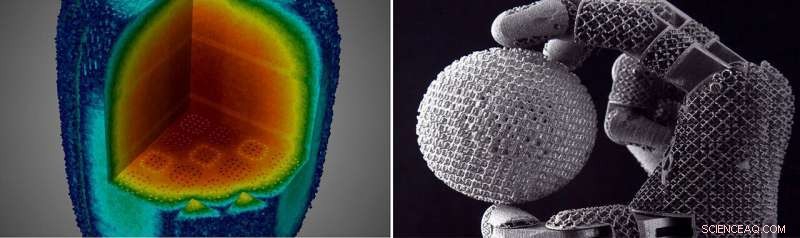
Las computadoras a exaescala se utilizarán para resolver problemas en una amplia gama de aplicaciones científicas, incluso para simular las operaciones de vida útil de pequeños reactores nucleares modulares (izquierda) y comprender la compleja relación entre los procesos de impresión 3D y las propiedades del material (derecha). Crédito:Laboratorio Nacional de Oak Ridge
Se espera que pronto debuten las computadoras a exaescala, incluyendo Frontier en la Instalación de Computación de Liderazgo de Oak Ridge (OLCF) del Departamento de Energía de EE. UU. (DOE) y Aurora en la Instalación de Computación de Liderazgo de Argonne (ALCF), ambas instalaciones para usuarios de la Oficina de Ciencias del DOE, en 2021. Se prevé que estos sistemas informáticos de próxima generación superen la velocidad de las supercomputadoras más potentes de la actualidad entre cinco y diez veces. Este aumento de rendimiento permitirá a los científicos abordar problemas que de otro modo serían irresolubles en términos de complejidad y tiempo de cálculo.
Pero alcanzar un nivel de rendimiento tan alto requerirá adaptaciones de software. Por ejemplo, OpenMP:las interfaces de programación de aplicaciones estándar para la computación paralela de memoria compartida, o el uso de múltiples procesadores para completar una tarea, tendrá que evolucionar para admitir la superposición de diferentes memorias, aceleradores de hardware como unidades de procesamiento de gráficos (GPU), Varias arquitecturas informáticas de exaescala, y los últimos estándares para C ++ y otros lenguajes de programación.
Evolución de OpenMP hacia exaescala con el proyecto SOLLVE
En septiembre de 2016, el DOE Exascale Computing Project (ECP) financió un proyecto de desarrollo de software llamado SOLLVE (para escalar OpenMP a través de una máquina virtual de bajo nivel para un rendimiento y portabilidad a exaescala) para ayudar con esta transición. El equipo del proyecto SOLLVE, dirigido por el Laboratorio Nacional Brookhaven del DOE y compuesto por colaboradores de Argonne del DOE, Lawrence Livermore, y Oak Ridge National Labs, y Georgia Tech:ha estado diseñando implementar, y estandarizar las funcionalidades clave de OpenMP que los desarrolladores de aplicaciones de ECP han identificado como importantes.
Impulsado por SOLLVE y patrocinado por ECP, La Iniciativa de Ciencias Computacionales (CSI) de Brookhaven Lab organizó un hackathon OpenMP de cuatro días del 29 de abril al 2 de mayo, organizado conjuntamente con Oak Ridge e IBM. El hackathon OpenMP es el último de una serie de hackathons ofrecidos por CSI, incluidos los que se centran en las GPU NVIDIA y los procesadores Intel Xeon Phi de muchos núcleos.
"OpenMP está experimentando cambios sustanciales para abordar los requisitos de los próximos sistemas informáticos de exaescala, "dijo el coordinador del evento local Martin Kong, un científico computacional en el Grupo de Ciencias de la Computación y Matemáticas de CSI y el representante de Brookhaven Lab en la Junta de Revisión de Arquitectura de OpenMP, que supervisa la especificación estándar OpenMP. "Portar códigos científicos al nuevo hardware y arquitecturas de exaescala será un gran desafío. La principal motivación de este hackathon es la participación de las aplicaciones:interactuar más profundamente con diferentes usuarios, especialmente los de los laboratorios del DOE, y hacerlos conscientes de los cambios que deben esperar en OpenMP y cómo estos cambios pueden beneficiar sus aplicaciones científicas ".

