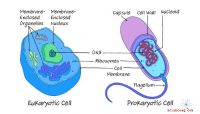
El dogma central de la biología molecular explica que el flujo de información para los genes es del código genético del ADN a una copia intermedia del ARN y luego a las proteínas sintetizadas a partir del código. Las ideas clave subyacentes al dogma fueron propuestas por primera vez por el biólogo molecular británico Francis Crick en 1958. En 1970 se hizo comúnmente aceptado que el ARN hizo copias de genes específicos de la doble hélice del ADN original y luego formó la base para el producción de proteínas a partir del código copiado. El proceso de copiar genes mediante la transcripción del código genético y producir proteínas a través de la traducción del código en cadenas de aminoácidos se denomina expresión de genes El descubrimiento de splicing alternativo La información codificada en las proteínas no puede influir en el código original del ADN. La transcripción del ADN tiene lugar en el núcleo La hélice de ADN que codifica la información genética del organismo se encuentra en el núcleo de las células eucariotas. Las células procariotas son células que no tienen núcleo, por lo que la transcripción del ADN, la traducción y la síntesis de proteínas tienen lugar en el citoplasma de la célula mediante un proceso de transcripción /traducción similar (pero más simple). En las células eucariotas, las moléculas de ADN no pueden abandonar el núcleo, por lo que las células tienen que copiar el código genético para sintetizar proteínas en la célula fuera del núcleo. El proceso de copia de la transcripción lo inicia una enzima llamada RNA polymerase Copia. La ARN polimerasa viaja a lo largo de las cadenas de ADN y hace una copia de un gen en una de las cadenas. Empalme. Las cadenas de ADN contienen secuencias codificantes de proteínas llamadas exones La secuencia de ADN copiada en la segunda etapa contiene los exones e intrones y es un precursor del ARN mensajero. Para eliminar los intrones, la hebra pre-mRNA Las proteínas son largas cadenas de aminoácidos unidas por enlaces peptídicos. Son responsables de influir en el aspecto de una célula y en lo que hace. Forman estructuras celulares y juegan un papel clave en el metabolismo. Actúan como enzimas y hormonas y están incrustadas en las membranas celulares para facilitar la transición de moléculas grandes. La secuencia de la cadena de aminoácidos para una proteína está codificada en la hélice de ADN. El código se compone de las siguientes cuatro bases nitrogenadas : Estas son bases nitrogenadas, y cada enlace en la cadena de ADN está formado por un par de bases. La guanina forma un par con citosina y la adenina forma un par con timina. Los enlaces reciben nombres de una letra según la base que aparezca primero en cada enlace. Los pares de bases se denominan G, C, A y T para los enlaces guanina-citosina, citosina-guanina, adenina-timina y timina-adenina. Tres pares de bases representan un código para un aminoácido particular y son llamado codón Hay aproximadamente 20 aminoácidos que se usan en la síntesis de proteínas, y también hay codones para señales de inicio y parada. Como resultado, hay suficientes codones para definir una secuencia de aminoácidos para cada proteína con algunas redundancias. El ARNm es una copia del código para una proteína. Las proteínas son producidas por ribosomas Cuando el ARNm abandona el núcleo, busca un ribosoma Los ribosomas son las fábricas de la célula que producen el Proteínas de la célula. Están formados por una pequeña parte que lee el ARNm y una parte más grande que ensambla los aminoácidos en la secuencia correcta. El ribosoma está formado por ARN ribosómico y proteínas asociadas. Los ribosomas se encuentran flotando en el citosol de la célula Si los ribosomas unidos al ER producen una proteína, la proteína se envía fuera de la membrana celular para ser utilizada en otro lugar. Las células que secretan hormonas y enzimas generalmente tienen muchos ribosomas unidos al ER y producen proteínas para uso externo. El ARNm se une a un ribosoma y puede comenzar la traducción del código a la proteína correspondiente. Flotando en el citosol celular hay aminoácidos y pequeñas moléculas de ARN llamadas ARN de transferencia Cuando el ribosoma lee el código de ARNm, selecciona una molécula de ARNt para transferir el aminoácido correspondiente al ribosoma. El ARNt lleva una molécula del aminoácido especificado al ribosoma, que une la molécula en la secuencia correcta a la cadena de aminoácidos. La secuencia de eventos es la siguiente: Algunas proteínas se producen en lotes mientras que otras se sintetizan continuamente para Satisfacer las necesidades actuales de la célula. Cuando el ribosoma produce la proteína, el flujo de información del dogma central del ADN a la proteína se completa. Las alternativas al flujo directo de información previsto en el dogma central se han producido recientemente. sido estudiado En el empalme alternativo, el pre-ARNm se corta para eliminar intrones, pero la secuencia de exones en la cadena de ADN copiada se cambia. Esto significa que una secuencia de código de ADN puede dar lugar a dos proteínas diferentes. Si bien los intrones se descartan como secuencias genéticas no codificantes, pueden influir en la codificación de exones y pueden ser una fuente de genes adicionales en ciertas circunstancias. Si bien el dogma central de la biología molecular sigue siendo válido en lo que respecta al flujo de información , los detalles de cómo fluye exactamente la información del ADN a las proteínas es menos lineal de lo que se pensaba originalmente.
. Dependiendo de la célula y algunos factores ambientales, ciertos genes se expresan mientras que otros permanecen inactivos. La expresión génica se rige por señales químicas entre las células y los órganos de los organismos vivos.
y el estudio de partes no codificantes de ADN llamadas intrones
indican que el proceso descrito por el dogma central de la biología es más complicado de lo que se suponía inicialmente. La secuencia simple de ADN a ARN a proteína tiene ramas y variaciones que ayudan a los organismos a adaptarse a un entorno cambiante. El principio básico de que la información genética se mueve solo en una dirección, del ADN al ARN a las proteínas, permanece sin respuesta.
y tiene las siguientes etapas:
, y las secuencias que no se usan en la producción de proteínas se llaman intrones
. Dado que el propósito del proceso de transcripción es producir ARN para la síntesis de proteínas, la parte intrón del código genético se descarta mediante un mecanismo de empalme.
se corta en una interfaz intrón /exón. La parte del intrón del filamento forma una estructura circular y abandona el filamento, permitiendo que los dos exones de cada lado del intrón se unan. Cuando se completa la eliminación de los intrones, la nueva cadena de ARNm es ARNm maduro
, y está lista para abandonar el núcleo.
El ARNm tiene una copia del código para una proteína
. Un codón típico podría llamarse GGA o ATC. Debido a que cada uno de los tres lugares de codones para un par de bases puede tener cuatro configuraciones diferentes, el número total de codones es 4 3 o 64.
para sintetizar la proteína para la cual tiene las instrucciones codificadas.
o unidos al retículo endoplásmico de la célula
(ER), Una serie de sacos encerrados en la membrana que se encuentran cerca del núcleo. Cuando los ribosomas flotantes producen proteínas, las proteínas se liberan en el citosol celular.
La traducción ensambla una proteína específica de acuerdo con el código de ARNm
o ARNt. Hay una molécula de ARNt para cada tipo de aminoácido utilizado para la síntesis de proteínas.
.
Empalme alternativo y los efectos de los intrones