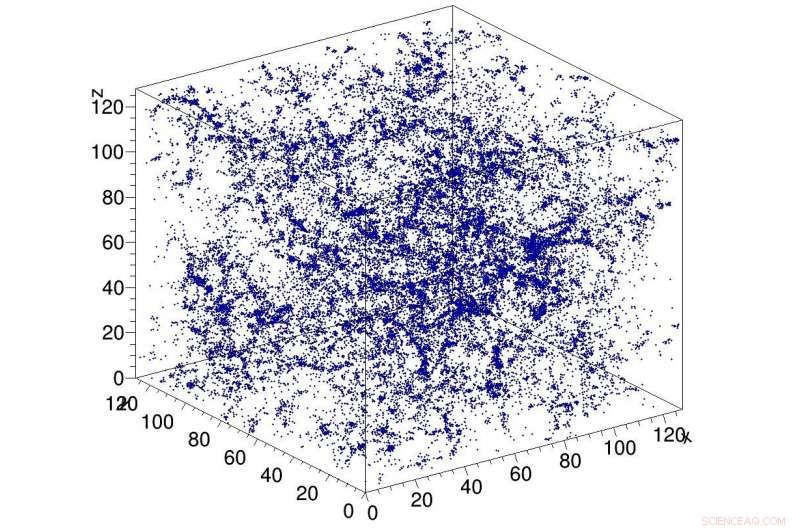
Ejemplo de simulación de materia oscura en el universo, utilizado como entrada a la red CosmoFlow. CosmoFlow es la primera aplicación científica a gran escala que utiliza el marco TensorFlow en una plataforma informática de alto rendimiento basada en CPU con entrenamiento sincrónico. Crédito:Laboratorio Nacional Lawrence Berkeley
Una colaboración de Big Data Center entre científicos computacionales del Centro Nacional de Computación Científica de Investigación Energética (NERSC) del Laboratorio Nacional Lawrence Berkeley (Berkeley Lab) e ingenieros de Intel y Cray ha dado como resultado otra primicia en la búsqueda para aplicar el aprendizaje profundo a la ciencia intensiva en datos:CosmoFlow , la primera aplicación científica a gran escala que utiliza el marco TensorFlow en una plataforma informática de alto rendimiento basada en CPU con entrenamiento sincrónico. También es el primero en procesar volúmenes de datos espaciales tridimensionales (3-D) a esta escala, dando a los científicos una plataforma completamente nueva para obtener una comprensión más profunda del universo.
Los problemas de "macrodatos" cosmológicos van más allá del simple volumen de datos almacenados en el disco. Las observaciones del universo son necesariamente finitas, y el desafío al que se enfrentan los investigadores es cómo extraer la mayor cantidad de información de las observaciones y simulaciones disponibles. Para agravar el problema, los cosmólogos suelen caracterizar la distribución de la materia en el universo utilizando medidas estadísticas de la estructura de la materia en forma de funciones de dos o tres puntos u otras estadísticas reducidas. Los métodos como el aprendizaje profundo que pueden capturar todas las características en la distribución de la materia proporcionarían una mayor comprensión de la naturaleza de la energía oscura. Los primeros en darse cuenta de que el aprendizaje profundo podría aplicarse a este problema fueron Siamak Ravanbakhsh y sus colegas, como se menciona en las actas de la 33ª Conferencia Internacional sobre Aprendizaje Automático. Sin embargo, Los cuellos de botella computacionales al escalar la red y el conjunto de datos limitaban el alcance del problema que podía abordarse.
Motivado para abordar estos desafíos, CosmoFlow fue diseñado para ser altamente escalable; para procesar grandes, Conjuntos de datos de cosmología 3-D; y para mejorar el rendimiento del entrenamiento de aprendizaje profundo en supercomputadoras HPC modernas, como la supercomputadora Cray XC40 Cori basada en el procesador Intel en NERSC. CosmoFlow se basa en el popular marco de aprendizaje automático de TensorFlow y utiliza Python como interfaz. La aplicación aprovecha el complemento de aprendizaje automático Cray PE para lograr un escalado sin precedentes del marco de aprendizaje profundo de TensorFlow a más de 8, 000 nodos. También se beneficia de la tecnología de aceleración de E / S DataWarp de Cray, que proporciona el rendimiento de E / S necesario para alcanzar este nivel de escalabilidad.