La supercomputadora Summit. Crédito:Laboratorio Nacional de Oak Ridge
Sentar las bases para la portabilidad del rendimiento de las aplicaciones
Científicos computacionales y de dominio, desarrolladores de código, y expertos en hardware informático de Brookhaven, Argonne, Lawrence Berkeley, Lawrence Livermore, Cresta de roble, Georgia Tech, Universidad de Indiana, Universidad de Rice, Universidad de Illinois en Urbana-Champaign, IBM, y la Administración Nacional de Aeronáutica y del Espacio (NASA) participaron en el hackathon. Los ocho equipos fueron guiados por el laboratorio nacional, Universidad, y mentores de la industria que fueron seleccionados en función de su amplia experiencia en la programación de GPU, participando en el Comité de Idiomas de OpenMP, y realizar investigación y desarrollo de herramientas que admitan las últimas especificaciones de OpenMP.
Durante la semana, los equipos trabajaron para trasladar sus aplicaciones científicas de unidades centrales de procesamiento (CPU) a GPU y optimizarlas con la última versión de OpenMP (4.5+). Entre sesiones de piratería, los equipos tenían tutoriales sobre varias funciones avanzadas de OpenMP, incluida la programación del acelerador, herramientas de elaboración de perfiles para evaluar el rendimiento, y estrategias de optimización de aplicaciones.
Algunos equipos también utilizaron las últimas funcionalidades de OpenMP para programar CPU IBM Power9 aceleradas con GPU NDIVIA. La supercomputadora más rápida del mundo, la supercomputadora Summit en OLCF, se basa en esta nueva arquitectura, con más de 9000 CPU IBM Power9 y más de 27, 000 GPU NVIDIA.
Dar pasos hacia la exaescala
Las aplicaciones de los equipos abarcaron muchas áreas, incluida la física nuclear y de altas energías, láseres y ópticas, ciencia de los Materiales, sistemas autónomos, y mecánica de fluidos.
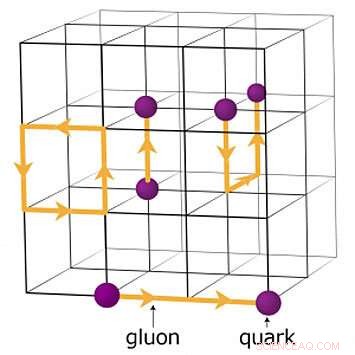
Un esquema de la red para cálculos de cromodinámica cuántica. Los puntos de intersección en la cuadrícula representan valores de quark, mientras que las líneas entre ellos representan valores de gluones. Crédito:Laboratorio Nacional Brookhaven
El participante David Wagner de la Incubadora de Computación de Alto Rendimiento del Centro de Investigación Langley de la NASA y sus colegas Gabriele Jost y Daniel Kokron del Centro de Investigación Ames de la NASA vinieron con un código para simular la elasticidad. Su objetivo en el hackathon era aumentar la instrucción única, paralelismo de datos múltiples (SIMD), un tipo de computación en el que varios procesadores realizan la misma operación en muchos puntos de datos simultáneamente, y optimizan la velocidad a la que los datos se pueden leer y almacenar en la memoria.
"Los científicos de la NASA están tratando de comprender cómo y por qué fallan los materiales de las aeronaves y naves espaciales, ", dijo Wagner." Necesitamos asegurarnos de que estos materiales sean lo suficientemente duraderos para resistir todas las fuerzas que están presentes en el uso normal durante el servicio. En el hackathon estamos trabajando en una mini aplicación que es representativa de las partes más intensivas en computación del programa más grande para modelar lo que sucede físicamente cuando se cargan los materiales, doblado, y estirado. Nuestro código tiene muchas fórmulas pequeñas que deben ejecutarse miles de millones de veces. El desafío es realizar todos los cálculos muy rápido ".
