio proporciona una tentadora evidencia inicial que respalda sus hipótesis, Es posible que los estudios futuros necesiten ejecutar más pruebas experimentales para evaluar más a fondo sus suposiciones.
"Argumentamos que un inyector de fallas distribuidas solo necesita enfocarse en los bordes perturbadores en el gráfico de comunicación de un sistema para encontrar los errores más interesantes, reduciendo masivamente el 'área de superficie' en la que debemos enfocarnos, "Explicó Álvaro." ¡Ahora tenemos que demostrar que esto es cierto encontrando algunos errores nuevos! Qué es más, sostenemos que aunque el espacio de ejecuciones 'posibles' es exponencialmente grande y difícil de cubrir, la probabilidad de diferentes ejecuciones (en el nivel de abstracción que capturamos en el gráfico de comunicación) cae muy abruptamente, haciendo posible cubrir la mayor parte de este espacio de manera eficiente ".
Para mostrar que el efecto que observaron es cierto y se puede generalizar en diferentes escenarios, los investigadores deberán ampliar sus experimentos a sistemas más grandes y ricos. A largo plazo, también prevén una estrecha integración de Box of Pain con un selector de experimentos dirigido, como la inyección de fallas impulsada por el linaje, ya que esto podría ayudar a generalizar este selector a infraestructuras distribuidas arbitrarias.
"Durante los próximos seis meses, nuestro laboratorio planea experimentar con almacenes de datos como Cassandra, Redis y MongoDB, en colas de mensajes como Kafka y RabbitMQ, y en servicios de coordinación como EtcD y Zookeeper, "Agregó Álvaro." También planeamos explorar aplicaciones pedagógicas de Box of Pain, elegir programas personalizados de inyección de fallas para proyectos presentados por estudiantes en el curso de sistemas distribuidos de UC Santa Cruz. De esta manera, puede ayudar a los instructores a calificar los proyectos de los estudiantes, así como ayudar a los estudiantes brindándoles explicaciones detalladas de cualquier error que identifique en sus programas ".
El estudio realizado por Álvaro, Bittman and Miller fue prepublicado en arXiv y ha sido aceptado para su publicación por HotCloud 2019, un taller sobre computación en la nube que tendrá lugar en julio en Renton, Washington. Este taller será una gran oportunidad para solicitar comentarios sobre Box of Pain de la comunidad de sistemas distribuidos, lo que podría ayudar a los investigadores a determinar qué vías de trabajo futuro deberían seguir primero.
© 2019 Science X Network