En un documento técnico que se presentará en SC18 en noviembre, El equipo de CosmoFlow describe la aplicación y los experimentos iniciales utilizando simulaciones de cuerpos N de materia oscura producidas utilizando los paquetes MUSIC y pycola en la supercomputadora Cori en NERSC. En una serie de experimentos de escalado de un solo nodo y de varios nodos, el equipo pudo demostrar un entrenamiento paralelo de datos completamente síncrono en 8, 192 de Cori con 77% de eficiencia en paralelo y 3,5 Pflop / s de rendimiento sostenido.
"Nuestro objetivo era demostrar que TensorFlow puede ejecutarse a escala en varios nodos de manera eficiente, "dijo Deborah Bard, arquitecto de big data en NERSC y coautor del artículo técnico. "Por lo que sabemos, esta es la implementación más grande de TensorFlow en CPU, y creemos que es el intento más grande de ejecutar TensorFlow en la mayor cantidad de nodos de CPU ".
Temprano, El equipo de CosmoFlow estableció tres objetivos principales para este proyecto:ciencia, optimización y escalado de un solo nodo. El objetivo científico era demostrar que el aprendizaje profundo se puede utilizar en volúmenes 3-D para aprender la física del universo. El equipo también quería asegurarse de que TensorFlow se ejecutara de manera eficiente y efectiva en un solo nodo de procesador Intel Xeon Phi con volúmenes 3-D, que son comunes en la ciencia pero no tanto en la industria, donde la mayoría de las aplicaciones de aprendizaje profundo se ocupan de conjuntos de datos de imágenes 2-D. Y finalmente, garantizar una alta eficiencia y rendimiento cuando se escala en miles de nodos en el sistema de supercomputadora Cori.
Como Joe Curley, Director sénior de la Organización de Modernización de Código en el Grupo de Centros de Datos de Intel, señalado, "La colaboración del Big Data Center ha producido resultados asombrosos en informática gracias a la combinación de la tecnología Intel y los esfuerzos de optimización de software dedicados. Durante el proyecto CosmoFlow, identificamos el marco, Optimización del kernel y la comunicación que condujo a un aumento de rendimiento de más de 750 veces para un solo nodo. Igual de impresionante, el equipo resolvió problemas que limitaban el escalado de las técnicas de aprendizaje profundo a 128 a 256 nodos, para permitir ahora que la aplicación CosmoFlow escale de manera eficiente al 8, 192 nodos de la supercomputadora Cori en NERSC ".
"Estamos entusiasmados con los resultados y los avances en aplicaciones de inteligencia artificial de este proyecto de colaboración con NERSC e Intel, "dijo Per Nyberg, vicepresidente de desarrollo de mercado, inteligencia artificial y nube en Cray. "Es emocionante ver al equipo de CosmoFlow aprovechar la tecnología Cray única y aprovechar el poder de una supercomputadora Cray para escalar de manera efectiva los modelos de aprendizaje profundo. Es un gran ejemplo de lo que muchos de nuestros clientes buscan en la convergencia del modelado tradicional y simulación con nuevos algoritmos de análisis y aprendizaje profundo, todo en un solo, plataforma escalable ".
Prabhat, Líder del grupo de servicios de datos y análisis en NERSC, adicional, "Desde mi perspectiva, CosmoFlow es un proyecto ejemplar para la colaboración del Big Data Center. Realmente hemos aprovechado las competencias de varias instituciones para resolver un problema científico difícil y mejorar nuestra pila de producción, lo que puede beneficiar a la comunidad más amplia de usuarios de NERSC ".
Además de Bard y Prabhat, los coautores del artículo de SC18 incluyen a Amrita Mathuriya, Lawrence Meadows, Lei Shao, Tuomas Karna, John Pennycook, Jason Sewall, Nalini Kumar y Victor Lee de Intel; Peter Mendygral, Diana Moise, Kristyn Maschhoff y Michael Ringenburg de Cray; Siyu He y Shirley Ho del Instituto Flatiron; y James Arnemann de UC Berkeley.