Según Wagner, Una de las razones por las que la NASA está impulsando esta capacidad computacional ahora es para comprender los procesos utilizados para generar piezas fabricadas aditivamente (impresas en 3-D) y las diferentes propiedades de los materiales de estas piezas. que se utilizan cada vez más en aviones. Conocer esta información es importante para garantizar la seguridad, fiabilidad, y durabilidad de los materiales durante su vida útil.
"El hackathon fue un éxito para nosotros, ", dijo Wagner." Tenemos nuestro código configurado para una ejecución masiva en paralelo y funcionando correctamente en el hardware de la GPU. Continuaremos con la depuración y el ajuste del rendimiento en paralelo, ya que esperamos tener pronto el hardware y el software adecuados de la NASA ".
Otro equipo adoptó un enfoque similar al intentar que OpenMP funcione para una pequeña parte de su código, un código de cromodinámica cuántica de celosía (QCD) que se encuentra en el centro de un proyecto de ECP llamado Lattice QCD:Lattice Quantum Chromodynamics for Exascale. Lattice QCD es un marco numérico para simular las interacciones fuertes entre partículas elementales llamadas quarks y gluones. Estas simulaciones son importantes para muchos problemas de física nuclear y de alta energía. Las simulaciones típicas requieren meses de ejecución en supercomputadoras.
"Nos gustaría que nuestro código se ejecutara en diferentes arquitecturas de exaescala, "dijo el miembro del equipo y científico computacional Meifeng Lin, subdirector de grupo del nuevo Grupo de Computación Cuántica de CSI y coordinador local de hackatones anteriores. "Ahora, el código se ejecuta en las GPU de NVIDIA, pero se espera que las próximas computadoras de exaescala tengan al menos dos arquitecturas diferentes. Esperamos que al usar OpenMP, que es compatible con los principales proveedores de hardware, podremos portar nuestro código más fácilmente a estas plataformas emergentes. Pasamos los primeros dos días del hackathon tratando de que OpenMP descargue el código de la CPU a la GPU en toda la biblioteca. sin mucho éxito ".

John Mellor-Crummey da una presentación sobre HPCToolkit, un conjunto integrado de herramientas para medir y analizar el rendimiento del programa en sistemas que van desde computadoras de escritorio hasta supercomputadoras. Crédito:Laboratorio Nacional Brookhaven
Mentor Lingda Li, investigador asociado de CSI y miembro del proyecto SOLLVE, ayudó a Lin y a su compañero de equipo Chulwoo Jung, un físico del Grupo de Teoría de Altas Energías de Brookhaven, con la descarga de OpenMP.
Aunque el equipo pudo hacer que OpenMP funcionara con unos cientos de líneas de código, su desempeño inicial fue pobre. Utilizaron varias herramientas de generación de perfiles de rendimiento para determinar qué estaba causando la desaceleración. Con esta información, pudieron hacer un progreso fundamental en su estrategia de optimización general, incluida la resolución de problemas relacionados con la descarga inicial de la GPU y la simplificación del mapeo de datos.
Entre las herramientas de elaboración de perfiles disponibles para los equipos en el hackathon se encontraba una desarrollada por Rice University y University of Wisconsin.
"Nuestra herramienta mide el rendimiento de los códigos acelerados por GPU tanto en el host como en la GPU, "dijo John Mellor-Crummey, profesor de ciencias de la computación e ingeniería eléctrica e informática en la Universidad de Rice e investigador principal en el correspondiente proyecto ECP Ampliación de HPCToolkit para medir y analizar el rendimiento del código en plataformas a exaescala. "Lo hemos estado usando en varios códigos de simulación esta semana para observar el rendimiento relativo de la computación y el movimiento de datos dentro y fuera de las GPU. Podemos decir no solo cuánto tiempo se está ejecutando un código, sino también cuántas instrucciones se ejecutaron y si la ejecución fue a toda velocidad o estancada, y si se estanca, por qué. También identificamos problemas de mapeo con la información del compilador que asocia el código máquina y el código fuente ".
Otros mentores de IBM estuvieron disponibles para mostrar a los equipos cómo utilizar los compiladores IBM XL, que están diseñados para explotar todo el poder de los procesadores IBM Power, y ayudarlos a superar cualquier problema que encuentren.
"Los compiladores son herramientas que los científicos utilizan para traducir su software científico en código que se puede leer mediante hardware, por las supercomputadoras más grandes del mundo:Summit y Sierra [en Lawrence Livermore], "dijo Doru Bercea, miembro del personal de investigación del Grupo de tecnologías de compilación avanzada en el Centro de investigación IBM TJ Watson. "El hackathon nos brinda la oportunidad de discutir las decisiones de diseño del compilador para que OpenMP funcione mejor para los científicos".
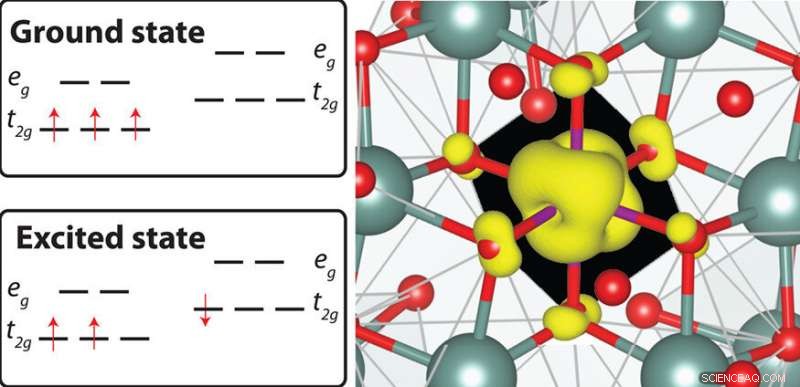
QMCPack se puede utilizar para calcular las energías de tierra y estado excitado de defectos localizados en aisladores y semiconductores, por ejemplo, en manganeso (Mn) 4+ -fósforos dopados, que son materiales prometedores para mejorar la calidad del color y la luminosidad de los diodos emisores de luz blanca. Crédito:Laboratorio Nacional Brookhaven
Según el mentor Johannes Doerfert, un becario postdoctoral en ALCF, las aplicaciones que los equipos trajeron al hackathon se encontraban en varias etapas en términos de su preparación para los próximos sistemas informáticos.
"Algunos equipos se enfrentan a problemas de portabilidad, algunos están luchando con los compiladores, y algunos tienen problemas de rendimiento de la aplicación, "explicó Doerfert." Como mentores, recibimos preguntas provenientes de cualquier parte de este amplio espectro ".
Algunas de las otras aplicaciones científicas que trajeron los equipos incluyen un código (pf3d) para simular las interacciones entre láseres de alta intensidad y plasma (gas ionizado) en experimentos en la Instalación Nacional de Ignición de Lawrence Livermore, y un código para calcular la estructura electrónica de los átomos, moléculas, y sólidos (QMCPack, también un proyecto ECP). Otro equipo de ECP trajo un entorno de programación portátil (RAJA) para el lenguaje de programación C ++.
"Estamos desarrollando una abstracción de alto nivel llamada RAJA para que las personas puedan usar cualquier marco de hardware o software que esté disponible en el backend de sus sistemas informáticos. "dijo el mentor Tom Scogland, becario postdoctoral en el Centro de Computación Científica Aplicada en Lawrence Livermore. "RAJA apunta principalmente a OpenMP en el host y CUDA [otro modelo de programación de computación paralela] en el backend. Pero queremos que RAJA funcione con otros modelos de programación en el backend, incluido OpenMP ".
"El tema del hackathon fue OpenMP 4.5+, una versión en evolución y no completamente madura, "explicó Kong." Los equipos se fueron con una mejor comprensión de las nuevas funciones de OpenMP, conocimiento sobre las nuevas herramientas que están disponibles en Summit, y una hoja de ruta a seguir a largo plazo ".
"Aprendí varias cosas sobre OpenMP 4.5, "dijo Steve Langer, miembro del equipo de pf3d, físico computacional en Lawrence Livermore. "El mayor beneficio fueron las discusiones con mentores y empleados de IBM. Ahora sé cómo empaquetar mis directivas de descarga OpenMP para usar las GPU NVIDIA sin tener limitaciones de memoria".














